▌1:极简缓存架构
通过JSR107规范,我们将框架定义为客户端层、缓存提供层、缓存管理层、缓存存储层。其中缓存存储层又分为基本存储层、LRU存储层和Weak存储层,如下图所示。
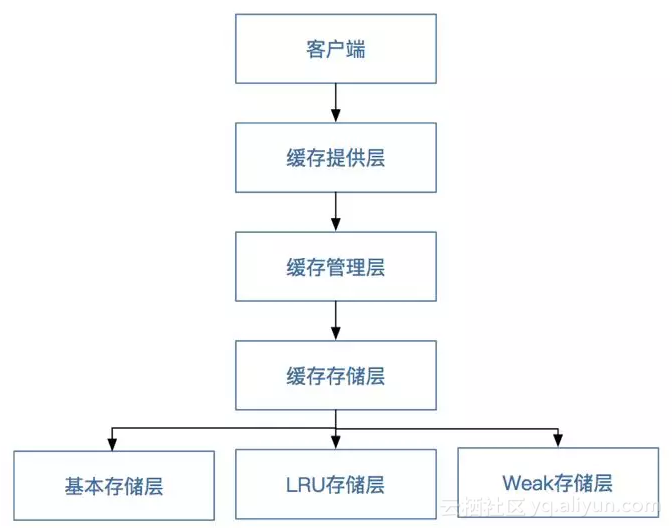
缓存分层图
其中:
● 缓存管理层:主要对缓存客户端的生命周期进行维护,负责缓存客户端的创建,保存、获取以及销毁
● 缓存存储层:负责数据以什么样的形式进行存储。
● 基本存储层:是以普通的ConcurrentHashMap为存储核心,数据不淘汰。
● LRU存储层:是以最近最少用为原则进行的数据存储和缓存淘汰机制。
● Weak存储层:是以弱引用为原则的数据存储和缓存淘汰机制。
▌2:容量评估
缓存系统主要消耗的是服务器的内存,因此,在使用缓存时必须先对应用需要缓存的数据大小进行评估,包括缓存的数据结构、缓存大小、缓存数量、缓存的失效时间,然后根据业务情况自行推算在未来一定时间内的容量的使用情况,根据容量评估的结果来申请和分配缓存资源,否则会造成资源浪费或者缓存空间不够。
▌3:业务分离
建议将使用缓存的业务进行分离,核心业务和非核心业务使用不同的缓存实例,从物理上进行隔离,如果有条件,则请对每个业务使用单独的实例或者集群,以减小应用之间互相影响的可能性。笔者就经常听说有的公司应用了共享缓存,造成缓存数据被覆盖以及缓存数据错乱的线上事故。
▌4:监控为王
所有的缓存实例都需要添加监控,这是非常重要的,我们需要对慢查询、大对象、内存使用情况做可靠的监控。
▌5:失效时间
任何缓存的key都必须设定缓存失效时间,且失效时间不能集中在某一点,否则会导致缓存占满内存或者缓存雪崩。
▌6:大量key同时失效时间的危害
在使用缓存时需要进行缓存设计,要充分考虑如何避免常见的缓存穿透、缓存雪崩、缓存并发等问题,尤其是对于高并发的缓存使用,需要对key的过期时间进行随机设置,例如,将过期时间设置为10秒+random(2),也就是将过期时间随机设置成10~12秒。
笔者曾经见过一个case:在应用程序中对使用的大量缓存key设置了同一个固定的失效时间,当缓存失效时,会造成在一段时间内同时访问数据库,造成数据库的压力较大。
▌7:先更新数据库后更新缓存有啥问题?
想象一下,如果两个线程同时执行更新操作,线程1更新数据库后,线程2也更新了数据库,然后开始写缓存,但线程2先执行了更新缓存的操作,而线程1在执行更新缓存的时候就把线程2更新的数据给覆盖掉了,这样就会出现数据不一致。
▌8:先删缓存, 行不行?
