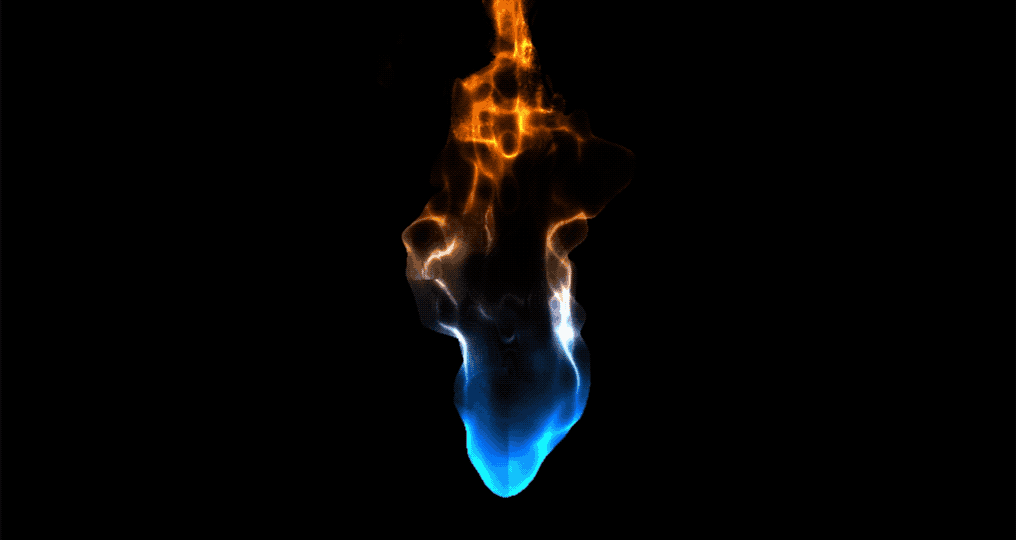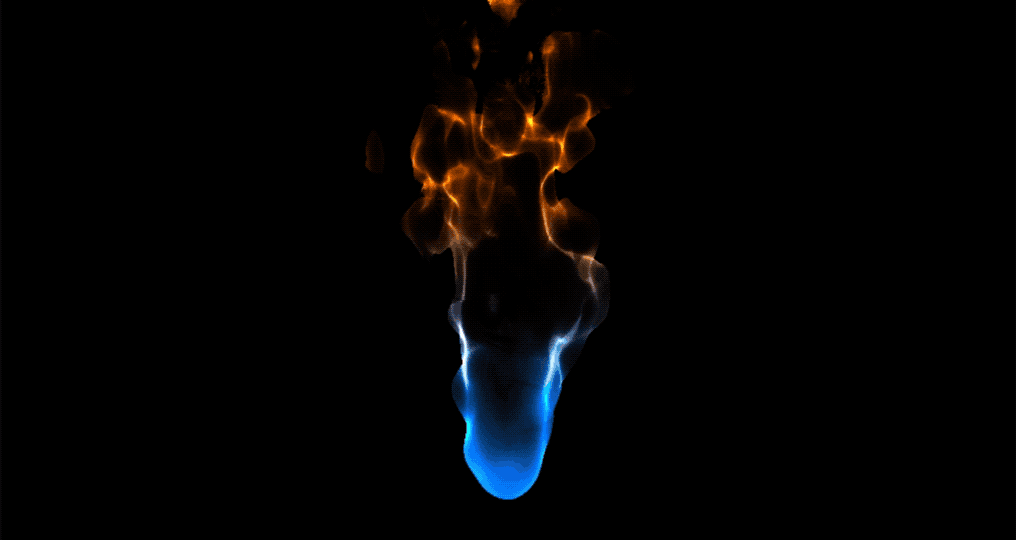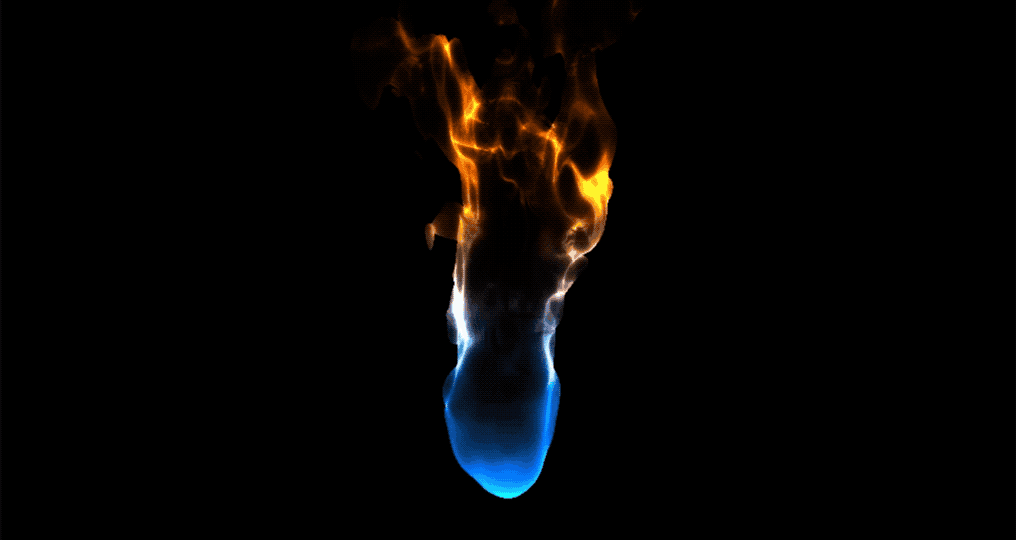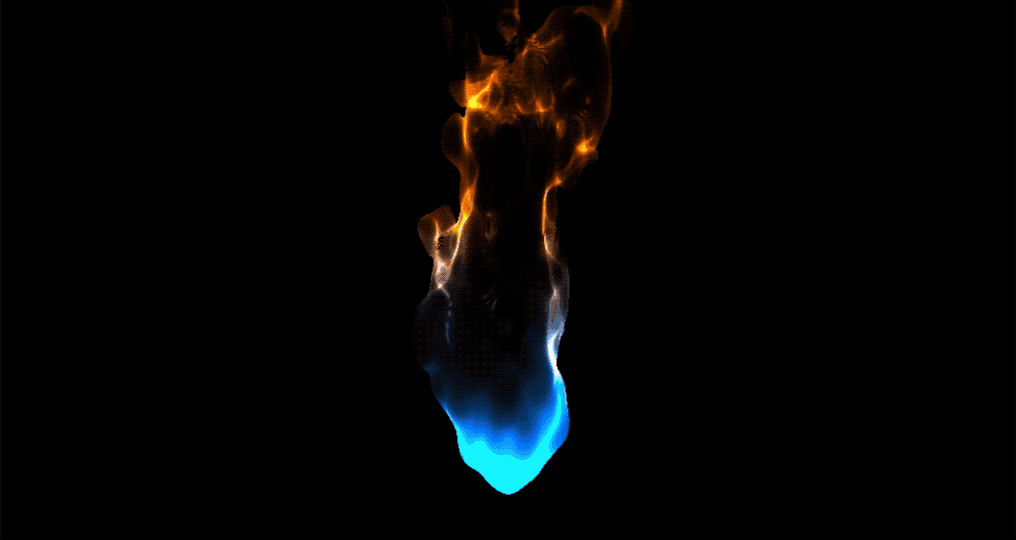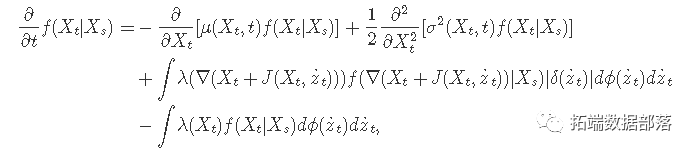热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
