- 过滤器是在get或者scan时候过滤结果用的,.HBase中的过滤器被用户创建出来后会被序列化为可以网络传输的格式,然后被分发到各个RegionServer.然后在RegionServer中Filter被还原出来,这样在Scan遍历过程中,不满足条件的结果都不会被返回客户端

- 所有的过滤器都要实现Filter接口.HBase同时还提供了FilterBase抽象类,它提供了Filter接口的默认实现
值过滤器ValueFilter
-
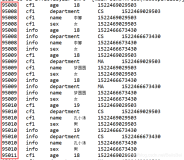
表中数据
hbase(main):018:0> scan 'test' ROW COLUMN+CELL row1 column=cf:name, timestamp=1544414130937, value=tom row2 column=cf:name, timestamp=1544414140380, value=jon row3 column=cf:name, timestamp=1544414146003, value=wang row4 column=cf:name, timestamp=1544414151373, value=qiang row5 column=cf:name, timestamp=1544414159901, value=sam 5 row(s) Took 0.0470 seconds -
要求挑选出name中带a字母的name
public void valueFilter() throws IOException { Connection connection = ConnectionFactory.createConnection(); Table table = connection.getTable(TableName.valueOf("default:test")); Scan scan = new Scan(); //值过滤器 ValueFilter filter = new ValueFilter(CompareOperator.EQUAL, new SubstringComparator("a")); scan.setFilter(filter); ResultScanner results = table.getScanner(scan); for (Result result : results) { String value = Bytes.toString(result.getValue(Bytes.toBytes("cf"), Bytes.toBytes("name"))); System.out.println(value); } table.close(); connection.close(); } -
结果
wang qiang sam -
对于CompareOperator.EQUAL中的枚举有如下几个
LESS, 小于 /** less than or equal to */ LESS_OR_EQUAL, 小于或者等于 /** equals */ EQUAL, 等于 /** not equal */ NOT_EQUAL, 不等于 /** greater than or equal to */ GREATER_OR_EQUAL, 大于等于 /** greater than */ GREATER, 大于 /** no operation */ NO_OP, 无操作 - 而对于SubstringComparator是一个编辑器,作用是判断目标中是否含有指定字符串
-
这个代码比较了所有cell的value,当前只是有一个name列,如果在添加一个其他列是什么情况呢
hbase(main):019:0> put 'test','row1','cf:tmp','aaa' -
再次扫描的结果
null wang qiang sam - 会出现一个null值,这个null值就是对应的新增列tmp,为什么会出现null呢,因为scan对象在扫描row1的时候发现tmp也是符合规则的,然后将它一并返回了回来,但是我们只是在代码中取得name,而不是tmp,所以这也是为什么会出现null了.
- 对于上面scan是直接扫描一行的,那有没有扫描一列的呢?
单列值过滤器SingleColumnValueFilter
-
重复代码就不贴了,只需要将Filter换为SingleColumnValueFilter即可
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("cf"), Bytes.toBytes("name"), CompareOperator.EQUAL, new SubstringComparator("a")); -
结果
wang qiang sam - 使用这个Filter需要注意的是,在我们指定扫描的列不存在的时候,会将一整行的数据都放入结果集,即如果我们更改上面的列信息为names,表中并没有这一列,这个过滤器就会返回这一行的所有数据
- 所以在使用这个过滤器的时候,如果能够确保每一行都有指定的列,那么使用没问题,如果无法确保我们可以在返回的结果集中寻找我们想要的信息,或者使用过滤器列表,即一组过滤器的集合,进行同时过滤,后面会说这个
比较运算
- 可能看到上面的SubstringComparator会有点蒙,从名字上我看我们就能够知道是子串比较,类似SQL的Like,这个类是继承ByteArrayComparable的,即字符比较,它是一个抽象类,实现了Comparable接口,其实现类有字节比较,正则比较,,数字比较一系列的实现类,那么我们来看一下具体是怎么用的
-
要求,查找出name为wang的行,即name='wang'
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("cf"), Bytes.toBytes("name"), CompareOperator.EQUAL, new BinaryComparator(Bytes.toBytes("wang"))); - 只需要把子串过滤器换一下就好了,然后结果就只输出了我们要查找的内容
