字符串编码在Python里边是经常会遇到的问题,特别是写文件以及网络传输的过程中,当调用某些函数的时候经常会遇到一些字符串编码提示错误,所以有必要弄清楚这些编码到底在搞什么鬼。

我们都知道计算机只能处理数字,文本转换为数字才能处理。计算机中8个bit作为一个字节,所以一个字节能表示最大的数字就是255。计算机是美国人发明的,而英文中涉及的编码并不多,一个字节可以表示所有字符了,所以ASCII(American national Standard Code for Information Interchange,美国国家标准信息交换码)编码就成为美国人的标准编码。但是我们都知道中文的字符肯定不止255个汉字,使用ASCII编码来处理中文显然是不够的,所以中国制定了GB2312编码,用两个字节表示一个汉字,碰到及其特殊的情况,还会用三个字节来表示一个汉字。GB2312还把ASCII包含进去了。同理,日文,韩文等上百个国家为了解决这个问题发展了一套自己的编码,于是乎标准越来越多,如果出现多种语言混合显示就一定会出现乱码。那么针对这种编码“乱象”,Unicode便应运而生了,其将所有语言统一到一套编码规则里。

Unicode有许多种编码,比如说可以通过16个bit或者32个bit来把所有语言统一到一套编码里。举个栗子,字母A用ASCII编码的十进制为65,二进制为0100 0001;汉字“中”已经超出了ASCII编码的范围,用unicode编码是20013,二进制是01001110 00101101;A用unicode编码只需要前面补0,二进制是00000000 0100 0001。可以看出,unicode不仅解决了ASCII码本身的编码问题,还解决了超出ASCII编码范围之外的其他国家字符编码的统一问题。
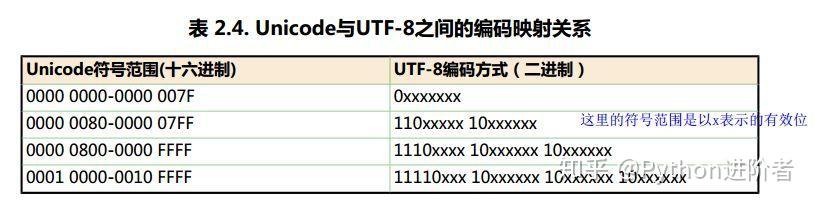
虽然unicode编码能做到将不同国家的字符进行统一,使得乱码问题得以解决,但是如果内容全是英文unicode编码比ASCII编码需要多一倍的存储空间,同时如果传输需要多一倍的传输。当传输文件比较小的时候,内存资源和网络带宽尚能承受,当文件传输达到上TB的时候,如果 “硬”传,则需要消耗的资源就不可小觑了。为了解决这个问题,一种可变长的编码“utf-8”就应运而生了,把英文变长1个字节,汉字3个字节,特别生僻的变成4-6个字节,如果传输大量的英文,utf8的作用就很明显了。

不过正是因为utf-8编码的可变长,一会儿一个字符串是占用一个字节,一会儿一个字符串占用两个字节,还有的占用三个及以上的字节,导致在内存中或者程序中变得不好琢磨。unicode编码虽然占用内存空间,但是在编程过程中或者在内存处理的时候会比utf-8编码更为简单,因为它始终保持一样的长度,一样的长度对于内存和代码来说,它的处理就会变得更加简单。所以utf-8编码在做网络传输和文件保存的时候,将unicode编码转换成utf-8编码,才能更好的发挥其作用;当从文件中读取数据到内存中的时候,将utf-8编码转换为unicode编码,亦为良策。
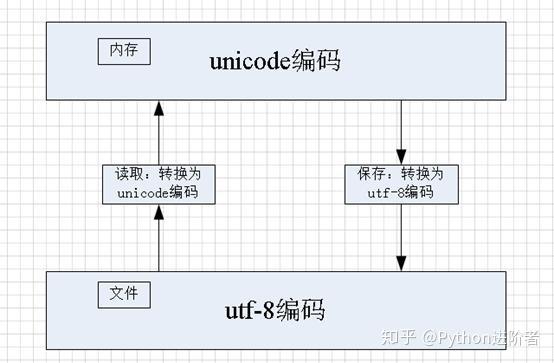
如上图所示,当需要在内存中读取文件的时候,此时将utf-8编码的内存转换为unicode编码,在内存中进行统一处理;当需要保存文件的时候,出于空间和传输效率的考虑,此时将unicode编码转换为utf-8编码。在Python中进行读取和保存文件的时候,必须要显示的指定文件编码,其余的事情就交给Python的相关库去处理就可以了。
小伙伴们,了解了这些基础知识之后,接下来对Python中的字符串编码问题的理解就轻松的多了。