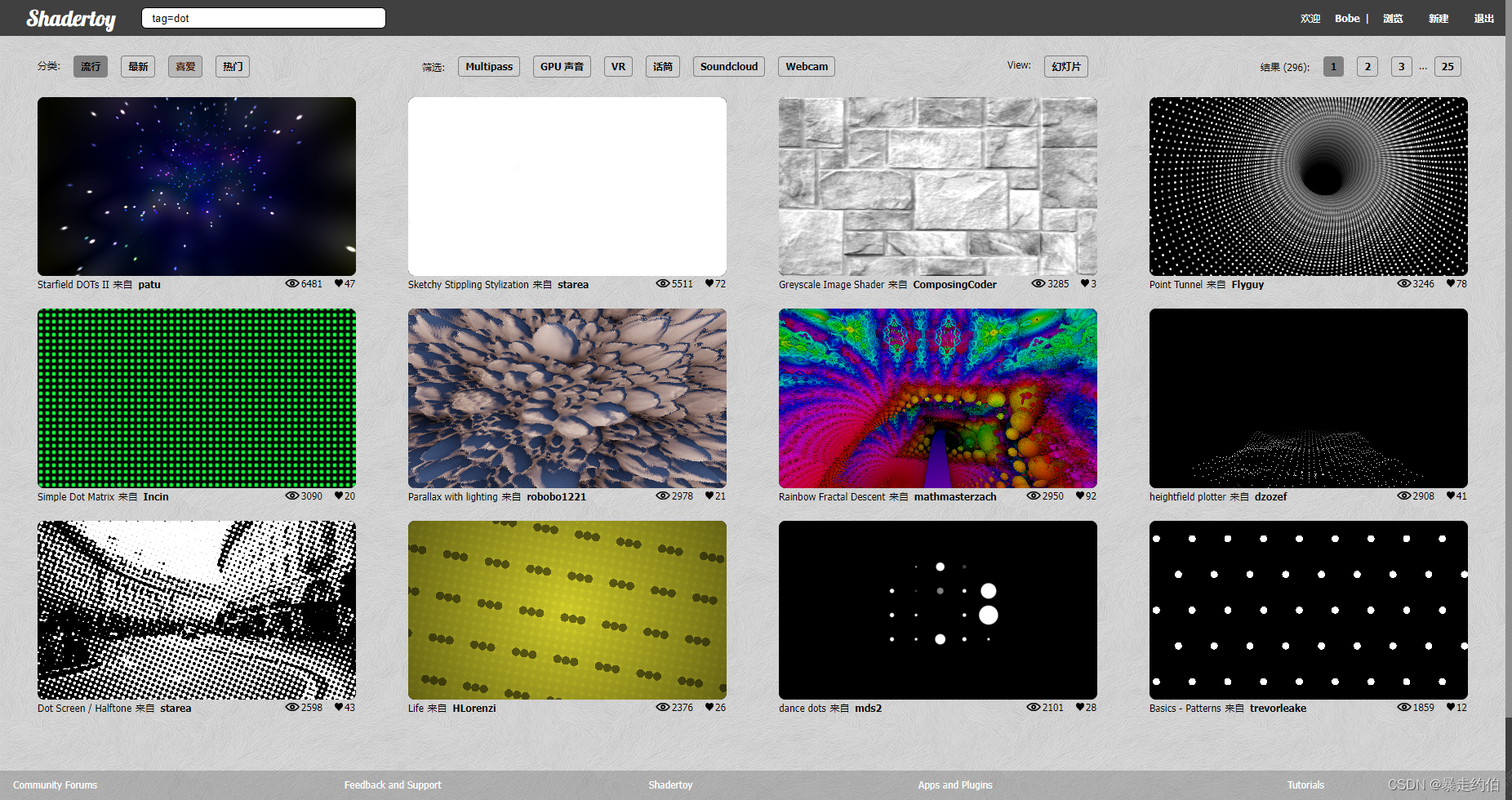
【ShaderToy中图形效果转译到UnityShaderlab案例分享,代码实现渐变火焰扰动_Flame】
【ShaderToy中图形效果转译到UnityShaderlab系列案例分享】
【ShaderToy中图形效果转译到UnityShaderlab案例分享,实现景深透视万花筒_Cave】
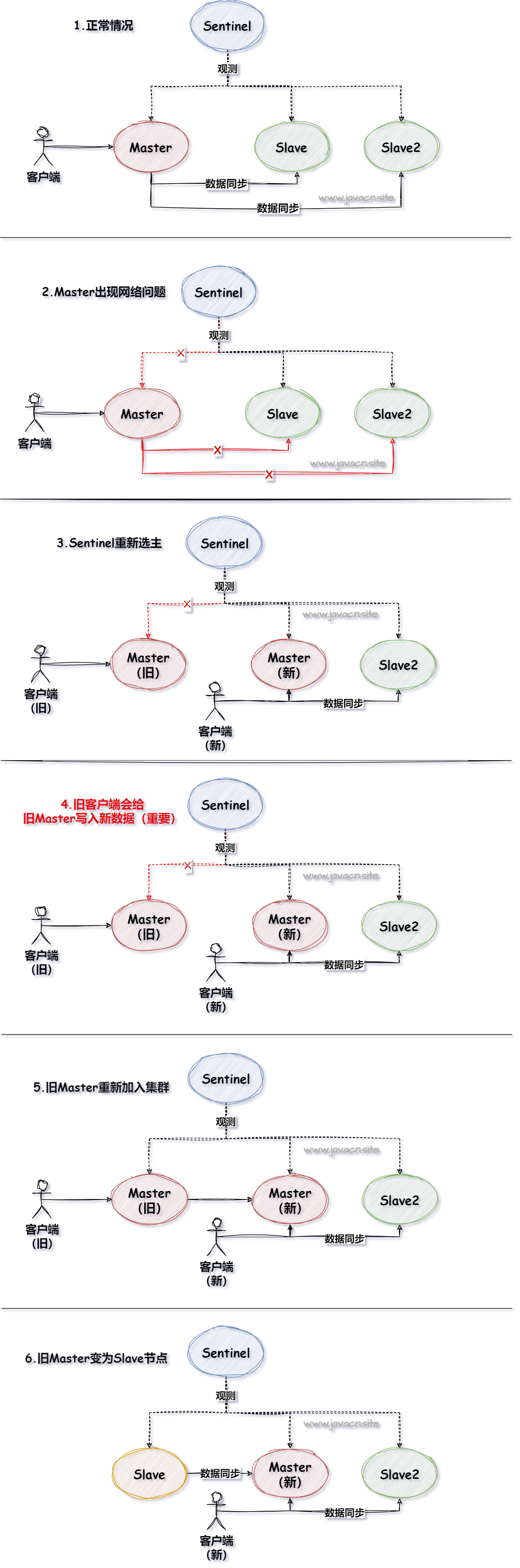
腾讯音乐:说说Redis脑裂问题?
