
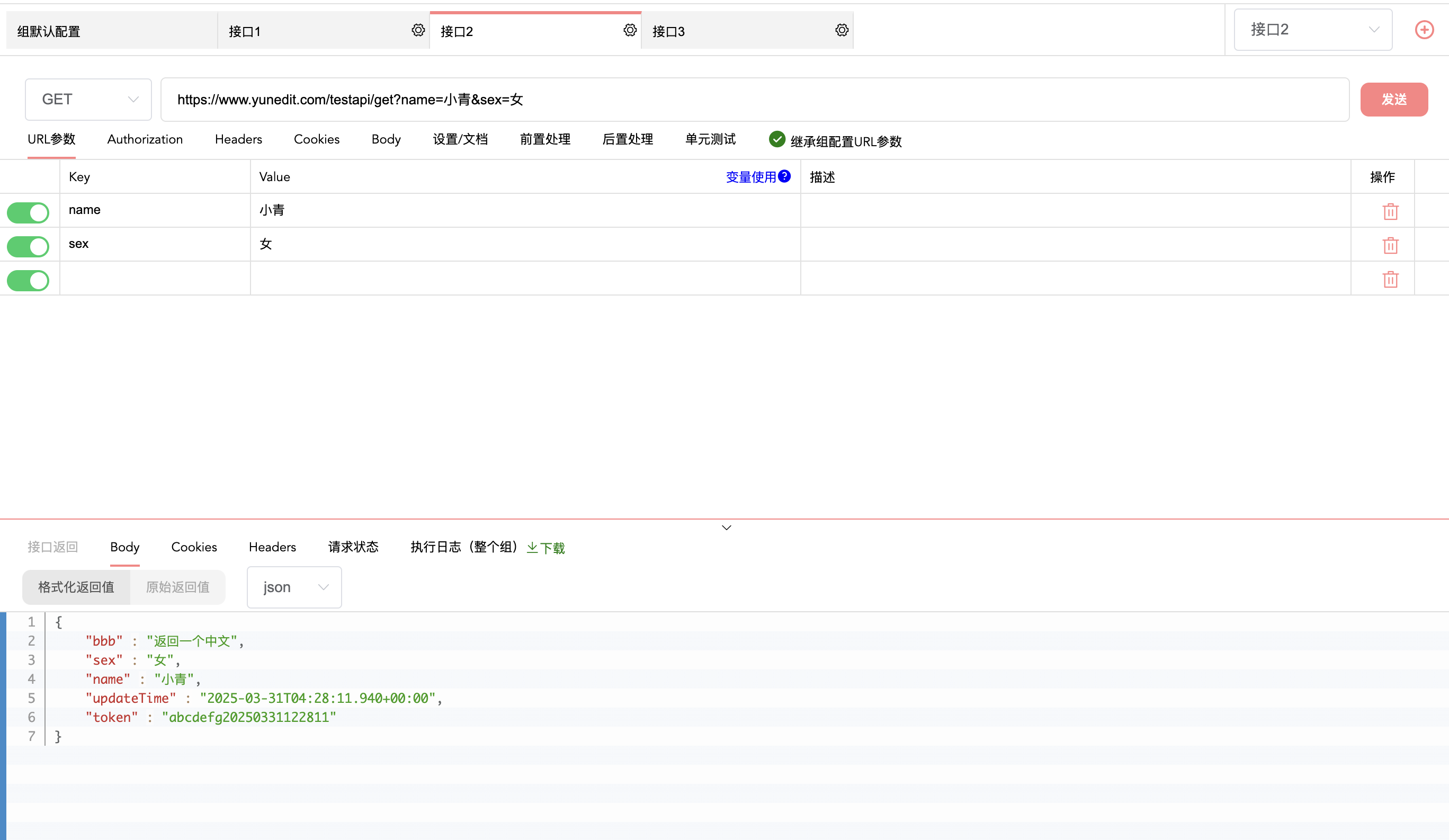
《深度探索:运用游标遍历数据库树形结构数据的艺术》























你好,我是AI助理
可以解答问题、推荐解决方案等
