全图化引擎
由来
作为一个草根出生,有着近10年发展的搜索引擎,HA3有着老古董系统都具备的优缺点,功能经典且稳定,系统复杂而难用。在发展的过程中,HA3通过一个个性能和稳定性的成绩在集团内遍地开花,丰富的定制化能力使得能支持不同的业务场景,至今仍有近5年前版本在线上稳定运行。但阿里的业务发展更快,推荐、个性化、机器学习、人工智能等技术的大力发展,常规搜索和推荐业务迎来了新的变革,使用过搜索服务的同学大都听过搜索事业部其他的在线技术组件,如iGraph、RTP、DII等,正是这些新生的系统填补了搜索和推荐其他场景的空白,他们跟HA3一样,有着丰富的索引能力、实时处理能力,并具备高可用和高可运维性,同时自助化服务的能力也有大幅的进步,这些相近的能力底层在过年的两年得到了充分整合,并诞生的名叫
suez框架的东西。suez框架不仅是搜索技术的集大成者,而且以一个通用的抽象方便用户定义自己的服务,因为用户可以直接得到前面提到的各种好处,而在服务本身上也没有什么限制,另外一方面suez和底层一层调度系统hippo/sigma的结合,使得服务一上线就具备极好的failover处理能力和资源丰富的在离线混部环境。例如基于suez构建的BE,仅花了2~3个月就完成了系统从无到有的过程,出道便拥有了搜索沉淀了多年的底层能力,逐渐成为了推荐系统的中流砥柱。
不过基于HA3/BE/RTP/iGraph/DII这些系统开发的用户来说,suez带来的好处可能体感没那么强烈,相反会有很多的困惑。首先各个服务的用途和局限是很难界定的,其次相同的功能在不同的系统实现和使用不一致,再者当同时需要组合各个系统的功能时开发成本很高,而且每个新系统的出现对存量用户来说就意味这迁移成本。倘若继续挖掘,再找几个类似的问题应该不难,那么问题出在哪里呢?而对这些系统的开发人员来说,suez像一个潘多拉魔盒,一打开就一发不可收拾,它把最核心的能力都开放了出来,把最复杂的问题都收敛了进去,让功能开发在不同系统上没有了壁垒,没有什么功能在自己的系统上是不能做的,HA3上可以支持BE的多表查询能力、RTP可以支持QP(DII) Query分析的能力、BE可以支持HA3插件定制的能力...是的,只要开发人员愿意,只要他的客户真心有需求,他一定可以得到他想要的。原来的集团军联合作战部队变成了垂直作战小组,短期内项目可能会收获比较好的支持,但长期的协作关系被破坏了,每个团队核心职责需要重新定位,但谁来规定职责的边界呢?
可以想见,没有人能来定义这个边界,实现客户需求可是天经地义的,而且搜索的代码同享机制在此时成了催化剂,不同系统是能很方便复制其他系统的功能,尽管大家支持的用户是同一拨人,但可能最终的用法会不一样,会出现大量“胶水”代码,而代码的不一致往往会导致参数配置、运维管控接口等不一致,这种不一致会随着系统的累加被不断放大,大到大家会认为他们天生就是不一样的。造轮子的人会被客户的认可一直往前推,而忘记了初心,最终的结局可能是大家一起变得平庸。
天无绝人之路,重回初心的最好的方法就是回归到团队使命:"为客户提供最先进的信息组织和获取技术,帮助客户取得业务上的成功",如何从技术上取得突破,得到那条正确的路?在线系统的架构统一一直以来就是大家的梦想,完成suez框架的那最后一公里,解决好这个问题就可以形成更好的合作网络。于是,全图化引擎诞生了,这里有一个更高大上的名字,AI·OS(Artificial Intelligence Online Serving)。全图化引擎,以搭积木的方式提供服务,通过组合一个个独立的子功能(算子),以标准的方式串联,从而形成满足各式各样需求的在线系统。它没有固定的流程,HA3/RTP/BE变成流程的特例,它是去中心化的,任何符合串联标准的流程和算子都能很方便的插入和对接,它是充分共享的,有复用价值的算子都是透明可见的。在这种松耦合的协作中,开发团队的职责变成了产出高质量的算子和抽象业务特定领域的数据模型,通过和算子仓库中的算子对接,支持复杂的业务需求。
特性
从前面的叙述中,我们不难发现有些术语跟tensorFlow(下面简称tf)很像,其实是因为我们内部深度使用了tf,这对习惯了自研的技术的同学们,在一开始选型的时候大家还是很纠结的。一是算子化的思路本来一直就有,二是对tf在生产环境稳定性存疑,三是常规搜索领域的功能算子偏复杂,不太可能一上来就拆分到很细小的粒度,算子规模不大,对tf框架本身的依赖并不强。不过环境会教大家做人,tf在搜索和推荐领域的成功有目共睹,BE/HA3上的用户都在想办法往这个领域靠,RTP在生产上运用tf支撑了很多业务需求,异构计算对算法同学带来了极大帮助,瑕不掩瑜,最终我们决定使用tf作为单机内部的执行引擎。所以全图化引擎最明显的特性之一即是和tf算子的无缝对接,生来便具备向量计算优化、异构计算支持、异步并行框架、网络灵活可拆分等tf原生功能,极大方便用户定义具有AI属性的服务。