【ShaderToy中图形效果转译到UnityShaderlab案例分享,实现图形太阳_Sun】
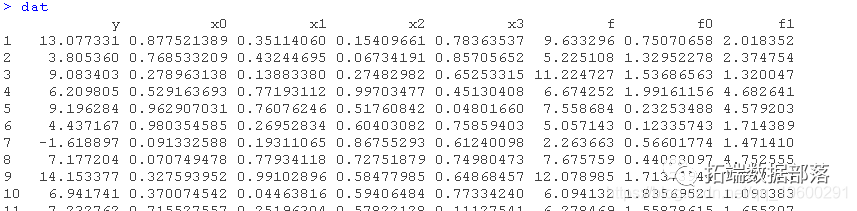
R语言广义二次跳跃、非线性跳跃扩散过程转移函数密度的估计及其应用
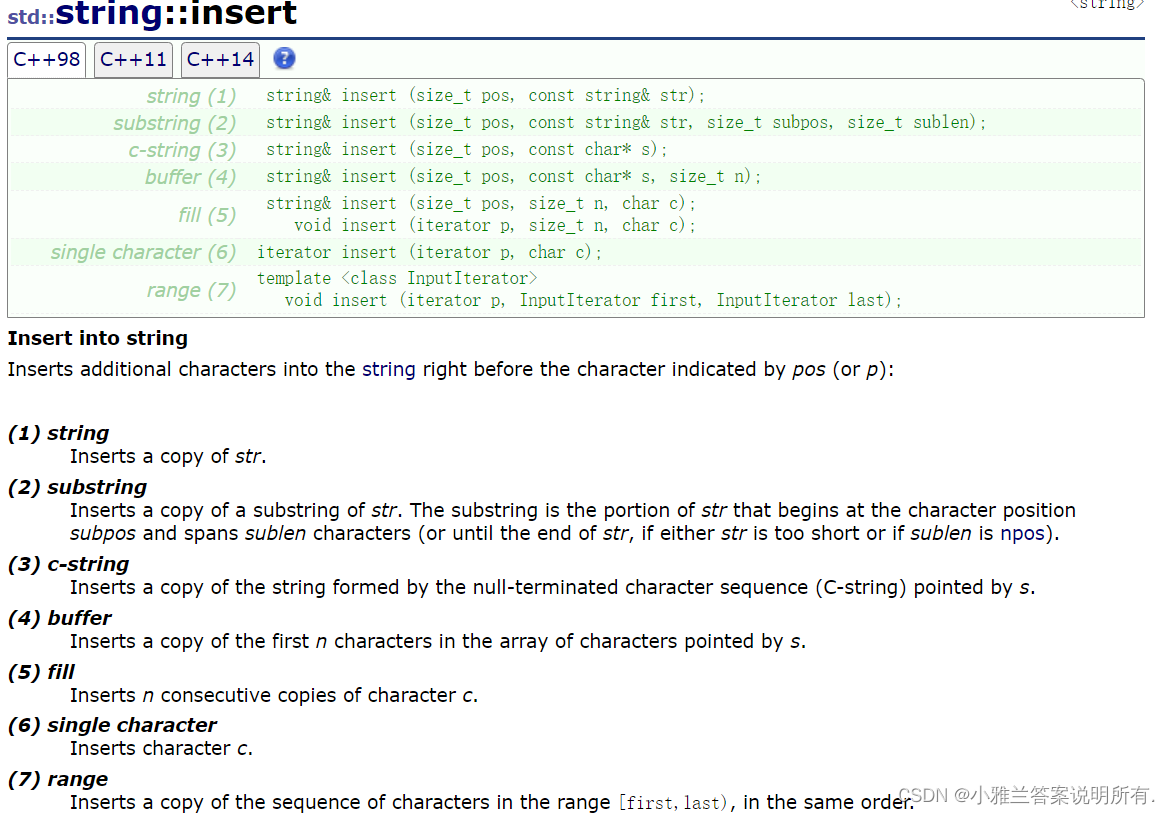
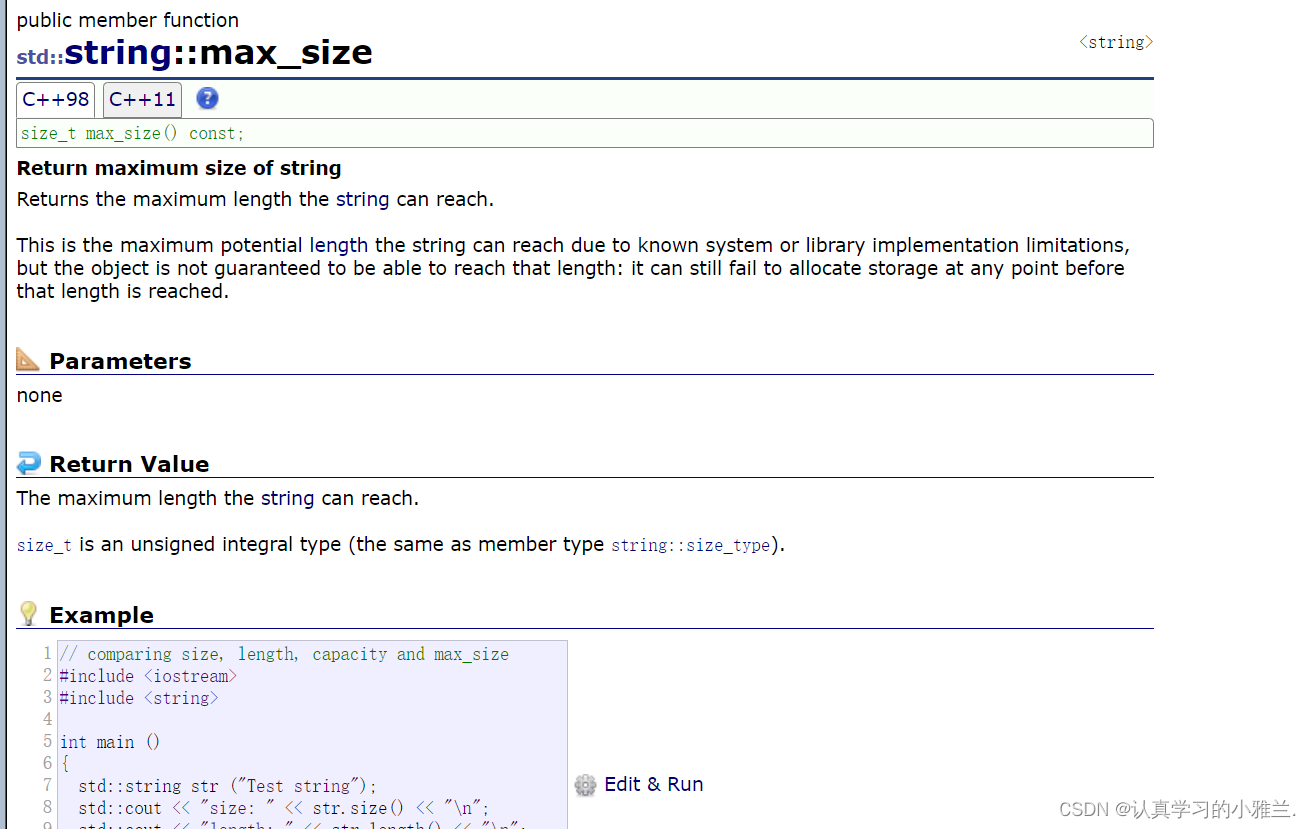
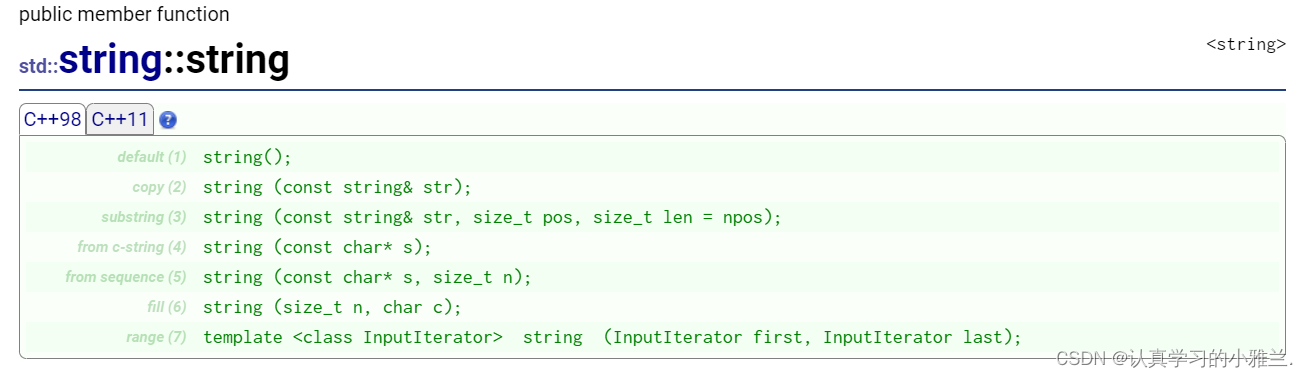
标准库中的string类(下)——“C++”
物理层——“计算机网络”
计算机网络概述(下)——“计算机网络”
