本文是才云科技(CaiCloud)5月6日沙龙“Kubernetes Meetup 中国 2017”才云的 首席架构师唐鹏程的演讲实录。

大家下午好,我是才云科技的唐鹏程,今天演讲的题目是《Monitoring Kubernetes cluster with prometheus》,我知道在坐很多人已经在实际应用 Kubernetes 了,并且在各个业务部门的应用容器化之后,已经可以在 K8S 里面正常运行。在正常运行之后,公司内部就需要一些运维团队对整个系统的应用进行相关维护。一旦出现问题可以进行相应的操作,而这时候我们就需要一个监控系统。

我们来思考一下为什么需要这样一款监控系统,首先运维人员不可能一直盯着机器,你需要监控面板告诉你系统的运行状态,比如说我这个K8 集群里面每个节点 CPU 的利用率,或者我的应用上 API 调用的延迟是多少?这些都可以从监控图很轻松得到。
当机器或者应用出问题的时候,监控系统会为我们提供方向。比如我们突然从监控图上看到 Web 服务的 API 调用响应延迟变高了,又或者我们看到这个应用运行的这个节点 CPU 占用率很高,那就可以有一个大胆的猜测,是不是 CPU 数量不够,这样我们就能有大方向的指导,虽然不一定完全正确。
当然,监控系统虽然给我们提供了监控图,运维人员在实际应用过程中也不可能每天盯着这个图。那我们就需要监控系统会提供一些报警的功能,比如机器 CPU 过高,可以给我们的运维人员发送提示信息。

那这样的监控系统需要提供什么东西呢?他首先需要定义一个数据结构,我们知道这些机器或者应用的监控数据没有统一的格式,比如应用直接会打出来一些日志,又或者有一些输出监控数据的接口,那监控系统就需要提供一些统一的数据模型,这也是数据监控的基础。
我们既然有这么多的监控数据,那监控系统就需要定位一个统一的收集方式,怎么来收集这些监控数据。然后要考虑怎么存这些数据是最高效的,最后当我拿到了这些数据之后,我们需要用这些数据绘制监控图,那这个时候监控系统还是要提供一个查询的接口。这是我认为监控系统需要定义的一些东西。

回到我们今天的主题,我们知道目前市面上有很多监控组件,但今天我们将重点介绍 Prometheus 。它最早是借鉴了 Google 的 Borgmon 系统,完全是开源的,也是CNCF 下继 K8S 之后第二个项目。它们的开发人员都是原 Google 的 SRE,通过 HTTP 的方式来做数据收集,对其最深远的应该是其被设计成一个 self sustained 的系统,也就是说它是完全独立的系统,不需要外部依赖。
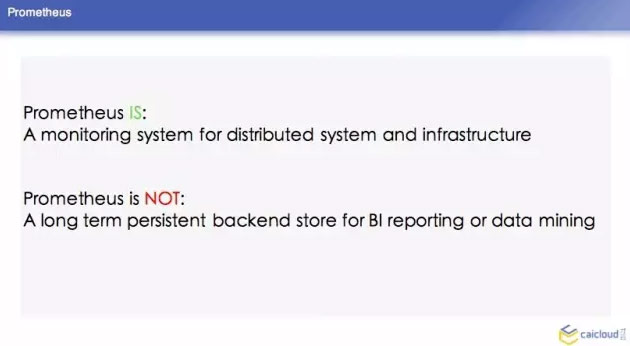
介绍完 Prometheus 的背景,我们可以看到这里有两点 Prometheus 的概述:首先,Prometheus 是一个监控系统,它可以监控你的基础设施。如果你想把它作为一个后期大数据分析或者 BI 报告的 backend,Prometheus 不是你的第一选择。我刚才也说到了,它是独立的一个系统,它自己的存储都是存在本地,没有考虑用一些外部存储来持久化这些数据,所以它不是持久的数据库。它只可以保存一周或者几周的数据,方便你去做一个监控。
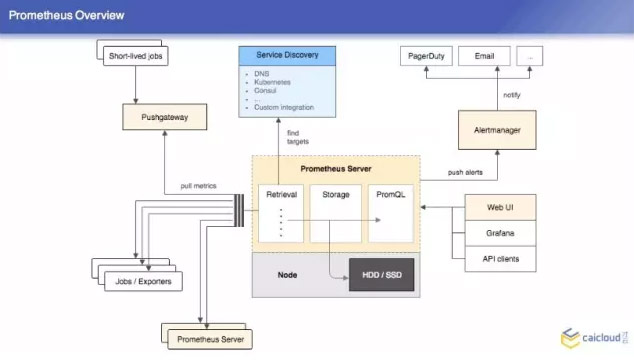
那我们在讨论一个系统的时候,不可避免要看它的架构图,Prometheus 的架构图非常简单,这里面有三块东西,首先是 Retrieval,这个里面定义的是什么?我这个 Prometheus 的服务器在哪里拉取数据,也可以从其他的 Prometheus 的服务器拉取数据。
我们可能有很多会跑一些运行,然后就退出了,在这个 short lived jobs 里面,他就是在这个拉完之后运行到下面,这里面都是一些静态定义的拉取目标, Prometheus 还可以支持动态的,比如说 DNS 等,这一块是 Retrieval,然后第二块是 Storage,当然也有一些外挂存储的方式,这都是我们在做监控的环节下不需要的。最后就是 promQL,通过这个可以直接查询。
右上角就是做报警的,它跟 Prometheus 是分开的两个项目,比如说我这个机器的 CPU 超过两个核之后要报警,Prometheus 就周期检验这些规则,这个就对 Prometheus 发过来的东西进行聚合押禁,这也是一个架构图,比较简单。

