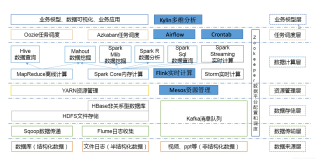
背景:
Spark 2.3.0 开始支持使用k8s 作为资源管理原生调度spark。使 用k8s原生调度的spark主要有以下好处:
采用k8s原生调度,不再需要二级调度,直接使用k8s原生的调度模块,实现与其他应用的混布;
资源隔离:任务可以提交到指定的namespace,这样可以复用k8s原生的qouta限制,实现任务资源的限制;
资源分配:可以指定每个spark任务的指定资源限制,任务之间更加隔离;
用户自定义:用户可以在spark基础镜像中打上自己的application, 更加灵活和方便;
试用条件:
一个k8s 1.7版本以上的集群,由于spark on k8s 任务提交后实际上在集群中是以custom resources和custom controller的形式,故你需要一个1.7+版本的k8s集群,同时需要启动k8s dns和RBAC。
下载spark2.3.0版本https://www.apache.org/dyn/closer.lua/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz
试用步骤:
制作镜像:
以下为基础镜像,包含了spark和官方exemples,本文的试用使用的是该官方的exemple。
cd /path/to/spark-2.3.0-bin-hadoop2.7
docker build -t <your.image.hub/yourns>/spark:2.3.0 -f kubernetes/dockerfiles/spark/Dockerfile .
docker push <your.image.hub/yourns>/spark:2.3.0
用户可以将自己的application和该基础镜像打在一起,并设置启动main class以及application的路径就可以实现用户application的任务提交。
任务提交:
bin/spark-submit \
--master k8s://<k8s apiserver address> \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image=<your.image.hub/yourns>/spark:2.3.0 \
local:///opt/spark/examples/jars/spark-examples_2.11-2.3.0.jar
更多默认的参数配置请参考:1.spark running on k8s
注意以下坑:
spark 自带的exemples是用jdk1.8编译的,如果启动过程中提示Unsupported major.minor version 52.0请更换jdk版本;
spark-submit默认会去~/.kube/config去加载集群配置,故请将k8s集群config放在该目录下;
spark driver 启动的时候报错Error: Could not find or load main class org.apache.spark.examples.SparkPi
spark 启动参数的local://后面应该跟你自己的spark application在容器里的路径;
spark driver 启动抛异常Caused by: java.net.UnknownHostException: kubernetes.default.svc: Try again, 请保证 k8d let节点间网络互通;
spark driver 启动抛异常system: serviceaccount: default: default" cannot get pods in the namespace "default, 权限问题,执行一下两条命令:
kubectl create rolebinding default-view --clusterrole=view --serviceaccount=default:default --namespace=defalut 和
kubectl create rolebinding default-admin --clusterrole=admin --serviceaccount=default:default --namespace=default 后就可以了
任务执行:
spark demo跑了起来后,可以看到spark-submit相当于起了一个controller, 用于管理单个spark任务,首先会创建该任务的service和driver,待driver运行后,会启动exeuctor,个数为--conf spark.executor.instances=5 指定的参数,待执行完毕后,submit会自动删除exeuctor, driver会用默认的gc机制清理。
Reference:
spark running on k8s
issue #34377
本文转自CSDN-Spark on k8s 试用步骤