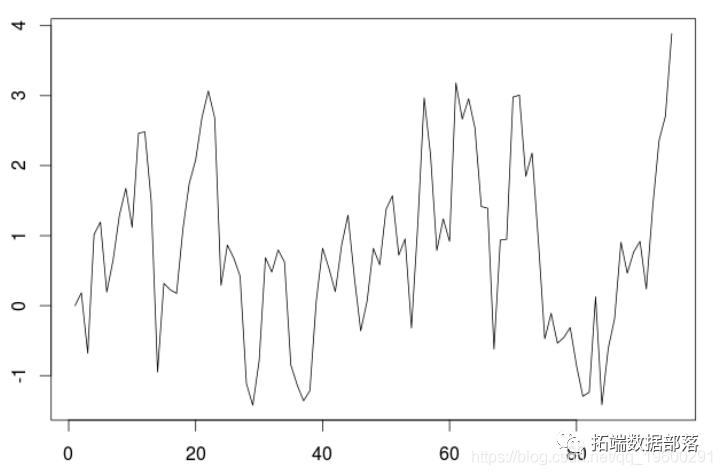
R语言用AR,MA,ARIMA 模型进行时间序列预测
计算机网络概述(上)——“计算机网络”
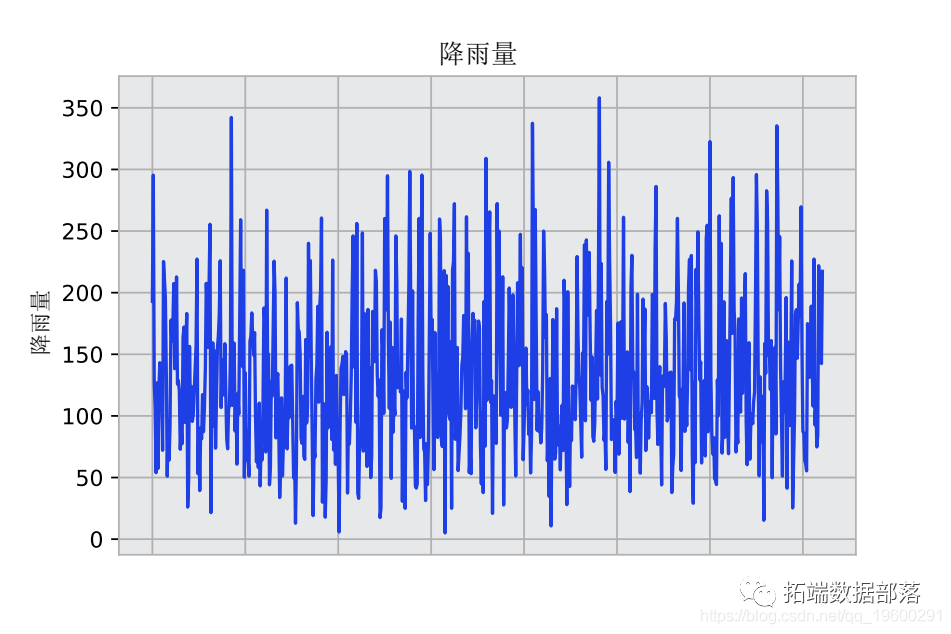
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
标准库中的string类(中)+仅仅反转字母+字符串中的第一个唯一字符+字符串相加——“C++”“Leetcode每日一题”
标准库中的string类(上)——“C++”
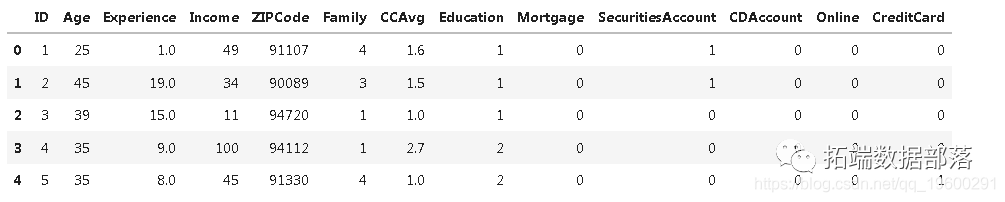
基于机器学习的印度肝脏病诊断分析
开发语言漫谈-kotlin
