我是个幸运的人。虽然幸运不能被复制,但是眼光和努力可以。
关涛/关老板,80后的阿里P10,阿里巴巴通用计算平台负责人,阿里巴巴计算平台研究员。12年职场人生,微软和阿里的选择。
关涛的花名取自谐音:观涛。有种看海观涛的闲适,但在MaxCompute技术团队里,因为团队既要做核心技术也要“落地拿结果”承担阿里云的客户规模和营收,像一个小的创业公司,因此大家更喜欢叫他”关老板”,一下子就世俗亲近了起来。
关老板是个北方人,大高个也带着些书生气。因为工作的关系,带领着一支跨国团队,两岸四地奔波(太平洋两岸,北京、杭州、西雅图、加州),说话间偶尔喜欢中英文match一下。
“我是一个兴趣驱动型的人,职业生涯总的来说,还算挺幸运的,做自己感兴趣的事情,走上IT这一行……”
如果有认识关涛的人,应该会忍不住说上一句:这家伙,运势太好了吧。
一路保送,没考过什么试,大学选择计算机的原因也很任性,喜欢玩游戏。研究生毕业后就进入了微软,是微软最年轻的技术管理者之一,后来去了阿里云,不到3年时间,已经是P10,阿里巴巴通用计算平台MaxCompute团队负责人。
“特别久以前,大概初中的时候有了自己的第一台电脑,大名鼎鼎的486,带一个数学协处理器,主频266MHz,内存有4MB。”
喜欢玩游戏的都知道,往往会碰见有些关卡比较难,闯不过去的情况。当时的关涛就想着:怎么能够绕开系统这些设置?于是查了很多杂志也看了很多书,试图去改游戏存档,那个阶段他第一次知道什么是十六进制,也是最初接触编程。
最后自己折腾着,操纵游戏角色大杀四方,简直无敌。让程序按照自己的意愿运行的感觉,“嘿,还好玩的。”
于是,开始觉得这个专业(计算机)不错。到了高中毕业的时候,因为数学竞赛被保送到南开大学,当时的一个选择是可以进数学系,南开的王牌专业,但最后,关涛还是因为兴趣选择了计算机。
人生的分叉口有很多,有时候做了第1个选择,后面的路都会开始相通,看似顺势而为,其实都是选择的结果。
*从200公里的北京到8000多公里的西雅图
工作需要定期make a little change*
2006年,关涛毕业了。这意味他要开始自己的职业生涯了,他有些跃跃欲试。
研究生的3年,因为导师有额外要求:不能去实习,这让关涛对于招聘市场并不那么了解,对于微软同样是“没有太多的认知”。但北京有个MSRA,微软亚洲研究院,据说是当时最好的R&DCenter。
抱着试试看的心态,经历了一整天的面试后,关涛顺利地拿到了offer。 他回忆:“好像也不是那么难”。
在离家乡河北承德200公里远的北京,关涛一呆就是6年,是微软Bing搜索北京团队最初的几十个人之一。从偏存储层到计算层,在项目里不断地去充实自己。他是个兴趣驱动的人,但在工作中愿意变成完美主义者。
在微软的第一个项目,是做一个分布式KV+ObjectStore系统,用于支持Bing搜索的图片和视频存储。2006年,还没有Hbase这样的开源系统,当时6个人的小团队完全手写一套分布式KV,最终部署在3000台机器并支持正常线上流量,在实战中接触到了分布式系统中的各种挑战,也学到了非常多的东西。“这个项目,是个好的机会与开始”。
第二个项目是做搜索后台的IndexGen Pipeline:一个定制化的存储与计算系统,用于支持通用搜索100B级别的超大规模数据存储和处理,后来这个搜索后台也成为了微软Bing搜索后台的第二代架构,并服务至今。
再后来就是牵头来做大数据上交互式查询(JetScopeOn Cosmos),最后基本微软一半以上的团队都在用这个系统。
在关涛看来,不管是生活还是职业发展,定期去make a little change是很好的选择,保持新鲜感的同时,能看到学到更多的东西。从被别人带着写代码、到自己独立负责一些板块,再到自己带项目小组、带大一点的技术团队,这些都需要有一个自我时间界定,把握自己的发展节奏。
