- 可以说这一篇文章是我开博客一来最难总结的一篇,画图学习,而且还有一些内容并没有涉及到:比如最小生成树和最短距离等问题.本文主要是概括的说一下图的概念,以及图的遍历方式,对于其他内容以后会陆续更新的,如果本文对你有些许帮助请帮忙点个赞支持一下哈~
- 图是一种非线性结构,在实际生活中,有很多可以形象比喻的例子:比如人之间的关系图.地铁图等,下面就是一个人际关系图

- 之前学过的链表是一对一关系,树是一对多关系,那么图就是多对多的关系,即图中的每个元素之间可以任意相关联,这样就构成了一个图结构
基本概念

- 顶点Vertex:图中的ABC...都是一个顶点
- 边Edge:图中连接这些顶点的线
- 所有的顶点构成一个顶点集合,所有的边构成边集合,一个完整的图结构由顶点集合和边结合组成,用数学记为
G = (V , E) 或 G = (V(G) , E(G))
- 其中V(G)表示图中所有顶点的集合,E(G)是图中所有边的集合,每条边由所连接的两个顶点表示
- 需要注意的是图中可以没有边,但是必须保证有一个顶点,即E(G)可以为空,而(V(G))不可以
-
对于上面的图应该这样表示
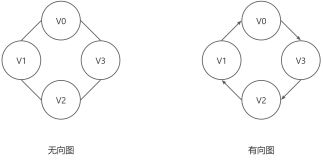
V(G)顶点={VA,VB,VC,VD,VE,VF,VG} E(G)边={(VA,VC),(VC,VD),(VD,VE),(VE,VG),(VG,VF),(VF,VB),(VA,VF),(VA,VB),(VB,VG),(VB,VD)} - 无向图:就是上面这种,边并没有方向,但是需要注意的是,在表示的时候E=(VA,VB)和E=(VB,VA)只能有一个,在无向图中,正反和反正视为一条边
- 有向图:,如下图,即图中的边都是有方向的,那么这种图就是有向图,既然边有了方向,所以在表示边集合E的时候,就需要按照边的指向来表示

-
上面有向图的表示方式
V(G)顶点={VA,VB,VC,VD,VE,VF,VG} E(G)边={<VC,VA>,<VD,VC>,<VB,VC>,<VB,VD>,<VB,VF>,<VA,VB>,<VF,VA>,<VF,VG>,<VG,VE>,<VE,VD>,<VE,VB>,<VG,VB>} - 边E的表示方向不能错误,,是不同的两条边
- 注意无向图的边的表示是用
(),有向图的边的表示是用<> -
顶点的度:连接顶点的边的数量就是该顶点的度,对于无向图来说,有几条边连到该节点,该节点的度就是多少,比如C顶点的度为2,B顶点的度为4.而对于有向图来说,分为入度和出度
- 入度,就是几个边指向该顶点,比如B的入度是3,即为ID
- 出度,就是该顶点有几个边指向外面,比如B的出度是2,即为OD
- 所以有向图的顶点的总度就是该节点的出度+入度之和,比如B的总度就是3+2=5,即D(V)= ID(V)+OD(V)
-
邻接顶点:即一条边的两端顶点,比如无向图中A与B通过边相连,那么A就是B的邻接顶点,B也是A的邻接顶点,A也是C和F的邻接顶点
- 而对于有向图来说,又要分为入边邻接顶点和出边邻接顶点
- 入边邻接顶点:连接该顶点的边中的起始顶点,即该起始节点就为该顶点的入边邻接顶点,比如,B连接到F,边方向指向F,所以B是这条边的起始顶点,即B是F的入边邻接顶点
- 出边邻接顶点:连接该顶点的边中的结束顶点,即结束节点就是该节点的出边邻接节点,比如,E连到B,方向指向B,所以B是结束节点,即B是E的出边邻接节点
- 无向完全图:即在一个雾像图中,每两个顶点之间都存在一条边,边数计算公式是(N(N-1)/2),N为顶点数

- 有向完全图:在一个有向图中,每两个顶点之间都存在反向相反的两条边,边数计算公式是N(N-1),N为顶点数

- 从上面的图也可以看到有向完全图的边是无向完全图边数的两倍
- 子图:概念类似子集合,由于一个完整的图包含顶点和边,因此,一个子图的顶点和边都应该是图结构的子集合

- 如上右边四个被框起来的,都是左边无向图的子图
- 路径:就是两个顶点之间的连线,连接两个顶点的路径不止一条,比如上图中,VA到VG,可以有VA-VB-VG,VA-VF-VG等等方案,经过的连线数为此路径的路径长度,前面列举的方案的路径长度都是2
-
图结构中的路径还可以细分为三种形式
- 简单路径:即如果一条路径上顶点不重复出现,则称为简单路径,如下