全图化引擎第二个特性是定义了支持在线查询的服务的框架(suez turing framework),对应到前面HA3/BE/RTP的查询部分,至此算是初步完成了suez架构的闭合。有人给框架起了个胆大包天的名字turing,虽然噤若寒蝉的人居多,但这个名字还是在开发同学们间传开了,姑且看做是对前辈的敬意和对自己的鞭策。suez架构简要包括如下图几个部分:
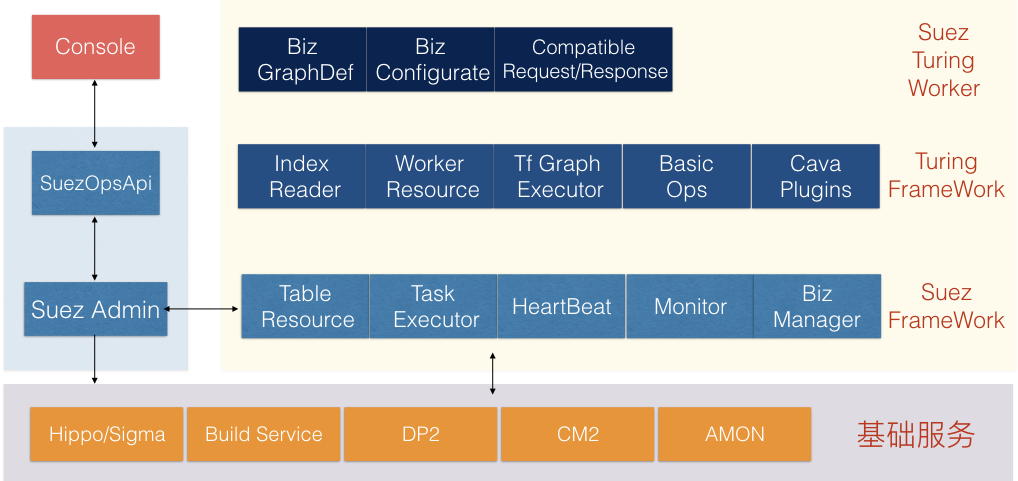
suez turing framework主要逻辑部分组成:
- IndexReader 支持包括倒排表、辅表、子表、KV表、KKV表等丰富的存储引擎。
- WorkerResource 主要是框架对底层suez能力的一些抽象以及对象生命周期的管理,也是不同算子间隐性交互的桥梁。
- Tf Graph Excutor 封装tf执行框架,可以作为tf的预测服务运行;内置图查询框架,支持arpc通信,方便分布式图的构建和访问;提供通用的trace和metric机制,便于算子的调试与监控;支持多biz(多种图实例)机制,一种轻量级的复用方式,方便多租户的方式提供服务。
- Basic Ops 公共算子仓库,HA3/RTP/BE通用算子集中营,是不同业务方相互借力的地方。
- Cava Plugins 提供通用的UDF(User Define Function)能力,并内置一些通用的处理组件,包括score/sort/function等,同时支持jit能力,让用户开发的插件有一个较好的性能起点。
在具体的业务(suez turing worker)层面,如BE/IGRAPH/HA3/RTP等,开发者需要关心的模块和要实现的核心逻辑包括:
- Biz GraphDef 即定义执行的查询的流程图,用户可以构建不同的图支持不一样的业务。
- Biz Configurate 定制服务需要加载的配置、命令行参数、心跳信息、进程可共享的资源等
- Compatible Request/Response 用来兼容老的查询接口或者支持不同的查询接口,将其对接到tf Graph的输入输出。
suez turing framework中有很多HA3/RTP功能的沉淀,主要是为了方便用户编写自己的服务(suez turing worker),而不用花时间在一些基础的功能上,suez turing worker的开发者也可以更多的关注自己的需求,即如何构建查询流程,可以脑补下场景:在草稿纸上画图,开发需要补充的算子或者插件,再用python构造tf图,把图更新后就能验证查询结果了。
全图化引擎的第三个特性是支持在线查询的分布式构建。作为一个在线的服务,必须是要追求高性能的,而在一个查询流程中,不同的算子的开销往往是不一致的,这就要求能站在全流程和整个生命周期的角度来构建这个服务。如淘宝搜索场景,用户的一次搜索请求,会包含用户画像的生成、Query的理解、商品信息的搜索、个性化排序等不同的环节,每个环节对机器的要求和自身的开销都是很不一样的。有的依赖复杂的算法离线训练任务,有的依赖实时更新链路,有的依赖大规模的索引构建,有的需要使用GPU/FPGA,有的需要大内存,有的需要高IOPS等。简单的无状态服务显然不能满足需求,suez平台提供了有状态服务的管理,但不同环节间需要大量的人力协同,而全图化引擎提供了一个更宏观的解决方案,它将服务间的对接变成算子间的协作,而不失全局视角,简言之:以查询的整个链路进行构图,以模块的内聚程度进行图分割,以资源的利用效率进行部署,以通用的算子进行服务串接。在推荐的多个场景,我们将业务调用不同服务并组合的代码下沉到底层算子中,不仅节省了网络中数据多次转发开销,还让后端服务有了在存储上做更细致的优化的可能。
期待
从HA3到AI·OS,大半年的时间,10万行级代码的翻腾,在颠覆自己的同时我们对未来也有了更多期待,相比过去的积累,AI·OS才刚起步,有太多的东西需要去完善,要不怎么迎接下一个五年。从代码的复用到算子的复用,心路历程可谓一言难尽,我们希望这样的成长也能传递给用户,对大部分希望借力AI·OS的同学来说,底层算子本身并不关键,关键的是业务模型的抽象与沉淀,而这种更高层次的复用定才是提升组织的协作效率的关键。在搜索挖坑多年,能深刻理解用户基于底层模块构建服务的痛楚,也深刻感受到能持之以恒做一件事情的幸运,而“既要、也要、还要”的氛围下,如何在满足业务需求的情况下还能造有价值的轮子是个极有挑战的事情,AI OS提供这么一种解法,复用其他团队的轮子时尽可能简单,锻造自身领域的轮子时尽可能彻底,让业务迭代和持续集成聚焦到局部功能而不是整个软件版本。