Python决策树、随机森林、朴素贝叶斯、KNN(K-最近邻居)分类分析银行拉新活动挖掘潜在贷款客户
开发语言漫谈-JavaScript
开发语言漫谈-C#
开发语言漫谈-Java
R语言Metropolis Hastings采样和贝叶斯泊松回归Poisson模型
开发语言漫谈-C++
信号与系统分析导论——“信号与系统”
R语言广义相加(加性)模型(GAMs)与光滑函数可视化
滚雪球学Java(14):快速入门JavaSE-for循环语句,轻松掌握编程技巧
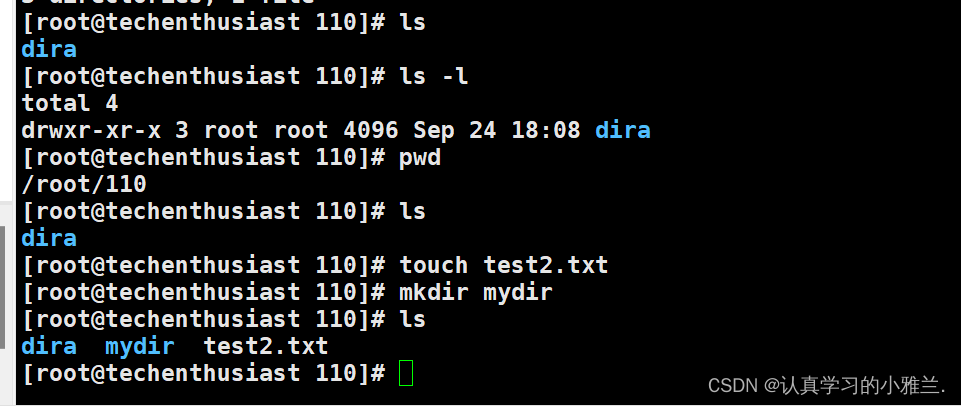
Linux基本指令(下)——“Linux”
亘古难题——前端开发or后端开发
