中文分词
中文分词中有众多分词工具,如结巴、hanlp、盘古分词器、庖丁解牛分词等;其中庖丁解牛分词仅仅支持java,分词是HanLP最基础的功能,HanLP实现了许多种分词算法,每个分词器都支持特定的配置。接下来我将介绍如何配置Hanlp来开启自然语言处理之旅,每个工具包都是一个非常强大的算法集合,所以小编以后将花一些时间去看看里面源码如何。
下载jar、property和data文件
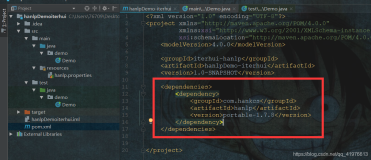
下载jar文件,(下载hanlp压缩包)解压之后获得jar和property文件如下:

其中property问配置文件,jar文件为外部引用文件。
然后下载data文件:
【https://】pan.baidu.com/s/1o8Rri0y (前面的括号自行去掉)
解压压缩包之后就能获取data目录了。
一切就绪之后下面就是配置了。
配置hanlp
新建一个空项目,包括一个新建的java文件的test.java,
1.package com;
2.import com.hankcs.hanlp.HanLP;
3.public class Test {
4.public static void main(String[] args) {
5. System.out.println(HanLP.segment("你好,欢迎使用HanLP!"));
6. }
7.}
目录结构如下图:
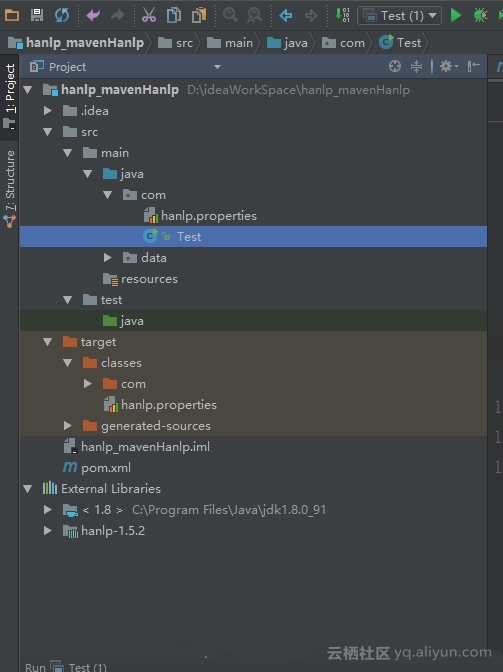
如果是在linux中的话,你可以将property文件放在classpath中,windows中也可以,配置环境变量,将property文件的绝对路径加上就可以了,然后运行一下这个java文件:
你会发现如下错误
1.十二月 11, 2017 9:59:37 下午 com.hankcs.hanlp.HanLP$Config <clinit>
2.严重: 没有找到hanlp.properties,可能会导致找不到data
3.========Tips========
4.请将hanlp.properties放在下列目录:
5.D:\ ideaWorkSpace\ hanlp_mavenHanlp\ target\classes
6.Web项目则请放到下列目录:
7.Webapp/WEB-INF/lib
8.Webapp/WEB-INF/classes
9.Appserver/lib
10.JRE/lib
11.并且编辑root=PARENT/path/to/your/data
然后将property放到相应的目录就可以了,注意property配置只需要修改root的配置就行了。
1.本配置文件中的路径的根目录,根目录+其他路径=绝对路径Windows用户请注意,路径分隔符统一使用/
2.root=D:/ideaWorkSpace/hanlp_mavenHanlp/src/main/java
就比如我的解压后的data文件夹是放在D:/ideaWorkSpace/hanlp_mavenHanlp/src/main/java目录下的那我就改这个就可以了,其余的配置不用修改
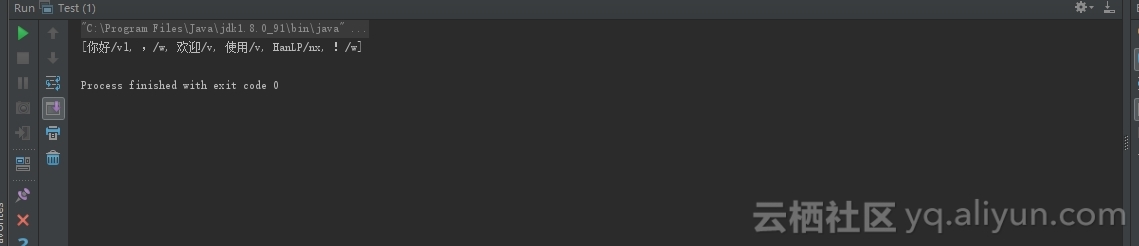
运行成功如下图:
---------------------
作者:学zaza