- 环:如果路径的第一个顶点和最后一个顶点相同,即首尾相连了,则称为环或者回路,如下

- 简单回路:如果除第一个顶点和最后一个顶点相同,其余各项顶点都不重复的回路为简单回路,应该就是上图这种情况
-
连通,连通图,连通分量
- 如果图结构中两个顶点之间有路径,则称这两个顶点是连通的,这里需要注意连通的两个顶点可以不是邻接顶点,只要有路径连接即可,可以有经过很多顶点
- 如果无向图中任意两个顶点都是连通的,那么这个图就可以成为连通图,如果无向图中包含两个顶点是不连通的,那么这个图就称为非连通图
- 无向图的极大连通子图称为该图的连通分量
- 对于一个连通图,其连通分量就有一个,即此连通图是不可拆分的,如果是一个非连通图,则有可能存在多个连通分量

-
强连通图和强连通分量
- 这是对于有向图来说的
- 如果两个顶点之间有路径,也称为这两个顶点是连通的,但是需要注意边的方向,方向不对即不连通
- 如果有向图中任意两个顶点都是连通的,则称为该图为强连通图,如果不是那么就是非强连通图
- 有向图的极大强联通子图称为该图的强连通分量
- 如无向图一致,当有向图是强连通图时,这个强连通图是不可拆分的,否则就可以拆分为强连通分量

- 权:即各个边上的值,之前我们图中边都是空的,我们可以将它赋值作为边的权,这个权在生活中可以想象成地铁图之间的距离,比如

- 网:边带有权值就可以成为网
- 了解完一些基本概念了,那么我们就来看一下图到底怎么去存
邻接矩阵法
- 先看无向图
- 采用结构数组的形式来单独保存顶点信息,然后采用二维数组的形式保存顶点之间的关系,这种保存顶点之间关系的数组称为邻接矩阵(当我画完图,我咋感觉保存顶点的数组并没有什么用呢?如果我理解的不对,请指正)

- 为什么会出现对称现象:比如V1和V2吧,由于是无向图,V1和V2公用一个边,即(V1,V2),所以就会保存两次这个边,即int1和int2,在上图中下标我都是减一处理的.
- 那么怎么知道某顶点的度呢?由于无向图存储数组是对称的,所以我们取顶点对应的行或者列相加即可,比如顶点3的度是4,那么图中我们可以取顶点3对应的行,即下标为2的行或者下标为2的列相加即可1+1+1+1=4
- 怎么知道哪些顶点与该顶点是邻接节点呢?比如3的邻接节点为1,2,4,5,我们直接扫描顶点对应的行或者列也就可以了,比如扫描第三行,即下标为2的行,我们扫描得到在列为0,1,3,4的位置上是1,那么就可以知道有哪些邻接节点了

- 这样存放虽然方便,但是这样看就会有很多的空间存放重复的元素了,因为无向图是对称的,所以我们可以只存放二维数组的一半

- 那么哪些权该怎么进行保存呢,直接将标识为1的替换为权值即可,判断的时候非0就是邻接节点
- 再来看有向图

- 我们可以看出有向图由于边有方向 ,所以并不能构成数组的对称分布,所以对于无向图的简化存储,在有向图这是行不通的,所以就只能够inti来判断是否有邻接节点了
- 对于有向图,怎么判断其入度和出度呢?我们从图中看顶点1的入度是1,出度是2,那么怎么从数组中体现出来

- 行即是出度,列是入度,顶点为1,所以它与其他顶点的关系就都表现在第0行和第0列,所以扫描就知道顶点的度了
-
邻接矩阵表示法这么存储有什么好处
- 简单直接容易理解
- 方便检查任意顶点之间是否有边
- 方便查找与该顶点邻接的所有邻接节点
-
有什么缺点呢?
- 除了在无向图中可以简化一点,但是依旧存在浪费空间情况,而在有向图中更加明显
- 因为我们的二维数组是根据顶点的最大值创建的,所以如果存在很多顶点,但是顶点之间的边非常少,这样就会造成数组基本都是0的情况,这就是为什么说是浪费空间
- 我们知道了数组的创建方式,所以如果我们真的遇到了顶点多边少的情况,当我们统计在这种情况下的边,我们就不得不一直去遍历0,然后收集仅仅那么几个1,所以时间上也是有浪费的
邻接法表示
- 对于上面的缺点,就是对于稀疏图(即顶点多,边少)的存储比较浪费空间的情况,可以考虑邻接法,实现方法就是数组加链表