6年微软后,他也准备make a bigger change:申请去了美国西雅图的微软总部。
8000多公里以外的城市,冬天不太冷,夏天不太热,还有他最爱的单板滑雪,以至于一直坚持在每年的最后一天自驾去不同的滑雪地。
在美国期间,关涛继续深入做交互式查询、StructuredData优化推动等,也积累了很多跨国技术团队管理的经验。 “美国有近40年的历史,团队成员比北京的团队更资深一些,在美国能够看到不一样的人,看到不一样的项目。”
而在微软的10年时间里,关涛也关注到了国内以BAT为代表的本土企业,他们发展的很好,而且有更高的加速度……
*西雅图分部第22号员工
10年后的回归,面对更多的挑战*
“当时海外办公室刚建起来,我是阿里西雅图分部的第22号员工。”
“在微软10年,国内是什么情况?”好奇心不断膨胀,于是在一次偶然的机会,关涛跳去了阿里,成为了阿里巴巴通用计算平台MaxCompute团队里的一员。这是2016年1月。
MaxCompute的前身是ODPS,阿里内部统一的大数据平台,目前99%的数据存储以及95%的计算能力都在这个平台上产生,如果把阿里巴巴集团的数据体系比作航母战斗群,那么MaxCompute就是中间的航空母舰。
面对这样一个已经发展了近6年的相对成熟、体量极为庞大的平台,挑战非常多。而2016年1月入职阿里,2016年年会上就接过了MaxCompute的掌舵者位置,从0到1已经做完了,如何做到从1到10?留给关涛的时间并不多。
他认为,大型系统逐步发展,是一个不断自我进化的过程,大数据系统也不例外。
微软的经历给了他一些帮助:包括同样都是大数据引擎(规模上有较大差异),之前的技术和工程经验都能复用。而丰富的跨国技术团队管理经验也让关涛更加适应阿里的工作。
*从MaxCompute1.0到MaxCompute2.0
“我们是在飞行的飞机上换引擎”*
关涛回忆:“当时进来的时候,MaxCompute1.0 其实是在一个技术的成熟期上,承接了阿里巴巴内部和阿里云的核心业务,而引擎升级有技术风险和问题(我们称为Regression,包括功能和性能的)。为了保证对上层透明,我们先做了一个框架升级,支持把引擎的不同版本同时部署在线上,一点一点地把流量切过来,同时观察效果。”之后再进行引擎层面的大手术。
有点像是“在飞行的飞机上换引擎”。
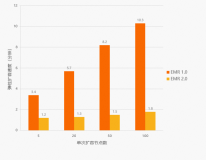
如今的MaxCompute2.0相较于1.0版本,规模达到近10万台,性能提升超过1倍以上,每年为阿里巴巴节省预算超过20亿,同时也让阿里的大数据引擎可以在未来3-5年架构上有个相对好的布局。
技术团队如何管理
关涛的看法是:技术管理者归根结底还是一个管理者。
1、首先考虑的不是自己要做什么事情而是帮助团队做什么事情,更多的有一种“利他”的责任感。
2、技术前瞻性,技术团队管理者是要带着团队有目标地、正确地往前走,把握未来方向非常重要。
3、招聘层面,思考如何招到合适的人,如何进行人才布局。现在是人才在哪办公地点就在哪的阶段。
从大数据角度看阿里双十一
要支持好双十一,先从两个统一说起(数据统一和资源统一)。
- 数据具有1+1大于2的特性,不同的数据融合计算能产生更大的价值。而关键就在于如何把数据都打通。
几年前阿里巴巴建设中台,把内部所有的数据放在一起(物理上分布在多地的近10万台服务器上,但逻辑上统一,数据的分布和调度对用户透明),让丰富的数据帮助产品、业务前进。
- 资源的统一化:把所有机器放在一个大的资源池里(内部称为混布项目),资源调度系统打通,对于机器的效率优化和整个系统的容灾都有非常大的帮助。
