版权声明:本文为博主原创文章,未经博主允许不得转载。欢迎访问我的博客 https://blog.csdn.net/smooth00/article/details/73498125
本文以Loadrunner的Java_Vuser脚本为例,来做一个简化版的自动化测试框架(以excel作为数据驱动),实现批量更新Oracle业务数据库的目的,通过本文例子我们还可以实现将Loadrunner由性能测试工具,转换成一个接口自动化测试工具(Loadrunner的多用户和循环action脚本模式,是多么类似单元测试工具的Test Case调用,既@Test模式)。
1、在loadrunner中新建脚本(本文以LoadRunner11为例),要求选择协议类型为Java->Java Vuser
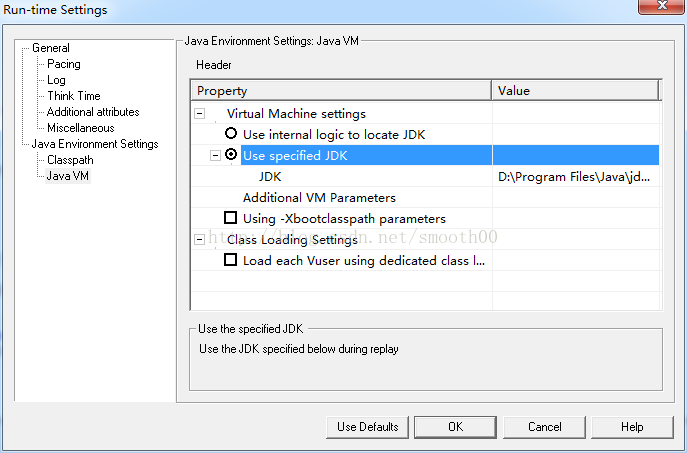
2、在Run-time Settings设置JDK路径,由于LoadRunner11不支持jdk1.8,本次测试是拷贝了一份低版本的JDK1.6,所以路径选择固定路径模式,如下所示:
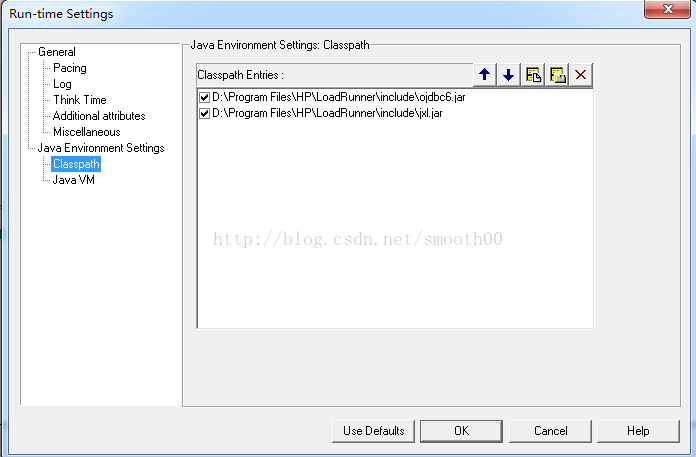
3、上网下载一份Oracle的JAR包和jxl的JAR包(官网和网上都能搜到),我已经把两包加上mysql的驱动包都放一起,有兴趣的可以直接下载:http://download.csdn.net/detail/smooth00/9875368,将JAR包放到Loadrunner的include目录下或其它指定目录下,并在Run-time Settings中配置Classpath
4、建立excel文件(要求另存为Excel97-2003的文件格式,保存的路径是在LR脚本目录下新建一个目录DataSource,将excel放到这个目录下),并按以下数据格式创建参数表(每个Sheet以真实表命名,colName是表的字段表,colValue是要更新的字段值):

5、在Loadrunner中以Java Vuser协议创建脚本,脚本样例如下:
/*
* LoadRunner Java script. (Build: _build_number_)
*
* Script Description:
*
*/
import java.io.File;
import java.io.IOException;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.HashMap;
import jxl.Cell;
import jxl.read.biff.BiffException;
import jxl.Sheet;
import jxl.Workbook;
import lrapi.lr;
public class Actions
{
//设定数据库驱动,数据库连接地址、端口、名称,用户名,密码
String driverName="oracle.jdbc.OracleDriver";
String url="jdbc:oracle:thin:@172.16.1.65:1521:orcl"; //orcl为数据库名称,1521为连接数据库的默认端口
String user="test"; //用户名
String password="123456"; //密码
PreparedStatement pstmt = null;
ResultSet rs = null;
//数据库连接对象
Connection conn = null;
//
public Workbook workbook;
public Sheet sheet;
public Cell cell;
int rows;
int columns;
//public String fileName;
//public String caseName;
public ArrayList<String> arrkey = new ArrayList<String>();
static String sourceFile;
public void connection(){//连接Oracle数据库
try {
//反射Oracle数据库驱动程序类
Class.forName(driverName);
//获取数据库连接
conn = DriverManager.getConnection(url, user, password);
//输出数据库连接
System.out.println(conn);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
public void deconnection(){//断开数据库连接
try{
if(rs != null){
rs.close();
}
if(pstmt != null){
pstmt.close();
}
if(conn != null){
conn.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 以HashMap获得excel表中的数据
* @caseName Excel的Sheet名
* @fileName Excel的文件名
*/
public Object[][] getExcelData(String caseName,String fileName) throws BiffException, IOException {
workbook = Workbook.getWorkbook(new File(getPath(fileName)));
sheet = workbook.getSheet(caseName);
rows = sheet.getRows();
columns = sheet.getColumns();
// 为了返回值是Object[][],定义一个多行单列的二维数组
