
未来已至!可穿戴设备将如何改变我们的生活?










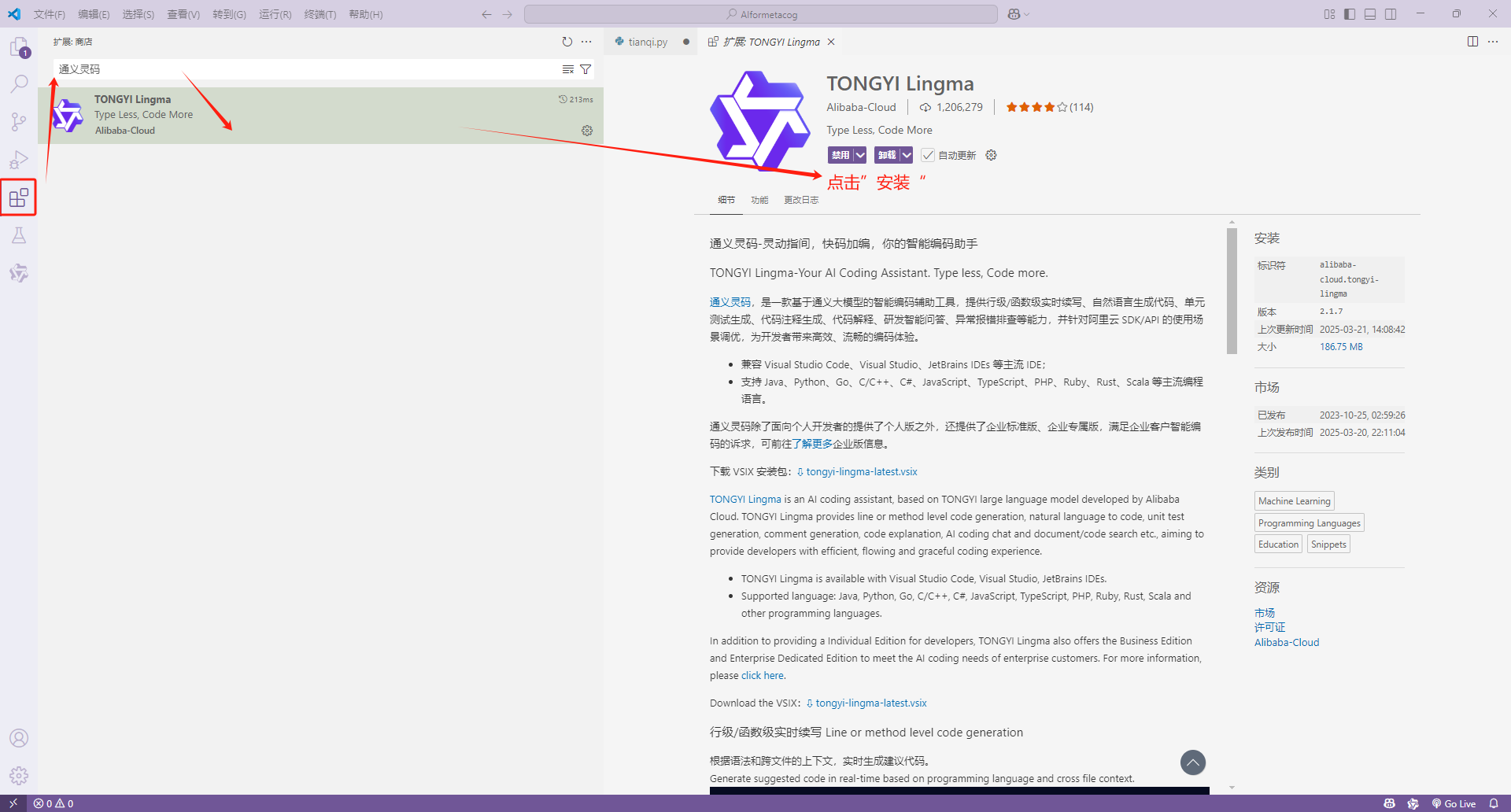




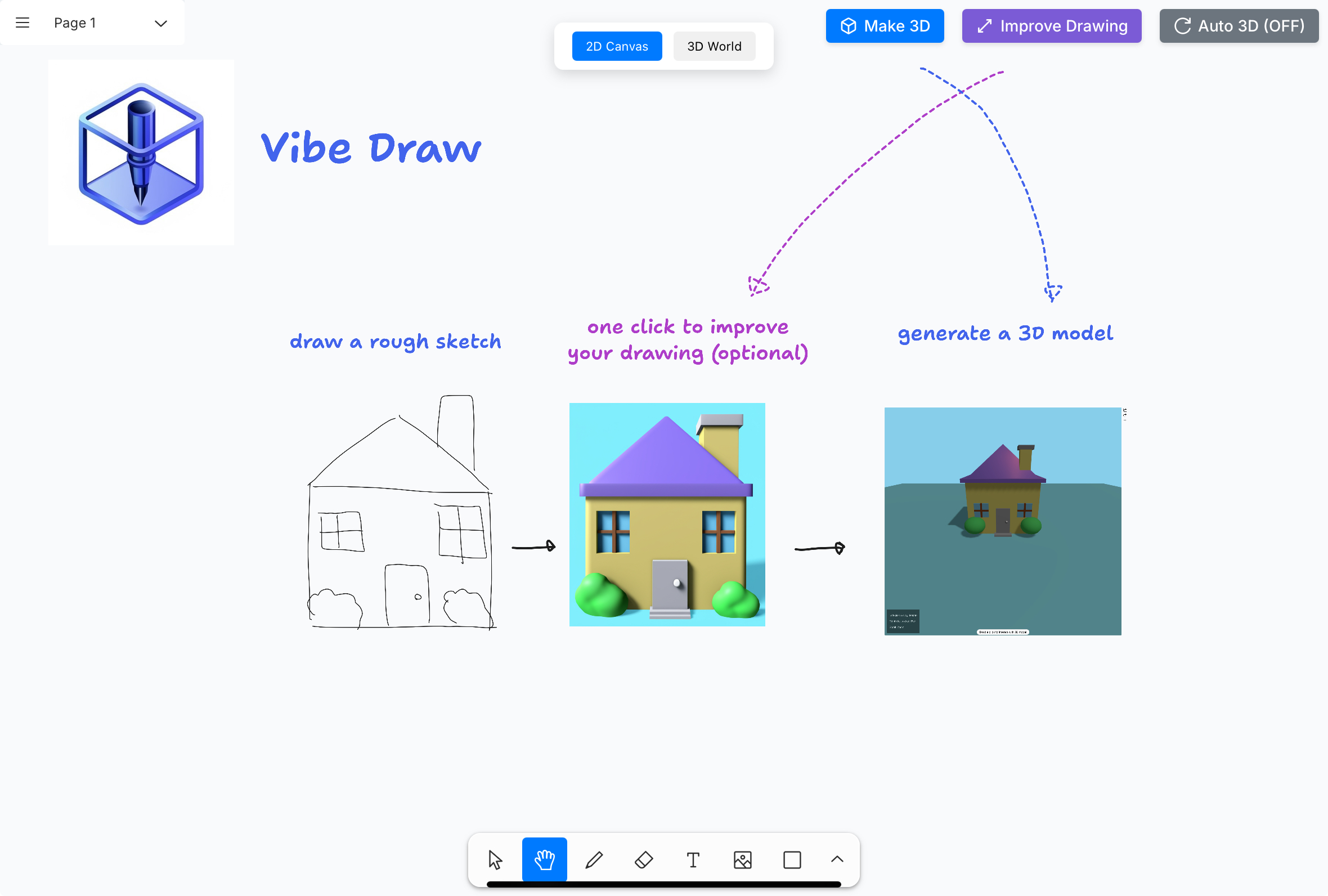

