Spark Worker启动源码分析
更多资源
Youtube视频分享
Bilibili视频分享
start-slave.sh启动脚本
CLASS="org.apache.spark.deploy.worker.Worker"
spark-daemon.sh start $CLASS
Worker main入口
主要源码
def main(argStrings: Array[String]) {
Utils.initDaemon(log)
val conf = new SparkConf
val args = new WorkerArguments(argStrings, conf)
val rpcEnv = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, args.cores,
args.memory, args.masters, args.workDir, conf = conf)
rpcEnv.awaitTermination()
}
def startRpcEnvAndEndpoint(
host: String,
port: Int,
webUiPort: Int,
cores: Int,
memory: Int,
masterUrls: Array[String],
workDir: String,
workerNumber: Option[Int] = None,
conf: SparkConf = new SparkConf): RpcEnv = {
// The LocalSparkCluster runs multiple local sparkWorkerX RPC Environments
val systemName = SYSTEM_NAME + workerNumber.map(_.toString).getOrElse("")
val securityMgr = new SecurityManager(conf)
val rpcEnv = RpcEnv.create(systemName, host, port, conf, securityMgr)
val masterAddresses = masterUrls.map(RpcAddress.fromSparkURL(_))
rpcEnv.setupEndpoint(ENDPOINT_NAME, new Worker(rpcEnv, webUiPort, cores, memory,
masterAddresses, systemName, ENDPOINT_NAME, workDir, conf, securityMgr))
rpcEnv
}
Worker onStart方法调用
WorkUI
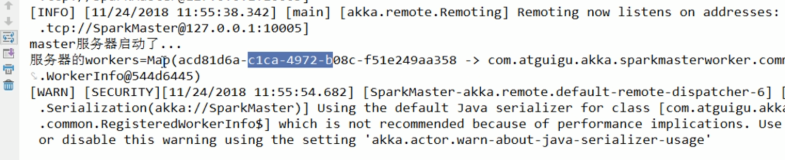
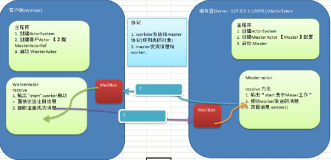
向所有master注册
- 线程池中每个master单独一个线程,向master注册worker
- worker通过 masterEndpoint.ask向master发送注册worker消息 : RegisterWorker
- master 接收到消息(RegisterWorker)处理后,回应worker消息 : RegisteredWorker
- worker收到RegisteredWorker消息后,进行 registered = true,和刷新内存中的master信息
override def onStart() {
assert(!registered)
logInfo("Starting Spark worker %s:%d with %d cores, %s RAM".format(
host, port, cores, Utils.megabytesToString(memory)))
logInfo(s"Running Spark version ${org.apache.spark.SPARK_VERSION}")
logInfo("Spark home: " + sparkHome)
createWorkDir()
shuffleService.startIfEnabled()
webUi = new WorkerWebUI(this, workDir, webUiPort)
webUi.bind()
val scheme = if (webUi.sslOptions.enabled) "https" else "http"
workerWebUiUrl = s"$scheme://$publicAddress:${webUi.boundPort}"
registerWithMaster()
metricsSystem.registerSource(workerSource)
metricsSystem.start()
// Attach the worker metrics servlet handler to the web ui after the metrics system is started.
metricsSystem.getServletHandlers.foreach(webUi.attachHandler)
}
private def registerWithMaster() {
// onDisconnected may be triggered multiple times, so don't attempt registration
// if there are outstanding registration attempts scheduled.
registrationRetryTimer match {
case None =>
registered = false
registerMasterFutures = tryRegisterAllMasters()
connectionAttemptCount = 0
registrationRetryTimer = Some(forwordMessageScheduler.scxheduleAtFixedRate(
new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
Option(self).foreach(_.send(ReregisterWithMaster))
}
},
INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS,
INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS,
TimeUnit.SECONDS))
case Some(_) =>
logInfo("Not spawning another attempt to register with the master, since there is an" +
" attempt scheduled already.")
}
}
private def registerWithMaster(masterEndpoint: RpcEndpointRef): Unit = {
masterEndpoint.ask[RegisterWorkerResponse](RegisterWorker(
workerId, host, port, self, cores, memory, workerWebUiUrl))
.onComplete {
// This is a very fast action so we can use "ThreadUtils.sameThread"
case Success(msg) =>
Utils.tryLogNonFatalError {
handleRegisterResponse(msg)
}
case Failure(e) =>
logError(s"Cannot register with master: ${masterEndpoint.address}", e)
System.exit(1)
}(ThreadUtils.sameThread)
}
private def handleRegisterResponse(msg: RegisterWorkerResponse): Unit = synchronized {
msg match {
case RegisteredWorker(masterRef, masterWebUiUrl) =>
logInfo("Successfully registered with master " + masterRef.address.toSparkURL)
registered = true
changeMaster(masterRef, masterWebUiUrl)
forwordMessageScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(SendHeartbeat)
}
}, 0, HEARTBEAT_MILLIS, TimeUnit.MILLISECONDS)
if (CLEANUP_ENABLED) {
logInfo(
s"Worker cleanup enabled; old application directories will be deleted in: $workDir")
forwordMessageScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(WorkDirCleanup)
}
}, CLEANUP_INTERVAL_MILLIS, CLEANUP_INTERVAL_MILLIS, TimeUnit.MILLISECONDS)
}
case RegisterWorkerFailed(message) =>
if (!registered) {
logError("Worker registration failed: " + message)
System.exit(1)
}
case MasterInStandby =>
// Ignore. Master not yet ready.
}
}