“先删缓存,然后执行数据库事务”也有人讨论这种方案,不过这种操作对于如商品这种查询非常频繁的业务不适用,因为在你删缓存的同时,已经有另一个系统来读缓存了,此时事务还没有提交。当然对于如用户维度的业务是可以考虑的。
▌9:数据库和缓存数据一致性
京东采用了通过canal更新缓存原子性的方法,如下图所示。
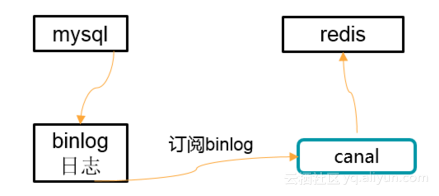
最终一致性方案
几个关注点:
更新数据时使用更新时间戳或者版本对比。
使用如canal订阅数据库binlog;此处把mysql看成发布者,binlog是发布的内容,canal(canal 是阿里巴巴mysql数据库binlog的增量订阅&消费组件)看成消费者,canal订阅binlog然后更新到Redis。
将更新请求按照相应的规则分散到多个队列,然后每个队列的进行单线程更新,更新时拉取最新的数据保存;更新之前获取相关的锁再进行更新。
▌10.先更新数据库,再删除缓存的一种实践
流程如下图所示:
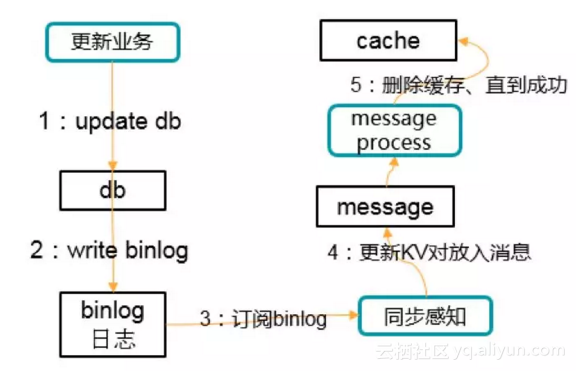
过程不赘述,只强调一个,数据库update变更会同步发到消息,通过消息去删除缓存。如果删除失败,消息有重试机制保障。另外除了极端情况,缓存更新是比较及时的。
▌11:本地缓存的挑战
如果对性能的要求不是非常高,则尽量使用分布式缓存,而不要使用本地缓存,因为本地缓存在服务的各个节点之间复制,在某一时刻副本之间是不一致的,如果这个缓存代表的是开关,而且分布式系统中的请求有可能会重复,就会导致重复的请求走到两个节点,一个节点的开关是开,一个节点的开关是关,如果请求处理没有做到幂等,就会造成处理重复,在严重情况下会造成资金损失。
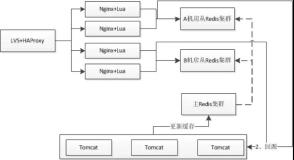
▌12:缓存热点与多级缓存
对于分布式缓存,我们需要在Nginx+Lua应用中进行应用缓存来减少Redis集群的访问冲击;即首先查询应用本地缓存,如果命中则直接缓存,如果没有命中则接着查询Redis集群、回源到Tomcat;然后将数据缓存到应用本地。如同14-8所示。
此处到应用Nginx的负载机制采用:正常情况采用一致性哈希,如果某个请求类型访问量突破了一定的阀值,则自动降级为轮询机制。另外对于一些秒杀活动之类的热点我们是可以提前知道的,可以把相关数据预先推送到应用Nginx并将负载均衡机制降级为轮询。
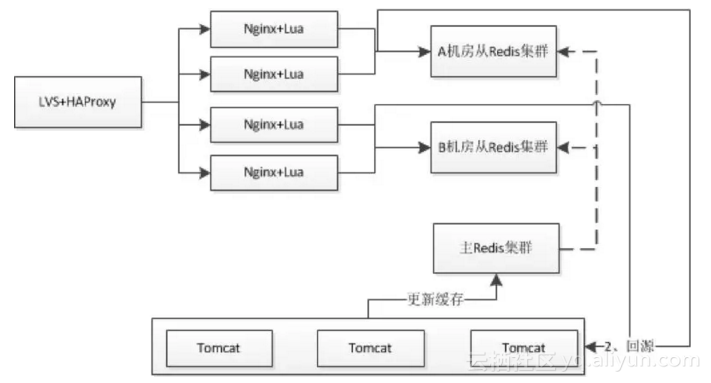
分布式缓存方案
另外可以考虑建立实时热点发现系统来发现热点,如下图所示:
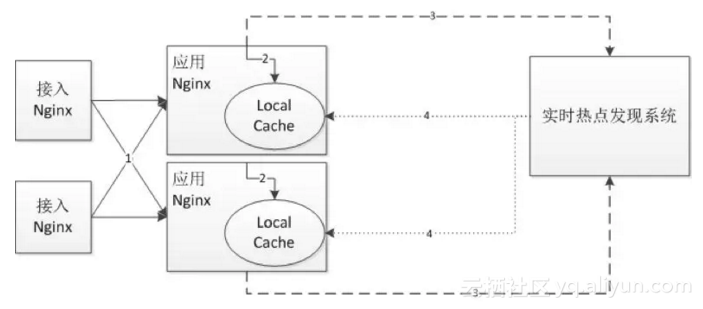
实时热点发现方案
1)接入Nginx将请求转发给应用Nginx;
2)应用Nginx首先读取本地缓存;如果命中直接返回,不命中会读取分布式缓存、回源到Tomcat进行处理;
3)应用Nginx会将请求上报给实时热点发现系统,如使用UDP直接上报请求、或者将请求写到本地kafka、或者使用flume订阅本地nginx日志;上报给实时热点发现系统后,它将进行统计热点(可以考虑storm实时计算);
4)根据设置的阀值将热点数据推送到应用Nginx本地缓存。
因为做了本地缓存,因此对于数据一致性需要我们去考虑,即何时失效或更新缓存:
1)如果可以订阅数据变更消息,那么可以订阅变更消息进行缓存更新;
2)如果无法订阅消息或者订阅消息成本比较高,并且对短暂的数据一致性要求不严格(比如在商品详情页看到的库存,可以短暂的不一致,只要保证下单时一致即可),那么可以设置合理的过期时间,过期后再查询新的数据;
3)如果是秒杀之类的,可以订阅活动开启消息,将相关数据提前推送到前端应用,并将负载均衡机制降级为轮询;
4)建立实时热点发现系统来对热点进行统一推送和更新。
应对缓存大热点:数据复制模式
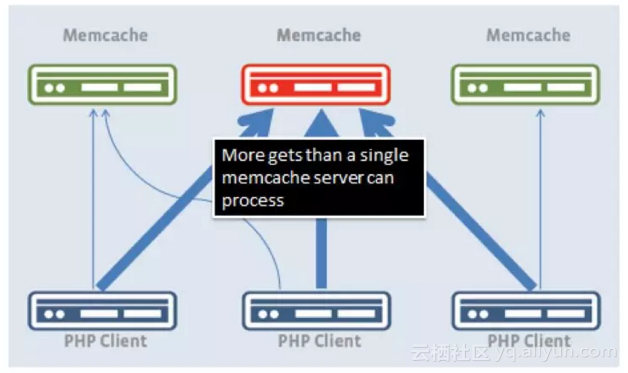
在Facebook有一招,就是通过多个key_index(key:xxx#N) 来解决数据的热点读问题。解决方案是所有热点key发布到所有web服务器;每个服务器的key有对应别名,可以通过client端的算法路由到某台服务器;做删除动作时,删除所有的别名key。可简单总结为一个通用的group内一致模型。把缓存集群划分为若干分组(group),在同组内,所有的缓存服务器,都发布热点key的数据。
对于大量读操作而言,通过client端路由策略,随意返回一台机器即可;而写操作,有一种解法是通过定时任务来写入;Facebook采取的是删除所有别名key的策略。如何保障这一个批量操作都成功?
(1)容忍部分失败导致的数据版本问题
(2)只要有写操作,则通过定时任务刷新缓存;如果涉及3台服务器,则都操作成功代表该任务表的这条记录成功完成使命,否则会重试。
▌13:缓存失效的连接风暴
引起这个问题的主要原因还是高并发的时候,平时我们设定一个缓存的过期时间时,可能有一些会设置1分钟,5分钟,并发很高可能会出在某一个时间同时生成了很多的缓存,并且过期时间都一样,这个时候就可能引发过期时间到后,这些缓存同时失效,请求全部转发到DB,DB可能会压力过重。那如何解决这些问题呢?