HashMap<String, String>[][] arrmap = new HashMap[rows - 1][1];
// 对数组中所有元素hashmap进行初始化
if (rows > 1) {
for (int i = 0; i < rows - 1; i++) {
arrmap[i][0] = new HashMap<String, String>();
}
} else {
System.out.println("excel中没有数据");
}
// 获得首行的列名,作为hashmap的key值
for (int c = 0; c < columns; c++) {
String cellvalue = sheet.getCell(c, 0).getContents();
arrkey.add(cellvalue);
}
// 遍历所有的单元格的值添加到hashmap中
for (int r = 1; r < rows; r++) {
for (int c = 0; c < columns; c++) {
String cellvalue = sheet.getCell(c, r).getContents();
arrmap[r - 1][0].put(arrkey.get(c), cellvalue);
}
}
return arrmap;
}
/**
* 获得excel文件的路径
* @return
* @throws IOException
*/
public String getPath(String fileName) throws IOException {
File directory = new File(".");
sourceFile = directory.getCanonicalPath() + "\\DataSource\\"
+ fileName + ".xls";
return sourceFile;
}
/**
* 以ArrayList格式获得excel表中的数据
* @caseName Excel的Sheet名
* @fileName Excel的文件名
*/
public ArrayList<String> GetExcelParameter(String caseName,String fileName){
ArrayList<String> parameters = new ArrayList<String>();
try {
Workbook workbook = Workbook.getWorkbook(new File(getPath(fileName)));
Sheet sheet = workbook.getSheet(caseName);
for (int i = 1; i < sheet.getRows(); i++) {//不包括第一行
for (int j = 0; j < sheet.getColumns(); j++) {
parameters.add(sheet.getCell(j, i).getContents());
System.out.println(parameters.get(j)+" ");
}
}
} catch (BiffException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return parameters;
}
/**
* 批量更新表中的指定字段(excel中每个Sheet是一张表,Sheet名与表名同名,第一列ID序号,第二列字段名,第三列是需要更新的字段值)
* @TableName Excel的Sheet名(设置成与数据表同名)
* @ColumnIDs 需要修改的字段名,用@分隔不同字段
* @fileName Excel的文件名
*/
public void updateField(String TableName,String ColumnIDs,String fileName){
try{
Workbook workbook = Workbook.getWorkbook(new File(getPath(fileName)));
Sheet sheet = workbook.getSheet(TableName);
String[] ColumnID=ColumnIDs.split("@");
String update_sql="update "+TableName+" Set ";
for(int k=0;k <ColumnID.length ; k++){
for (int i = 1; i < sheet.getRows(); i++) {//不包括第一行
String ColumnName=sheet.getCell(1, i).getContents();
String ColumnNameValue=sheet.getCell(2, i).getContents();
//lr.output_message("The parameter1's value is "+ColumnName+" "+ColumnID[i]);
if(ColumnName.equals(ColumnID[k])){
if(k==ColumnID.length-1)
update_sql+=ColumnName+"='"+ColumnNameValue+"' WHERE ROWNUM<=10";//修改前10条
else
update_sql+=ColumnName+"='"+ColumnNameValue+"',";
//lr.output_message("The parameter1's value is "+ColumnName);
break;
}
}
}
System.out.println("【" + update_sql + "】");
//创建该连接下的PreparedStatement对象