-
我们已经清楚了,在HBase中是按字节比较的,我们表中的name按字典排序应该是这样的
jon qiang sam tom wang -
所以现在的需求是取出大于som的即将比较枚举换为GREATER,然后结果为
tom和wangSingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("cf"), Bytes.toBytes("name"), CompareOperator.GREATER, new BinaryComparator(Bytes.toBytes("som"))); -
之前我们操作过当使用HBase的shell保存数字的时候,他其实是按字符串保存进去的,如果你想保存真正的数字,就使用api,在使用api保存后,我们看到数字已经是一堆乱码了,其实这是数字保存为字节数组后的结果,所以如果我们要比较数字首先确保整个数字是按数字类型保存的,之后再使用BinaryComparator比较即可
Filter filter = new SingleColumnValueFilter(Bytes.toBytes("cf"),Bytes.toBytes("age"), CompareOperator.GREATER,new BinaryComparator(Bytes.toBytes(15)));
分页过滤器PageFilter
-
HBase只能实现SQL中的limit的功能,如下代码
public void pageFilter() throws IOException { Connection connection = ConnectionFactory.createConnection(); Table table = connection.getTable(TableName.valueOf("test")); Scan scan = new Scan(); //设置分页大小 Filter filter = new PageFilter(2); scan.setFilter(filter); ResultScanner results = table.getScanner(scan); for (Result result : results) { for (Cell cell : result.listCells()) { System.out.println(Bytes.toString(CellUtil.cloneValue(cell))); } } table.close(); connection.close(); } -
如果想实现limit n,n功能的话,只能是保存上一页中最后一个rowkey,然后从此rowkey的下一个开始扫描,比如这样
public void pageFilter() throws IOException { ... byte[] rowkey = null; for (Result result : results) { for (Cell cell : result.listCells()) { System.out.println(Bytes.toString(CellUtil.cloneValue(cell))); rowkey = CellUtil.cloneRow(cell); } } System.out.println("************************"); scan.withStartRow(Bytes.add(rowkey,new byte[1])); //这里设置了下一次的scan的起始key ResultScanner results1 = table.getScanner(scan); for (Result result : results1) { for (Cell cell : result.listCells()) { System.out.println(Bytes.toString(CellUtil.cloneValue(cell))); } } ... } - 如上代码很容易读懂,为什么最后要加一个空字节,这是因为Scan返回的结果是包含startRowkey对应的记录的(即不希望把上一页的最后一个行也读出来),而我们不希望第二次的Scan结果集把第一次的最后一条记录包含进去.
- 需要注意的是本文开始提到了,过滤器是分发执行的,所以彼此之间并不知道回返了多少条,可能出现返回的数据多余n行,这时候如果精确控制的n行的话,就需要自己去处理返回结果集
过滤器集合FilterList
- 即一组过滤器组合在一起对数据进行过滤
-
要求过滤包含w子串的并取前两个结果显示,这很明显是单列过滤+分页显示
... SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("cf"), Bytes.toBytes("name"), CompareOperator.EQUAL, new SubstringComparator("w")); PageFilter pageFilter = new PageFilter(2); FilterList list = new FilterList(); list.addFilter(pageFilter); list.addFilter(filter); scan.setFilter(list); ... - 核心的代码就上面的一段,这段代码就可以完成上面的要求,那颠倒过滤器的顺序会导致结果发生变化吗,我参考的教材上说是有影响的,给出的理由是List是有序的所以会按照添加的过滤器顺序来,但是在我测试的时候,并没有出现这种情况,所以在这请留意一下自己的版本的差异
- 实现AND 或者 OR关系,我们并可能只用一个条件,肯定有些时候会用到AND或者OR条件,那么该怎么实现呢?