- 上面是无向表的存储,我们可以看到这种格式避免了存储垃圾数据,1和3不搭边,邻接矩阵还需要存储一个0,而邻接法则不需要,他只需要存储于自己相关的数据,但是,如果仔细观察还是有问题的,因为我们是用链表加数组,链表的创建必定是一个对象,那么这个对象存储就比数组存储值空间大的多,并且我们看到,假如顶点2和4用这种方法存储,顶点而会记录一个到4的链表,而顶点4会记录一个到2的链表,存储重复,这个也是比较浪费空间的,所以说这个方法比较适合存储稀疏图
- 对于无向图,计算顶点的度,很容易,即遍历链表个数即可,判断是否是邻接节点也是相当容易的,只要链表中有,就代表这两个顶点是邻接节点.
- 看一下有向图

- 存储结构没有多大变动,但是由于边的方向的关系,上面的存储结构在计算出度的时候十分容易,即遍历链表做累加,但是计算入度的时候就很费劲了,我们还需要一个逆邻接表,即反向指针,两个表结合一起使用,才会很容易的计算出度和入度
十字链表存储
-
我们看完上面的邻接法表示,他的链表对象肯定是这样的
Node { T element 顶点值 Node next 链接指向 } - 正因为是这样,所以我们只能在一个邻接表中方便的得出入度或者出度,那么我们有什么办法可以解决这个限制吗,那就是十字链表,他的链表的结构是怎么样的呢
- 十字链表分为顶点表和边表,即存储顶点信息的和直接存储边信息的表
-
顶点表
Node{ element //顶点值 fristin //入边邻接节点 firstout //出边邻接节点 } - 上面的顶点表也是用数组存储的,然后数组指向顶点表,顶点表指向边表
-
边表
Node { tailVex 即入边邻接节点的起始顶点在数组中的位置,结合图来看 headVex 即入边邻接节点的终止顶点在数组中的位置 headLink 即表示指向弧头相同的下一条弧 tailLink 即表示指向弧尾相同的下一条弧 } - 首先上面出现了生词,弧

- 现在我才提弧头和弧尾,因为之前提这个并没有太大的作用,那么他是什么情况下用呢,即有向图的边都称为弧,弧分为弧头即指针方向,指针的反方向即为弧尾

- 上面五花八门的,那么我们慢慢的来梳理为什么是这么多指向
-
我们首先找到各顶点的出边邻接节点,即
V1:{<1,4>} V2:{<2,1>,<2,3>} V3:{<3,2>,<3,1>} V4:{<>} -
我们来看一下一个小例子
边表(1,2,null,null)代表什么 结合图来看,就代表<2,3>即有向图顶点2指向顶点3的那条弧(边),所以这是记录的弧而不是一个顶点 -
好了我们找到了出边之后,我们就先看蓝色指针的指向
- V1顶点表的出边即第三个格指向边表(0,3,null,null),对照上面我们找出来的出边,应该没疑问,数字减一因为是数组下表从零开始的
- V2顶点有两个出边,这时候V2其实是弧尾,指向的是弧头,所以V2的顶点表的出边属性首先指向边表(1,0,null,null),这时候还剩下一个<2,3>没有处理,则让(1,0,null,null)的第四个属性指向(1,2,null,null)即可.(因为V2指向V1和V3的时候,V2都是弧尾的角色,所以出路的指向相同即可连续指向,如果再让V2指向V4即<2,4>,那么我们就可以在(1,2,null,null)的第四个属性继续指向(1,3,null,null))
- V3顶点和V2一样,他有两个出边,就可以让顶点表的第三个出边属性指向一个边表(2,1,null,null),然后由于都是出边,所以(2,1,null,null)边表的第四个属性可以连续指向(2,0,null,null)
- V4顶点只有入边,没出边,所以无出边指向
- 现在蓝色代表的出边指向已经完成了,还剩了红色代表入边邻接节点的指向未处理
-
还是首先整理一下各顶点的入边情况
V1:{<2,1>,<3,1>} V2:{<3,2>} V3:{<2,3>} V4:{<1,3>} -
OK现在来看一下他的入边是怎么指向的
- V1顶点有顶点2和顶点3入边,所以在V1的顶点表的第二个入边属性指向(1,0,null,null)即<2,1>,然后由于都是入边,所以在处理<3,1>的时候,可以让(1,0,null,null)的第三个弧头属性指向(2,0,null,null)即<3,1>
- V2顶点只有一个入边,那就让V2的顶点表的第二个入边属性指向(2,1,null,null)即<3,2>即可
- V3,V4同V2一样的操作
- 好了现在我们就知道了十字链表的具体的存储细节了
- 在十字链表中怎么取入度呢,哇这就简单了,只需要遍历顶点表的入边属性就可以了,出度就遍历出边属性,对于判断节点间的入边邻接节点和出边邻接节点一样是看出边和入边属性即可
图的保存形式可以完全不同于上面方法,你可以完全按照你的想法或者业务需求来设计自己的数据结构,所以这是不唯一的,上面的方法只是给一个参考
图的遍历:深度优先遍历