其中的一个简单方案就是将缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
如果缓存集中在一段时间内失效,DB的压力凸显。这个没有完美解决办法,但可以分析用户行为,尽量让失效时间点均匀分布。
上述是缓存使用过程中经常遇到的并发穿透、并发失效问题。一般情况下,我们解决这些问题的方法是,引入空值、锁和随机缓存过期时间的机制。
▌14:缓存预热
提前把数据读入到缓存的做法就是数据预热处理。数据预热处理要注意一些细节问题:
(1)是否有监控机制确保预热数据都写成功了!笔者曾经遇到部分数据成功而影响高峰期业务的案例;
(2)数据预热配备回滚方案,遇到紧急回滚时便于操作。对于新建cache server集群,也可以通过数据预热模式来做一番手脚。如下图所示,先从冷集群中获取key,如果获取不到,则从热集群中获取。同时把获取到的key put到冷集群。如下图
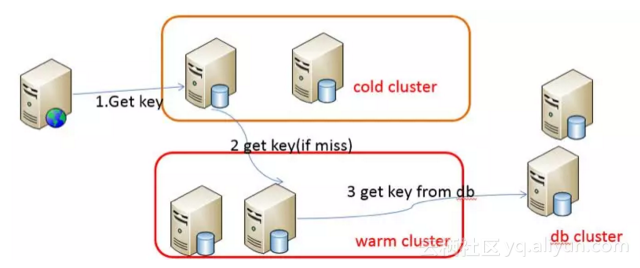
数据预热
(3)预热数据量的考量,要做好容量评估。在容量允许的范围内预热全量,否则预热访问量高的。
(4)预热过程中需要注意是否会因为批量数据库操作或慢sql等引发数据库性能问题。
▌15:超时时间设计
在使用远程缓存(如Redis、Memcached)时,一定要对操作超时时间进行设置,这是非常关键的,一般我们设计缓存作为加速数据库读取的手段,也会对缓存操作做降级处理,因此推荐使用更短的缓存超时时间,如果一定要给出一个数字,则希望是100毫秒以内。
笔者曾经遇到过一个案例:某个正常运行的应用突然报警线程数过高,之后很快就出现了内存溢出。
分析原因为:由于缓存连接数达到最大限制,应用无法连接缓存,并且超时时间设置得较大,导致访问缓存的服务都在等待缓存操作返回,由于缓存负载较高,处理不完所有的请求,但是这些服务都在等待缓存操作返回,服务这时在等待,并没有超时,就不能降级并继续访问数据库。这在BIO模式下线程池就会撑满,使用方的线程池也都撑满;在NIO模式下一样会使服务的负载增加,服务响应变慢,甚至使服务被压垮。
▌16:不要把缓存到存储
大家都知道一个颠扑不破的真理:在分布式架构下,一切系统都可能fail,无论是缓存、存储包括数据库还是应用服务器,而且部分缓存本身就未提供持久化机制比如memcached。即使使用持久化机制的cache,也要慎用,如果作为唯一存储的话。
▌17:缓存崩溃解决之道
当我们使用分布式缓存时,应该考虑如何应对其中一部分缓存实例宕机的情况。接下来部分将介绍分布式缓存时的常用算法。而当缓存数据是可丢失的情况时,我们可以选择一致性哈希算法。
-
取模
对于取模机制如果其中一个实例坏了,如果摘除此实例将导致大量缓存不命中,瞬间大流量可能导致后端DB/服务出现问题。对于这种情况可以采用主从机制来避免实例坏了的问题,即其中一个实例坏了可以那从/主顶上来。但是取模机制下如果增加一个节点将导致大量缓存不命中,一般是建立另一个集群,然后把数据迁移到新集群,然后把流量迁移过去。
-
一致性哈希
对于一致性哈希机制如果其中一个实例坏了,如果摘除此实例将只影响一致性哈希环上的部分缓存不命中,不会导致瞬间大量回源到后端DB/服务,但是也会产生一些影响。
▌18. 缓存崩溃后的快速恢复
如果出现之前说到的一些问题,可以考虑如下方案:
1)主从机制,做好冗余,即其中一部分不可用,将对等的部分补上去;
2)如果因为缓存导致应用可用性已经下降可以考虑:
● 部分用户降级,然后慢慢减少降级量;
● 后台通过Worker预热缓存数据。
也就是如果整个缓存集群坏了,而且没有备份,那么只能去慢慢将缓存重建;为了让部分用户还是可用的,可以根据系统承受能力,通过降级方案让一部分用户先用起来,将这些用户相关的缓存重建;另外通过后台Worker进行缓存数据的预热。
▌19. 开启Nginx Proxy Cache性能不升反降
开启Nginx Proxy Cache后,性能下降,而且过一段内存使用率到达98%;解决方案:
1)对于内存占用率高的问题是内核问题,内核使用LRU机制,本身不是问题,不过可以通过修改内核参数:
sysctl -wvm.extra_free_kbytes=6436787
sysctl -wvm.vfs_cache_pressure=10000
2)使用Proxy Cache在机械盘上性能差可以通过tmpfs缓存或nginx共享字典缓存元数据,或者使用SSD,我们目前使用内存文件系统。
▌20:“网络抖动时,返回502错误”缘于timeout
Twemproxy配置的timeout时间太长,之前设置为5s,而且没有分别针对连接、读、写设置超时。后来我们减少超时时间,内网设置在150ms以内,当超时时访问动态服务。
▌21:应对恶意刷的经验
商品详情页库存接口2014年被恶意刷,每分钟超过600w访问量,tomcat机器只能定时重启;因为是详情页展示的数据,缓存几秒钟是可以接受的,因此开启nginxproxy cache来解决该问题,开启后降到正常水平;后来我们使用Nginx+Lua架构改造服务,数据过滤、URL重写等在Nginx层完成,通过URL重写+一致性哈希负载均衡,不怕随机URL,一些服务提升了10%+的缓存命中率。
▌22:网卡打满了咋办?