Linux基本指令(中)——“Linux”
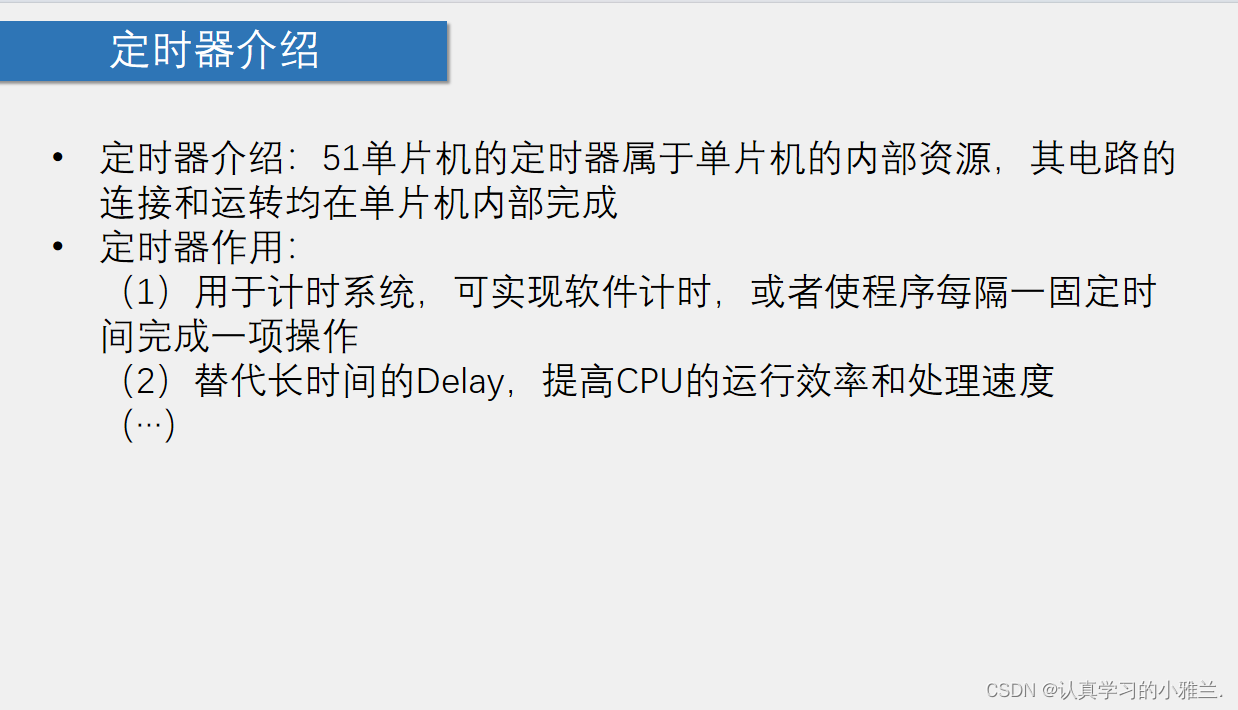
定时器+按键控制LED流水灯模式+定时器时钟——“51单片机”
Linux基本指令(上)——“Linux”
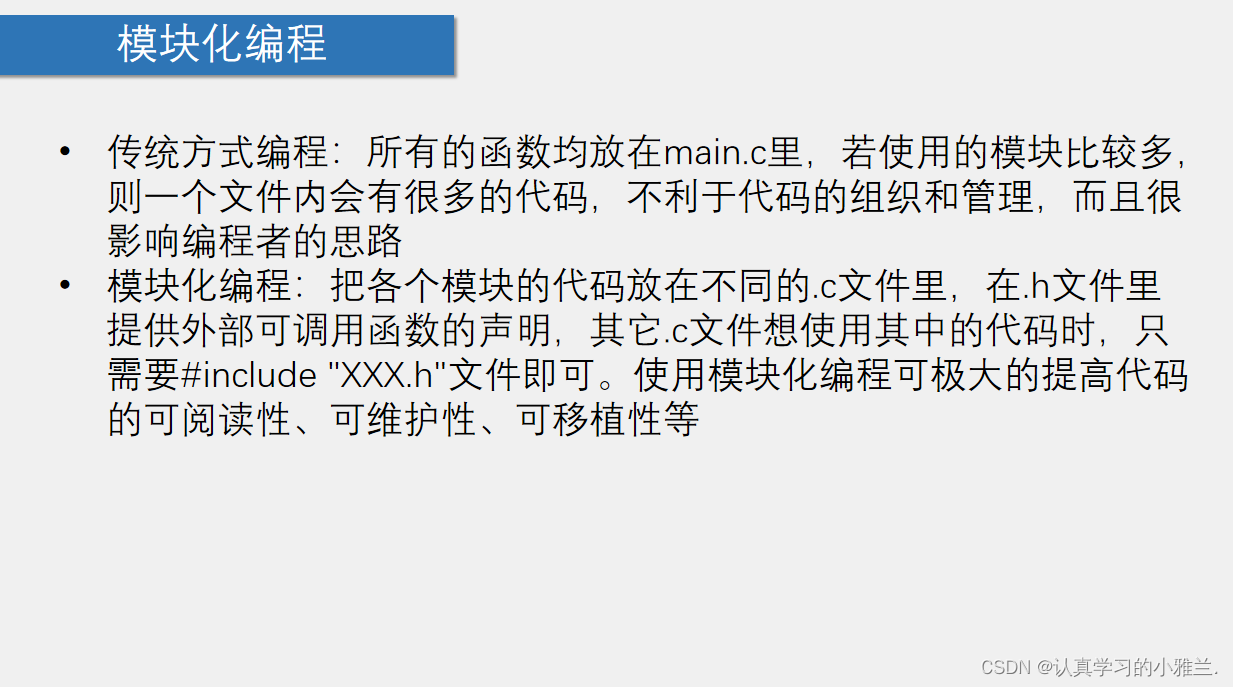
模块化编程+LCD1602调试工具——“51单片机”
静态数码管显示+动态数码管显示——“51单片机”
独立按键控制LED亮灭、独立按键控制LED状态、独立按键控制LED显示二进制、独立按键控制LED移位——“51单片机”
【ShaderToy中图形效果转译到UnityShaderlab案例分享,实现圆形图像变异_Animation】