-
FilterList.Operator中包含两个枚举
public enum Operator { /** !AND */ MUST_PASS_ALL, /** !OR */ MUST_PASS_ONE } -
他们用在FilterList创建的对象的时候,比如
FilterList list = new FilterList(FilterList.Operator.MUST_PASS_ONE); - 上面就表示符合list中过滤器集合的任何一个条件都可以被返回,但是如果你list中包含了page分页限制是没有效果的,原因是当你用MUST_PASS_ONE的时候 就算分页过滤器中的计数器达到最大条数后,扫描器依然会往下继续遍 历所有数据,以找出满足单列值过滤器的记录
-
如何实现
(1 and 2) or 3的效果呢,我们可以将(1 and 2)看做是一个过滤器集合,然后or 3是一个,所以实现方式就是FilterList嵌套就好了FilterList or = new FilterList(FilterList.Operator.MUST_PASS_ONE); FilterList and = new FilterList(FilterList.Operator.MUST_PASS_ALL,or); - 动手实现以下,表中列active=1并且名字包含wang的,或者名字中包含s的,下面是表中的数据

public void test() throws IOException {
// 表中列active=1并且名字包含wang的,或者名字中包含s的
Connection connection = ConnectionFactory.createConnection();
//包含wang的
SingleColumnValueFilter wangFilter = new SingleColumnValueFilter(Bytes.toBytes("cf"),
Bytes.toBytes("name"),CompareOperator.EQUAL,new SubstringComparator("Wang"));
//active==1的
SingleColumnValueFilter activeFilter = new SingleColumnValueFilter(Bytes.toBytes("cf"),
Bytes.toBytes("active"),CompareOperator.EQUAL,new BinaryComparator(Bytes.toBytes("1")));
//两个条件必须全部满足
FilterList one = new FilterList(FilterList.Operator.MUST_PASS_ALL);
one.addFilter(wangFilter);
one.addFilter(activeFilter);
//名字带s
SingleColumnValueFilter sFilter = new SingleColumnValueFilter(Bytes.toBytes("cf"),
Bytes.toBytes("name"),CompareOperator.EQUAL,new SubstringComparator("s"));
FilterList two = new FilterList();
two.addFilter(sFilter);
//两个过滤器是满足其中一个就好
FilterList three = new FilterList(FilterList.Operator.MUST_PASS_ONE,one,two);
Scan scan = new Scan();
scan.setFilter(three);
ResultScanner results = connection.getTable(TableName.valueOf("test")).getScanner(scan);
//正确结果是:名字带wang并且active==1 或者是名字带s,active没要求
for (Result result : results) {
for (Cell cell : result.listCells()) {
System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+"=>"+
Bytes.toString(CellUtil.cloneQualifier(cell))+"=>"+Bytes.toString(CellUtil.cloneValue(cell)));
}
}
connection.close();
}-
结果
row1=>active=>1 row1=>name=>billyWangpaul row2=>active=>1 row2=>name=>sara row3=>active=>0 row3=>name=>chris row5=>active=>1 row5=>name=>andyWang
行过滤器RowFilter
- 针对rowkey过滤,即该rowkey是否大于小于等于指定rowkey
-
找出大于row3的行
RowFilter filter = new RowFilter(CompareOperator.GREATER,new BinaryComparator(Bytes.toBytes("row3")));
多范围行过滤器MultiRowRangeFilter
-
还有多范围行键过滤,即row1到row3和row5到row6之间的值
MultiRowRangeFilter.RowRange rowRange1 = new MultiRowRangeFilter.RowRange("row1",true,"row3",false); MultiRowRangeFilter.RowRange rowRange2 = new MultiRowRangeFilter.RowRange("row4",true,"row6",false); List<MultiRowRangeFilter.RowRange> rowRanges = Arrays.asList(rowRange1, rowRange2); MultiRowRangeFilter filter = new MultiRowRangeFilter(rowRanges); Scan scan = new Scan(); scan.setFilter(filter); - 对于boolean参数的解释:第一个boolean是指是否包含指定的起始行键,第二个boolean是指是否包含指定的结束行键,上面程序返回了row1,row2,row4,row5
行键前缀过滤器PrefixFilter
-
可以匹配行键前缀,现在表中的行键都是rowX,我们把它都扫描出来
PrefixFilter filter = new PrefixFilter(Bytes.toBytes("row"));