做大数据的都了解,数据可以3年翻5倍,机器却不行,否则成本太高,不现实。而利用已有的服务器进行混合部署,“这也是近一年,我们重点投资的一个项目,也就是把不同BU、不同种类的机器部署在同一个资源池中。”
有了这两个统一架构的前提,双十一在洪峰来临的时候,可以选择把不那么重要的工作先停掉(在百万级别的作业中基于优先级和依赖做调度),让这些机器都用来支撑洪峰。洪峰过后,又把机器主力转移到计算上,把需要的计算尽快地输出来。
今年双十一,大数据集群在流量洪峰最高的几个小时,通过弹性支持了超过1/4的交易业务流量。
不增加棋子,仅依靠挪动棋盘上的子,就完成布局守住将军。当然,在此之前,团队把MaxCompute已经从1.0版本切到了2.0版本,性能的提升也是支持双十一数据量的关键。
在硬件只增加不到三分之一的基础上,处理数据相较去年翻了一番,达到单日处理600PB的规模。可以说,MaxCompute在这一战役中发挥得不错,甚至比去年更为优秀。
**未来:云化、新硬件、非结构化计算、非关系型计算、AI是趋势
DBA或将被淘汰?**
去年的时候,原阿里云总裁胡晓明说:“互联网的云计算竞争是世界寡头经济的全面竞争,在我看来,就是杭州和西雅图的竞争。谁拥抱技术,谁就拥抱未来。”场主深以为然。
关涛认为:目前云计算已经从互联网企业向传统企业蔓延,例如杭州的城市大脑和“最多跑一次“项目,是2G(To Government)的项目。还有基于工业大脑的工业4.0项目等。
从目前的市场态度来看,企业或许可以更加开放一些,欢迎和拥抱这种技术变化,完成自我的数字化转型。“云计算不会是寡头反而会是普惠”,关涛说。
前瞻话题:大数据处理领域,未来程序员应该关注什么东西?
1、 新硬件的发展
计算层面越来越与新硬件的创新紧密结合,硬件会带来平台革命。例如芯片类的CPU(AVX、SIMD)、ARM众核架构、GPU,FPGA,ASIC,存储类的NVM、SSD、SRM,网络类的智能网卡和RDMA等新硬件的发展,新硬件与软件的配合是值得关注的发展方向。
2、 非关系型计算领域(图计算)有很多机会
大数据现在还是在关系型的处理层面,包括流和批都是基于关系型数据的计算,事实上,现在非关系的计算越来越流行了,包括知识图谱、画像等越来越有价值,这些数据组织不是关系型表达,而是以点边的形式用图的方式表达,更符合物理抽象,比如人和货的关系,在风控层面,知识图谱层面,用来描述物理实体的关系更合适。
明年初,将会推出MaxCompute的图计算系统MaxGraph,支持图存储、查询、模式匹配和GraphEmbedding等机器学习运算。
3、 非结构化数据将变成大数据的主流
越来越多的短视频、图片、语音类数据,并随着IoT的发展,可能占据80%的数据量,由于这类数据的特性在于结构各不相同,且数据非常大但是单位价值不高(相比传统结构化数据),如何快速高效的解析和处理非结构化数据,是计算平台的关键挑战。
去年的时候MaxCompute发布了一个非结构化数据处理模块,能够用户自定义的方式处理包括视频音频在内的数据。
4、 Al for Everything(also for BigData)
DBA或将被淘汰?
大数据的特点是大,不仅仅是包括数据的处理规模,还包括了整个的海量数据的管理和优化。传统数据库领域依靠DBA人力去管理的模式将不再适用。
用Al优化数据分布、数据管理、做计算优化和成本优化(例如自动SubQuery合并,智能索引建立等)。“让大数据无人驾驶”,这也是未来的趋势。

注:想了解更多关老板和MaxCompute技术团队小伙伴在做的阿里巴巴大数据计算服务MaxCompute,可以加入社群一起交流。

欢迎关注养码场

本文来自养码场专访,转发需养码场授权。