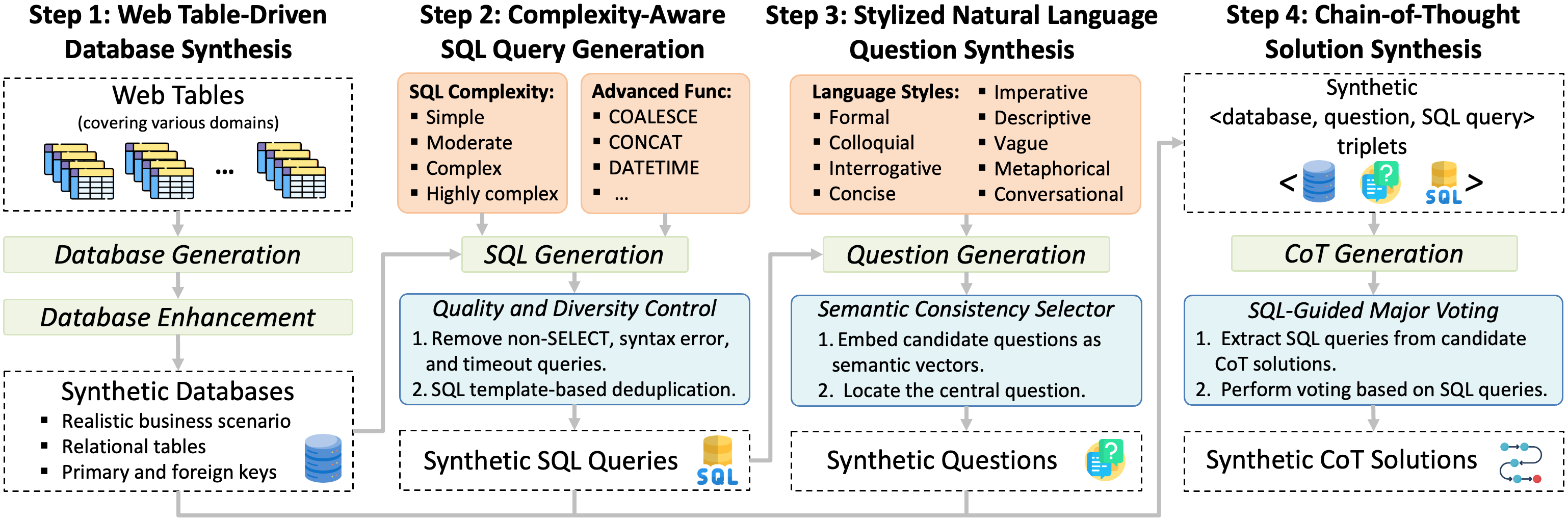



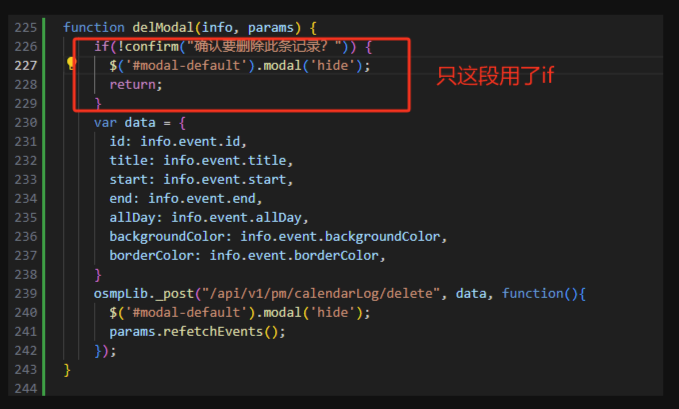
你好,我是AI助理
可以解答问题、推荐解决方案等