用Redis都有个很头疼的问题,就是Redis的网卡打满问题,由于Redis的性能很高,在大并发请求下,很容易将网卡打满.通常情况下,1台服务器上都会跑几十个Redis实例 ,一旦网卡打满,很容易干扰到应用层可用性.所以我们基于开源的Contiv netplugin项目,限制了网卡的使用, 主要功能是提供基于Policy的网络和存储管理。Contiv比较“诱人”的一点就是,它的网络管理能力,既有L2(VLAN)、L3(BGP),又有 Overlay(VxLAN),有了它就可以无视底层的网络基础架构,向上层容器提供一致的虚拟网络了。最主要的一点是,既满足了业务场景,又兼容了以往的网络架构。在转发性能上,它能接近物理网卡的性能,特别在没有万兆网络的老机房也能很好的使用。在网络流量监控方面,我们通过使用ovs的sflow来抓取宿主机上所有的网络流量,然后自开发了一个简单的sflow Collecter, 服务器收到sflow的数据包进行解析,筛选出关键数据,然后进行汇总分析,得到所需要的监控数据。通过这个定制的网络插件,我们可以随意的控制某个Redis的流量,流量过大,也不会影响其他的项目,而如果某个服务器上的Redis流量很低,我们也可以缩小它的配额,提供给本机其他需要大流量的程序使用,这些,通过后台的监控程序,可以实现完全自动化。
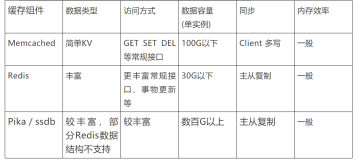
▌23:缓存组件的选择
缓存的种类很多,我们实际使用时,需要根据缓存位置(系统前后端)、待存数据类型、访问方式、内存效率等情况来选择最适合的缓存组件。本小节接下来将主要探讨在应用层后端如何选择分布式缓存组件。
一般业务系统中,大部分数据都是简单KV数据类型,如前述微博Feed系统中的feed content、feed列表、用户信息等。这些简单类型数据只需要进行set、get、delete操作,不需要在缓存端做计算操作,最适合以memcached作为缓存组件。
其次对于需要部分获取、事物型变更、缓存端计算的集合类数据,拥有丰富数据结构和访问接口的Redis 也许会更适合。Redis还支持以主从(master-slave)方式进行数据备份,支持数据的持久化,可以将内存中的数据保持在磁盘,重启时再次加载使用。因磁盘缓存(diskstore)方式的性能问题,Redis数据基本只适合保存在内存中,由此带来的问题是:在某些业务场景,如果待缓存的数据量特别大,而数据的访问量不太大或者有冷热区分,也必须将所有数据全部放在内存中,缓存成本(特别是机器成本)会特别高。如果业务遇到这种场景,可以考虑用pika、ssdb等其他缓存组件。pika、ssdb都兼容Redis协议,同时采用多线程方案,支持持久化和复制,单个缓存实例可以缓存数百G的数据,其中少部分的热数据存放内存,大部分温热数据或冷数据都可以放在磁盘,从而很好的降低缓存成本。
对前面讲到的这些后端常用的缓存组件,可以参考下表进行选择。
| 缓存组件 |
数据类型 |
访问方式 |
数据容量 (单实例) |
同步 |
内存效率 |
| Memcached |
简单KV |
GET SET DEL等常规接口 |
100G以下 |
Client 多写 |
一般 |
| Redis |
丰富 |
更丰富常规接口、事物更新等 |
30G以下 |
主从复制 |
一般 |
| Pika/ssdb |
较丰富,部分Redis数据结构不支持 |
较丰富 |
数百G以上 |
主从复制 |
一般 |
最后,对于对存储效率、访问性能等有更高要求的业务场景,结合业务特性进行缓存组件的定制化设计与开发,也是一个很好的选择。
总之,缓存组件的选型要考虑数据模型、访问方式、缓存成本甚至开发人员的知识结构,从而进行因地制宜的取舍,不要盲目引入不熟悉、不活跃、不成熟的缓存组件,否则中途频繁调整缓存方案,会给开发进度、运维成本带来较大的挑战。
原文发布时间为:2018-12-03
本文作者: 深入分布式缓存