我们可以看一下这个 Prometheus 的数据格式是什么样的,也非常简单,非常容易理解。你这个 metric,后面是 label,然后你可以用这种 label 选到你想要的持续数据。底下是 Prometheus 做的一些查询,这个是他的一个数据的结构。
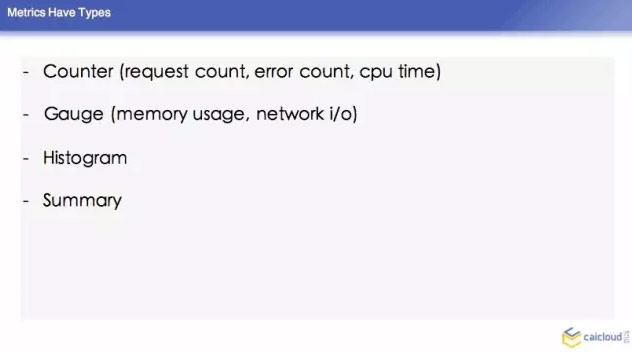
然后这个里面,它里面的 counter,有 error count,还有 CPU time,对于这些又会增又会减的,有一个叫 Gauge 的类型,下面两种是比较复杂的一些指标,histogram 就是柱状图,还有 summary,这两个不做介绍了。我们可能平时要算这个,可能要通过这两个指标来做。


Prometheus 怎么样来配置,由于时间关系,我简单列了一些常见的。然后这个 surape interval 10 秒,可以根据某个规则发出来,还有 recording rule,你这个程序每在CPU运行一段时间,就把这次运行在 CPU 的时间加在 CPU time 上面。这个东西怎么算?他需要对 CPU suage 上面进行计算,需要做一个运算,这个查询比较慢,我们可以写这样一个表达式,把这个指标复制给另外一个指标,查询的时候,就可以直接查这个指标得到 CPU 的使用量。这个也是每隔一段时间做一些检验的,下面有一些例子。
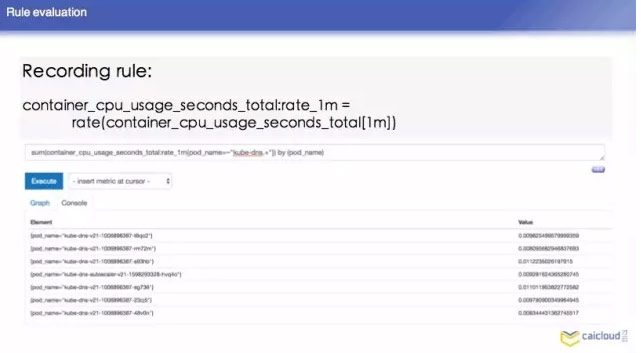
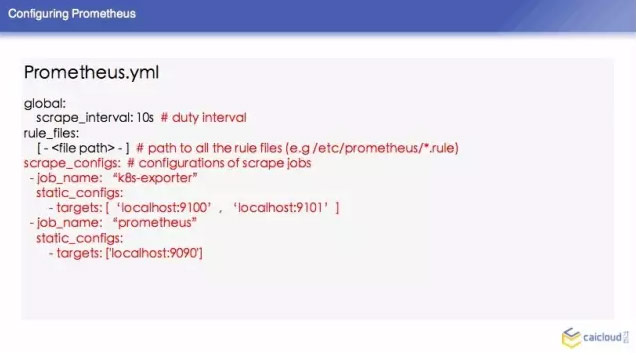
再下面就是告诉 Prometheus 要去哪里拉数据,然后他定义的 Targets 是 local host 9100 和 local host 9101,那么我们可以想像一下在这个 K8S 环节中,我们 K8S 是非常动态的环节,我们不可能把所有的东西都写在静态的配置文件里面,那下面讲一下 Prometheus 怎么跟 K8S 做一个结合的。