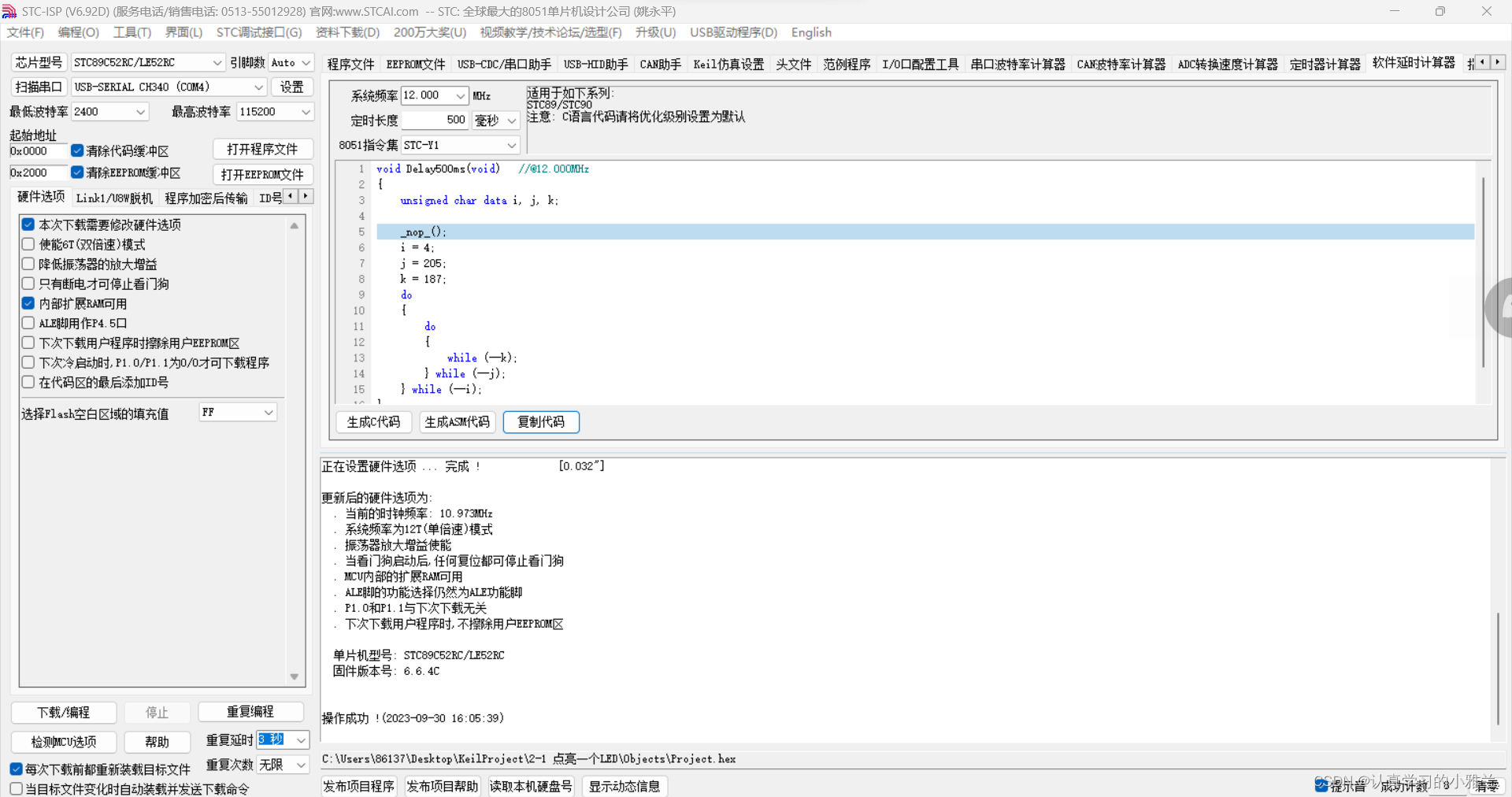
点亮一个LED+LED闪烁+LED流水灯——“51单片机”
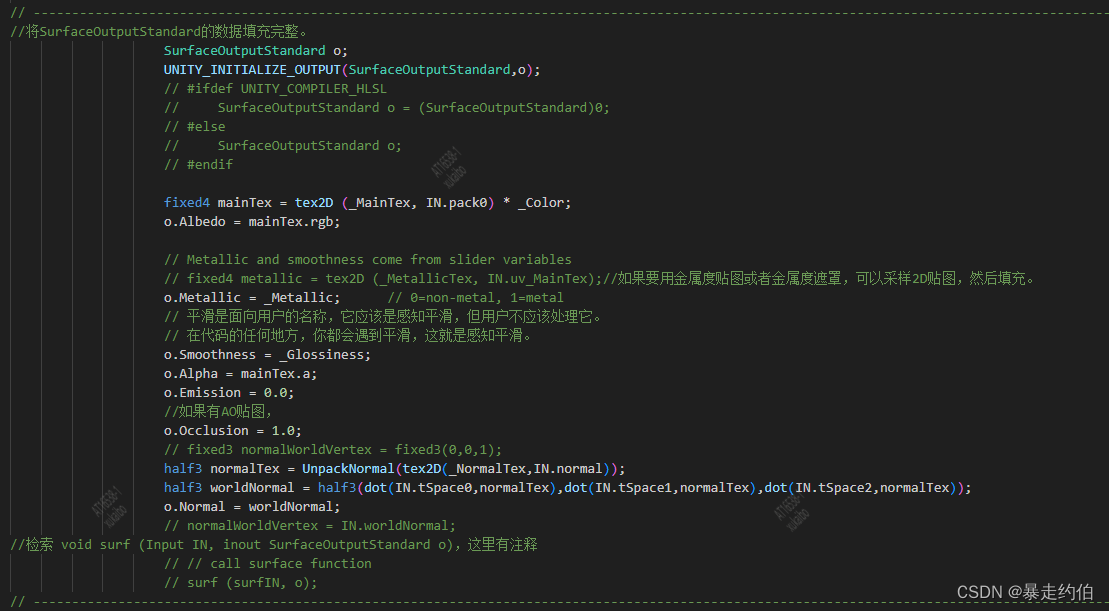
【Unity Build-In管线的SurfaceShader剖析_PBS光照函数】(下)
【Unity Build-In管线的SurfaceShader剖析_PBS光照函数】(上)
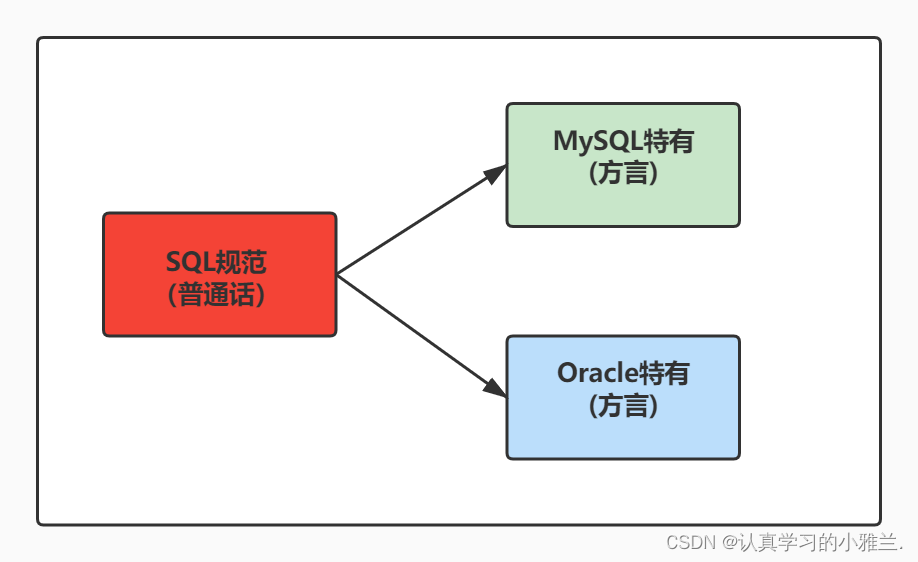
多表查询——“MySQL数据库”
排序与分页——“MySQL数据库”
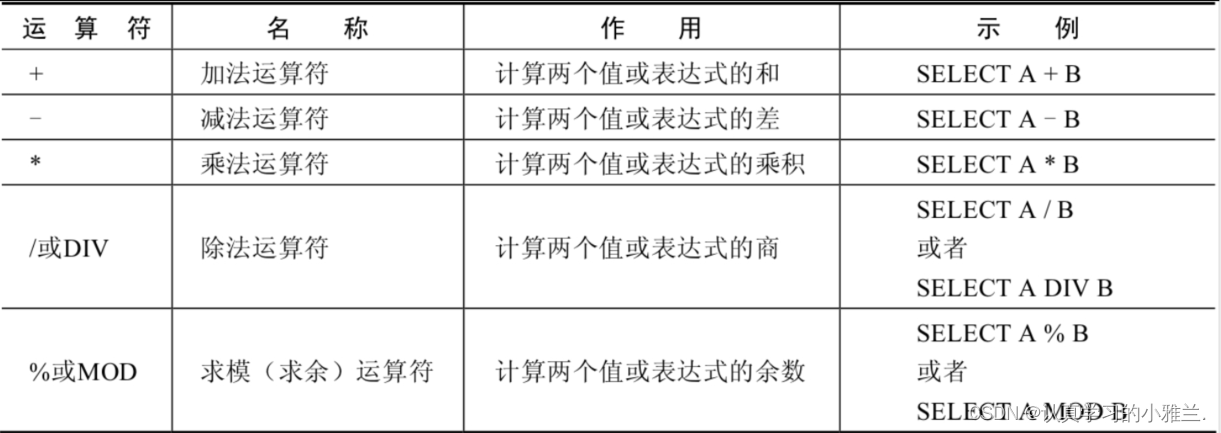