模糊行键过滤FuzzyRowFilter
- 知道行键的开头如何匹配了,就剩下中间和末尾匹配了
-
下面是一种rowkey的格式,2016年6月22日去了北京
2016_06_22_beijing - 如果我们想把他查出来,比如要求是2016年,他都什么时间去了beijing,那么可以用这个过滤器
-
要求查找2016年什么时间去北京了和2012年什么时间去干什么了
Pair<byte[], byte[]> par1 = new Pair<>(Bytes.toBytes("2016_??_??_beijing"),new byte[]{ 0,0,0,0,0,1,1,0,1,1,0,0,0,0,0,0,0,0 }); Pair<byte[], byte[]> par2 = new Pair<>(Bytes.toBytes("2012"),new byte[]{ 0,0,0,0 }); List<Pair<byte[], byte[]>> fuzzy = Arrays.asList(par1,par2); FuzzyRowFilter filter = new FuzzyRowFilter(fuzzy); Scan scan = new Scan(); scan.setFilter(filter); -
上面的Pair有两部分构成,一个是行键,一个行键掩码fuzzy info
- 行键,里面的问号可以用任意字符代替,具体的数字也没问题,问号代替了你模糊不清的条件,因为我们要查询时间,所以时间就是模糊不清的
- 掩码:掩码长度必须和你的行键长度一致,0代表确认了,所以2016对应的下面的bytes数组的前四位为0,下划线也是确认的所以是0,而1代表不确定,所以行键的问号位置对应的byte数组位置上的数字为1,然后第二个Pair查询的2012都干啥了,其实也可以用行键前缀过滤,如上这么写也是可以的
包含结尾过滤器InclusiveStopFilter
-
使用scan返回的结果集并不会返回终止行,如果想返回终止行数据,可以在终止行rowkey上加一个字节的数据,然后作为stoprow的条件,或者使用这次介绍的过滤器
InclusiveStopFilter filter = new InclusiveStopFilter(Bytes.toBytes("2016_08_15_beijing")); -
更简单的方式是在设置结束行键的时候指定一下参数
scan.withStopRow(Bytes.toBytes("2016_08_15_beijing"),true); - true就是包含,false就不是默认的不包含,如果你没有这参数,可能是版本不一致,我的是2.1.1
随机行过滤器RandomRowFilter
-
即抽取一部分数据的时候用
RandomRowFilter filter = new RandomRowFilter(0.5F); - 在抽样的时候,每到一行都会生成一个float,用生成的float跟你传入的参数比,如果比你传入的参数小,那么数据会被抽出来,否则就被过滤掉,当构造参数为负数,即过滤掉所有的,大于1是全部抽取,所以这个参数就是你到总体数据的百分比
列族过滤器FamilyFilter
-
即将符合规则的列族放入结果集,使用很简单
FamilyFilter filter = new FamilyFilter(CompareOperator.EQUAL,new BinaryComparator(Bytes.toBytes("cf")));
列过滤器QualifierFilter
-
即将符合规则的列放入结果集
QualifierFilter filter = new QualifierFilter(CompareOperator.EQUAL,new BinaryComparator(Bytes.toBytes("namex")));
列依赖过滤器DependentColumnFilter
-
首先准备数据
Put put = new Put(Bytes.toBytes("row1")).addColumn(Bytes.toBytes("cf"), Bytes.toBytes("name"), Bytes.toBytes("w1")) .addColumn(Bytes.toBytes("cf"), Bytes.toBytes("age"), Bytes.toBytes("14")); Put put1 = new Put(Bytes.toBytes("row2")).addColumn(Bytes.toBytes("cf"), Bytes.toBytes("name"), Bytes.toBytes("w2")) .addColumn(Bytes.toBytes("cf"), Bytes.toBytes("age"), Bytes.toBytes("23")); - 现在表中是这样的,目前timestamp都是一致的

-
然后我们使用这个过滤器,指定依赖的列为name
DependentColumnFilter filter = new DependentColumnFilter(Bytes.toBytes("cf"),Bytes.toBytes("name")); -
结果
row1=>14 row1=>w1 row2=>23 row2=>w2 -
然后我们从新put一下row1的age,以更新age列的timestamp
hbase(main):014:0> put 'test','row1','cf:age','14' -
所以现在row1的name列的时间戳是最新的,然后在执行这个过滤器
row1=>w1 row2=>23 row2=>w2 -
我们发现就只剩下了name列返回了,而row2是不受影响的,因为我们并没有改变row2的数据的时间戳,到这就可以知道了,这个过滤器是指定一行中的列,用指定的列的时间戳去比较这一行的其他列,如果时间戳一样就返回,否则就不返回,为了证明这一点,我们继续,这次将row1的name和age再从新put,设置为同一时间戳,用api更新
Put put = new Put(Bytes.toBytes("row1")).addColumn(Bytes.toBytes("cf"), Bytes.toBytes("name"), Bytes.toBytes("w1")) .addColumn(Bytes.toBytes("cf"), Bytes.toBytes("age"), Bytes.toBytes("14")); - 现在我们就看到了,row1的name和age是一样的时间戳

-
然后在执行这个过滤器,刚才消失的age就又出现了
row1=>14 row1=>w1 row2=>23 row2=>w2
列前缀过滤器ColumnPrefixFilter
- 与行前缀过滤器一样,下面是使用
-
过滤列前缀为ag的cell