这里举了一个例子,我们知道 K8S 每个节点都有进行整合。然后他会通过一个路径把容器的指标暴露出去,这个时候我们在 Prometheus 里面怎么配呢?这是一个名词,我现在告诉 Prometheus 我的 Jobmame,用的 Kubernetes nodes,Prometheus 知道它要去 K8S 里面去知道 nodes,然后暴露地址去拉取数据。
下面这个 relabel config 呢,对这些标签进行操作,这个操作是因为我们 K8S 里面可以打上很多标签,我们可以知道查询的时候,知道其他的一些指标,它是在哪台机器。




我们刚才通过一个例子给大家讲了一下怎么拉取容器的指标,那这个 K8S 系统里面运行了其他的数据怎么办?这些东西的指标怎么办呢?这个 Prometheus 有一个概念叫 Databases,通过第三方系统服务暴露了一些指标,Prometheus 它不懂,把这些指标转换成 Prometheus 可以理解的数据格式,然后从路径去暴露出来。这底下有一个链接,这个链接有已经实现的东西。

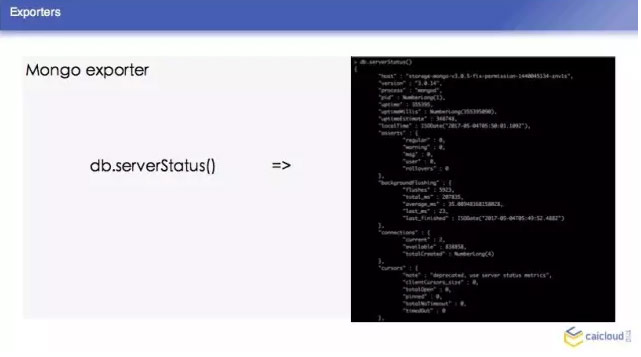
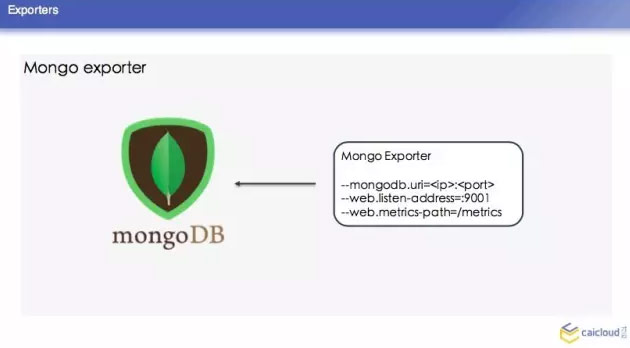
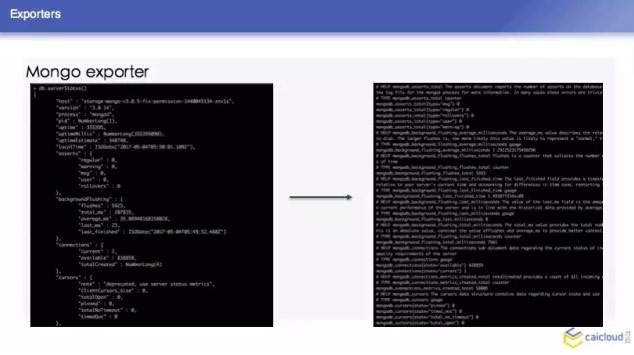