图的广度优先遍历

-
代码:无向图的创建和遍历
import java.util.Arrays; import java.util.LinkedList; import java.util.Scanner; public class MyMatrixImpl { private int vertexCount; //顶点数量 private int edgeCount; private int[][] elementDataArr ;//二维数组 private String[] vertexValueArr ;//顶点值 public static final Scanner SCANNER = new Scanner(System.in); public void createGraph(){ System.out.println("顶点数"); vertexCount = SCANNER.nextInt(); //初始化存放顶点值数组 vertexValueArr = new String[vertexCount]; //将顶点值添加到数组 addVertexValueToArr(); System.out.println("边数"); edgeCount = SCANNER.nextInt(); //初始化二维数组 elementDataArr = new int[vertexCount][vertexCount]; //开始画图 drawGraph(); printGraph(); BFS(); DFS(); } private void printGraph() { System.out.println("\n 构建的图为 :"); for (int i = 0; i < elementDataArr.length; i++) { for (int j = 0; j < elementDataArr[i].length; j++) { System.out.print(elementDataArr[i][j] + " "); } System.out.println(); } } //画图 private void drawGraph() { System.out.println("输入顶点关系和权重:比如输入AB2,代表顶点A和顶点B相连,权重为2"); for (int i = 0; i < edgeCount; i++) { //输入AB2切分为 A B 2 ,并处理为 0 1 2,即对应下标 int[] tmp = splitStr(SCANNER.next()); int row = tmp[0]; int col = tmp[1]; int weight = tmp[2]; elementDataArr[row][col] = weight; elementDataArr[col][row] = weight; } } //输入AB2切分为 A B 2 ,并处理为 0 1 2,即对应下标 private int[] splitStr(String str) { int[] tmp = new int[3]; String[] split = str.split(""); for (int i = 0; i < tmp.length - 1; i++) { tmp[i] = Arrays.binarySearch(vertexValueArr,split[i]); } tmp[2] = Integer.parseInt(split[2]); //权重 return tmp; } //将顶点值添加到数组 private void addVertexValueToArr() { System.out.println("各个顶点名称"); for (int i = 0; i < vertexCount; i++) { vertexValueArr[i] = SCANNER.next(); } } //深度优先遍历 public void DFS(){ System.out.println("\n深度优先遍历"); boolean[] isVisited = new boolean[vertexCount];//标识每个顶点是否被访问过,默认false DFS(isVisited,0); } private void DFS(boolean[] isVisited, int row) { System.out.print(vertexValueArr[row]); isVisited[row] = true; for (int i = 0; i < vertexCount; i++) { if (elementDataArr[row][i] != 0 && !isVisited[i]){ DFS(isVisited,i); } } } //广度优先遍历,从第一个顶点开始,即数组内第一个存储顶点 public void BFS(){ System.out.println("广度优先遍历"); boolean[] isVisited = new boolean[vertexCount];//标识每个顶点是否被访问过,默认false LinkedList<Integer> list = new LinkedList<>(); list.offer(0); //即第一个顶点对应的第0行 int tmpNum ; while (!list.isEmpty()){ tmpNum = list.poll(); if (!isVisited[tmpNum]){ System.out.print(vertexValueArr[tmpNum]); isVisited[tmpNum] = true; //表示被访问过了 } for (int i = 0; i < vertexCount; i++) { if (elementDataArr[tmpNum][i] != 0 && !isVisited[i]){ list.offer(i); } } } } public static void main(String[] args) { new MyMatrixImpl().createGraph(); } } -
测试
顶点数 7 各个顶点名称 A B C D E F G 边数 10 输入顶点关系和权重:比如输入AB2,代表顶点A和顶点B相连,权重为2 AC1 CD1 DE1 EG1 GF1 FA1 AB1 BD1 BG1 BF1 构建的图为 : 0 1 1 0 0 1 0 1 0 0 1 0 1 1 1 0 0 1 0 0 0 0 1 1 0 1 0 0 0 0 0 1 0 0 1 1 1 0 0 0 0 1 0 1 0 0 1 1 0 广度优先遍历 ABCFDGE 深度优先遍历 ABDCEGF