ColumnPrefixFilter filter = new ColumnPrefixFilter(Bytes.toBytes("ag"));
多列前缀过滤器MultipleColumnPrefixFilter
-
跟多行区间过滤一样的,过滤多个列,下面是使用
byte[][] bytes = {Bytes.toBytes("age"),Bytes.toBytes("name")}; MultipleColumnPrefixFilter filter = new MultipleColumnPrefixFilter(bytes);
列名过滤器KeyOnlyFilter
-
这个过滤器不过滤数据,只是把列名拿出来
KeyOnlyFilter filter = new KeyOnlyFilter();
首列名过滤器FirstKeyOnlyFilter
- 此过滤器只过滤一行中的第一个列,当遇到一行中的一个列的时候,他就不会再往剩余的列执行了,转而执行下一行,去找下一行的第一个列
- 过滤器的作用就是把每一行的第一个列名拿出来,可以用在count所有列上,
-
求这个表中一共有多少行
FirstKeyOnlyFilter filter = new FirstKeyOnlyFilter(); - scan设置为上面的过滤器后,然后去遍历结果看看一共有多少返回就可以了,因为有列必定存在行
列名范围过滤器ColumnRangeFilter
-
跟过滤rowkey的范围一样,就是指定一下最小列名和最大列名就可以,然后取出给出范围内的列名,如果最小列名为ab,最大的为ad,那么ac,abc都可以被取出,而ag不可以
ColumnRangeFilter filter = new ColumnRangeFilter(Bytes.toBytes("ab"),true,Bytes.toBytes("ad"),false); - boolean参数代表是否包含最小列名和最大列名
列数量过滤器ColumnCountGetFilter
-
上面的过滤器都是针对scan使用的,而这个是用于get的,用处是取前n个列的值
... ColumnCountGetFilter filter = new ColumnCountGetFilter(1); Table table = connection.getTable(TableName.valueOf("test")); Get get1 = new Get(Bytes.toBytes("row1")); get1.setFilter(filter); Get get2 = new Get(Bytes.toBytes("row2")); get2.setFilter(filter); List<Get> list = Arrays.asList(get1,get2); Result[] result = table.get(list); ... - 上面设置了两个get,得到两行的前1个列的数据
- 当然这个也可以用于scan,假如你表中每一行都有3列,那么你设置过滤前2列,当执行的时候,结果只会返回第一行的前2列,因为多出来了一列,过滤器就会退出,如果你设置过滤前3列的时候,就会返回所有数据,因为这是最大的列数了,当你在某一行又新增一列的时候,scan扫描到这一行会停止,会返回这一行的前n列和之前扫描过的数据

列翻页过滤器ColumnPaginationFilter
-
这个也是用于get的,是取一行列的范围的,比如第2列到第4列
ColumnPaginationFilter filter = new ColumnPaginationFilter(2,2); - 第一个构造参数是说明分页大小,第二个参数是从第几个列开始遍历
时间戳过滤器TimestampsFilter
-
这个过滤器同样适用get和scan,他的构造参数并不是时间戳的区间范围,而是准确值,所以这个过滤器更适合timestamp是自定义的情况
List<Long> list = Arrays.asList(1544512482917L,1544507404825L); TimestampsFilter filter = new TimestampsFilter(list); - 只会返回和给定时间戳一样的数据
装饰过滤器
- 装饰过滤器是一类过滤器的统称.这类过滤器不能单独地使用,它必须依赖别的过滤器才能起作用.我们用装饰 过滤器来包装其他过滤器,实现了对过滤器结果的扩展和修改
-
跳转过滤器SkipFilter
- 用这种过滤器来包装别的过滤器的时候,当被包装的过滤器判断当前的KeyValue需要被跳过的时候,整行都会被跳过.换句话说只需要某 一行中的某一列被跳过,这行数据就会被跳过.不过被包装的过滤器必 须实现filterKeyValue()方法,否则跳转过滤器(SkipFilter)无法正 常工作.
- 现在表中是这样的

- 要求只要遇到age==14的就跳过此行
ValueFilter valueFilter = new ValueFilter(CompareOperator.NOT_EQUAL,new BinaryComparator(Bytes.toBytes("14")));
SkipFilter filter = new SkipFilter(valueFilter);
scan.setFilter(filter);-
全匹配过滤器WhileMatchFilter
- 跳转过滤器是只要有一个过滤器的filterKeyValue()方法 返回false,整行的数据就会被跳过.而全匹配过滤器有一个过滤器的filterKeyValue()方法返回false, 整体的Scan都会终止
- 比如过滤rowkey为row3的行,如果使用行过滤器,现在表中是这样的
RowFilter filter = new RowFilter(CompareOperator.NOT_EQUAL,new BinaryComparator(Bytes.toBytes("row3"))); scan.setFilter(filter);- 结果只是过滤了row3而已,而还可以继续往下扫描,row4..row5...
row1=>150 row2=>23 row2=>w2 row4=>w4- 使用全匹配,即遇到row3,scan就停止了然后后面也就不扫描了
RowFilter filter = new RowFilter(CompareOperator.NOT_EQUAL,new BinaryComparator(Bytes.toBytes("row3"))); WhileMatchFilter whileMatchFilter = new WhileMatchFilter(filter); scan.setFilter(whileMatchFilter);- 结果还是有返回的,只是返回之前已经匹配好的结果
row1=>14 row1=>nan row1=>xx14 row1=>w1 row1=>150 row2=>23 row2=>w2