我们这里再去举一个 Mongo exporter 的例子,我们首先知道 Mongo exporter 的 db.server Status,部署一个 Mongo,我可以配置我的 Mongo 在哪里,然后就知道在哪里取这个数据,然后从什么地方把数据暴露给 Prometheus,让 Prometheus 来采。最后把这样一个 Mongo 取到的数据转换为 Prometheus 能够理解的格式。
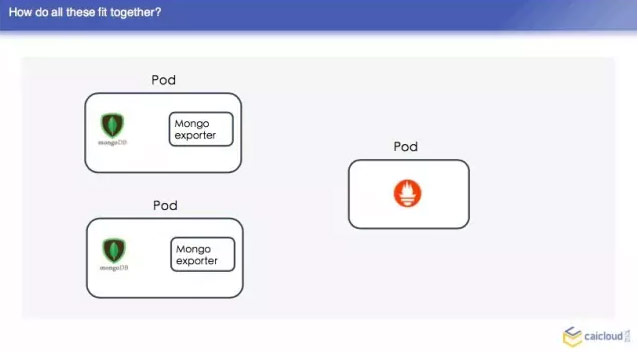
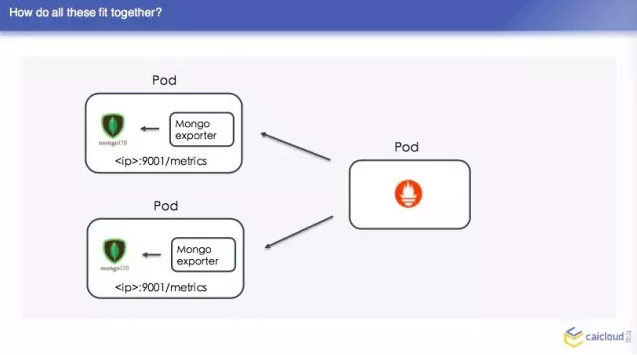
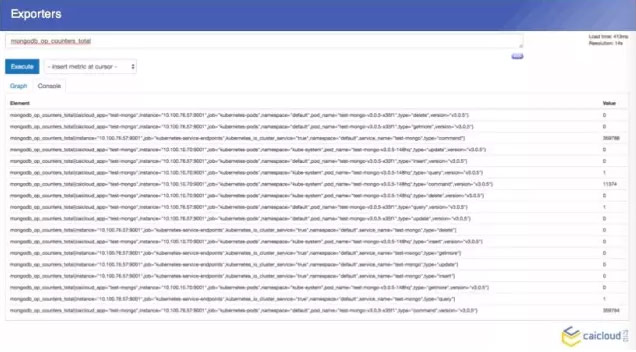
在整个的数据中,我们 Prometheus 不属于 pod 的,现在 Prometheus 的 pod,他先去另一个地方有多少个 pod,找到之后然后找 Mongo exporter的pod,这个 pod 里面跑了两个容器,一个是 Mongo,一个是 exparter,把这些监控数据暴露出来,然后这个 Prometheus 直接去两个地方取了,这样就可以得到两个监控数据了,我们去查询页面也可以查到。
然后我们把这些东西部署出来之后,可能有人又要问了,我们这个服务,即使我们内部监控数据量特别大,这里有一个从 Brian Brazil 他在博客写的一个数据,单个的 Prometheus 数据可以轻松出来几百万的时间序列。单个的 Prometheus 还是比较轻松出来的。当我们超过了这个数据,我们需要考虑一些其他的方案了。