pstmt = conn.prepareStatement(update_sql);
//循环获取ResultSet对象中信息
rs = pstmt.executeQuery();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 批量修改指定Sheet(指定表名)中的字段,按照表中第一条记录更新第一个字段,第二条记录更新第二个字段,以此类推
* @TableName Excel的Sheet名(设置成与数据表同名)
* @fileName Excel的文件名
*/
public void updateData(String TableName,String fileName){
try{
Workbook workbook = Workbook.getWorkbook(new File(getPath(fileName)));
Sheet sheet = workbook.getSheet(TableName);
String update_sql=null;
for (int i = 1; i < sheet.getRows(); i++) {//不包括第一行
PreparedStatement pstmt2 = null; //将数据集定义PreparedStatement放到for循环内,效率不高,但为了避免游标数超限,只能这么做
ResultSet rs2 = null;
String ColumnName=sheet.getCell(1, i).getContents();
String ColumnNameValue=sheet.getCell(2, i).getContents();
update_sql="update "+TableName+" Set "+ColumnName+"='"+ColumnNameValue+"' where rowid in ( Select rid from (Select Rownum r_n,rowid rid,a.* from "+TableName+" a)where r_n="+i+")";//修改第i条
System.out.println("【" + update_sql + "】");
//创建该连接下的PreparedStatement对象
pstmt2 = conn.prepareStatement(update_sql);
//循环获取ResultSet对象中信息
rs2 = pstmt2.executeQuery();
if(rs2 != null){
rs2.close();
}
if(pstmt2 != null){
pstmt2.close();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 循环调用整个excel中的不同Sheet参数表,并按上一函数的要求更新数据
* @fileName Excel的文件名
*/
public void updateData(String fileName){
try{
Workbook workbook = Workbook.getWorkbook(new File(getPath(fileName)));
Sheet[] sheets = workbook.getSheets();// 获取所有的sheet
String sheetname = null;
for (int x = 0; x < sheets.length; x++) {
Sheet sheet = workbook.getSheet(x);// 获取sheet
if(sheet.getName().toString().indexOf("Sheet")!=-1){//循环到以Sheet命名的附表则退出
break;
}else{
updateData(sheet.getName());
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
public int init() throws Throwable {
connection();
return 0;
}//end of init
public int action() throws Throwable {
//Object[][] getExcelOb=getExcelData("GTDJ_BGSX_LC","DataTable");
//System.out.println("【" + getExcelOb + "】");
//ArrayList<String> gextExcelPa=GetExcelParameter("GTDJ_BGSX_LC","DataTable");
//System.out.println("【" + gextExcelPa + "】");
// -----------------------------------------------------------------------------
//updateField("GTDJ_BGSX_LC","RECID@OPENO@PRIPID@ALTITEM","DataTable");//修改指定字段,用@分隔字段名
//updateData("GTDJ_BGSX_LC","DataTable");//修改不同的字段-每条记录只改一个字段(指定表名)
updateData("DataTable");//修改excel所有表的不同字段-每条记录只改一个字段
//--------------------------------------------------------------------------
return 0;
}//end of action
public int end() throws Throwable {
deconnection();
return 0;
}//end of end
}