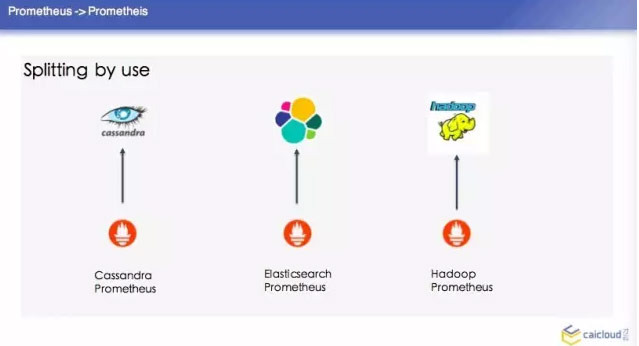
这里顺便提一个冷知识,就是 Prometheus 是古希腊里面的人物。第一种是 splitting by use,然后这个单独去建这个集群,单个的 Prometheus 去查询,这是最简单的方案。比如你分担一部分数据也没有办法做怎么办呢?就是 Horizontal Shardding,这里分了三个 Prom,每个 Prom 分一个 Prometheus 去采,这样去做一个汇总。
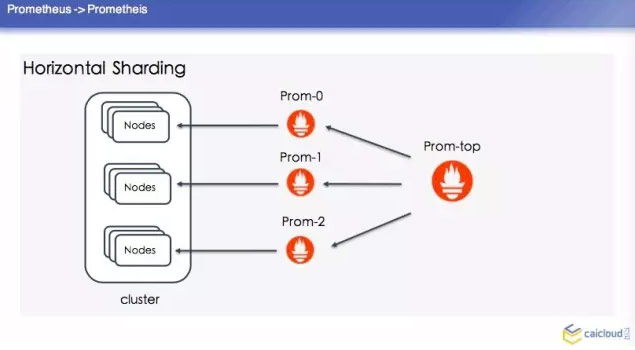
如果这样去配置的话,这个 Prometheus 的集群怎么写呢?这里也举了一个例子,首先这三个 Prometheus 的配置,他们的配置都基本差不多。比如说这个 slave,他这个输出的数据我都给打一个 slave:1,我告诉这个 Prometheus 他要采哪些数据,这里是怎么写的?他这里是按照 source labels 做了一个操作。然后再对这个进行操作,如果匹配了1,那我的 action 就是 keep。
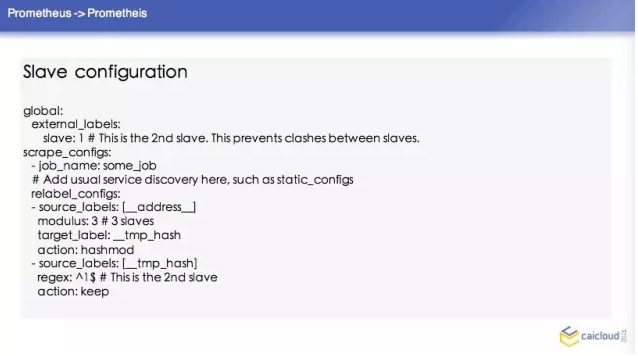

那他这个 Top level configuration 怎么去配置呢?他要在 federate 去采,然后他去采所有的 slave level 地址的持续数据,这个我们的树状结构的 Prometheus 就配置完了。
我们知道对于一个监控系统来说,系统挂了,还是希望在监控系统看到一些东西,那 Prometheus 的 HA 系统非常简单,你用同样的数据跑两个 Prometheus。这里又有人会有问题了,当我们去讨论一个分布式的存储的时候,我们没办法讨论他的理论。
我们在 Consistenc 和 Availability 和 Partition Tolerance当中选两个,监控数据是海量的,如果你丢几个数据点是没有关系的。说到这一块,我今天分享的内容已经基本结束了,最后给大家总结一下。

我们在选取一个监控系统的时候,还是更多要根据我们内部的实际情况,比如说我们对这个监控数据、大数据处理完全没有需求的时候,我们完全没有必要给 Prometheus 外挂一些数据。
一旦你分布式的数据库出了问题,你的监控系统也用不了,我们在选的时候还是要根据实际情况。如果我们内部的需求就是要做这样一个数据分析,监控数据对我们来说都是非常有价值的,我们要把这些数据存一年、两年,我们就要付出一些代价。
本文转自中文社区-用 Prometheus 来监控你的 Kubernetes 集群