运算符——“MySQL数据库”
基本的SELECT语句——“MySQL数据库”
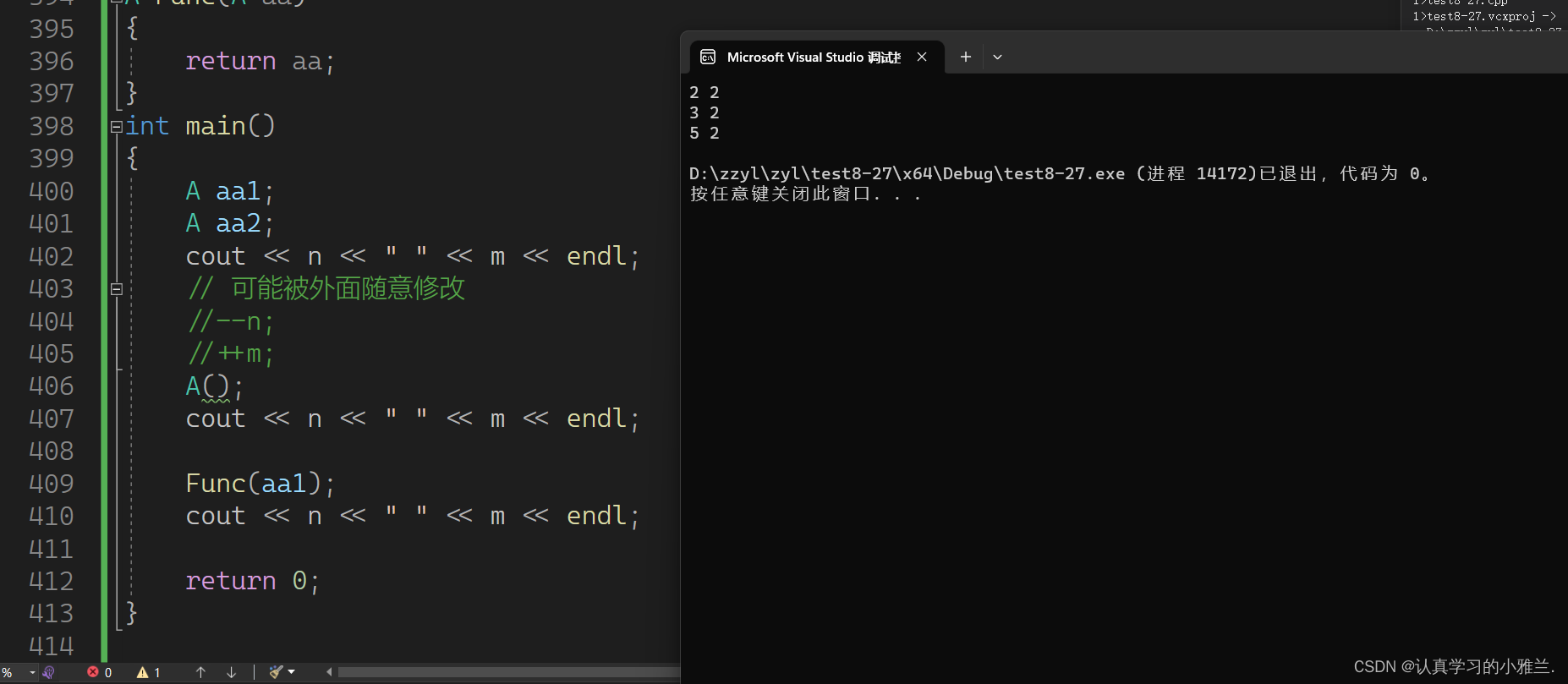
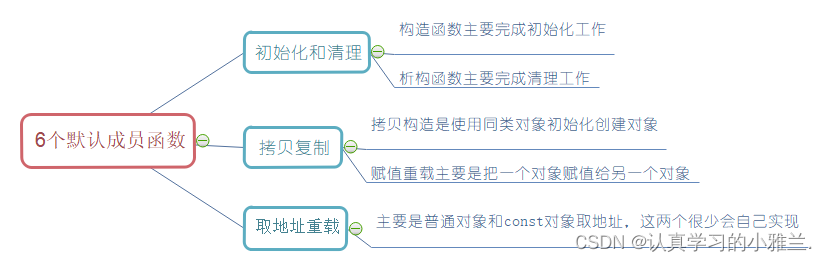
自从学了C++之后,小雅兰就有对象了!!!(类与对象)(下)——“C++”
自从学了C++之后,小雅兰就有对象了!!!(类与对象)(中)——“C++”
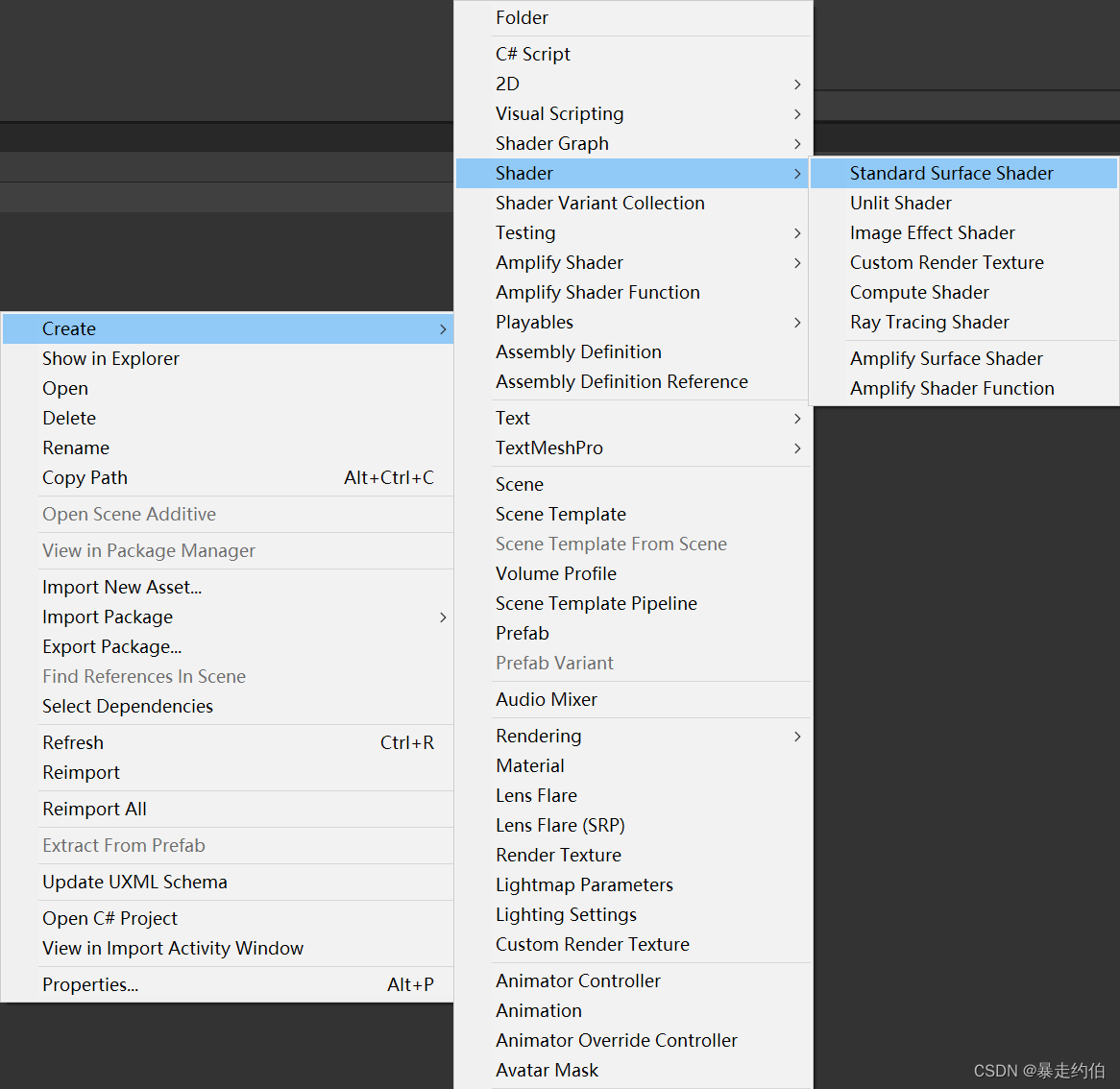
【Shader渲染流水线流程】
【Unity Shader 中Pass相关介绍_第四篇】
自从学了C++之后,小雅兰就有对象了!!!(类与对象)(上)——“C++”
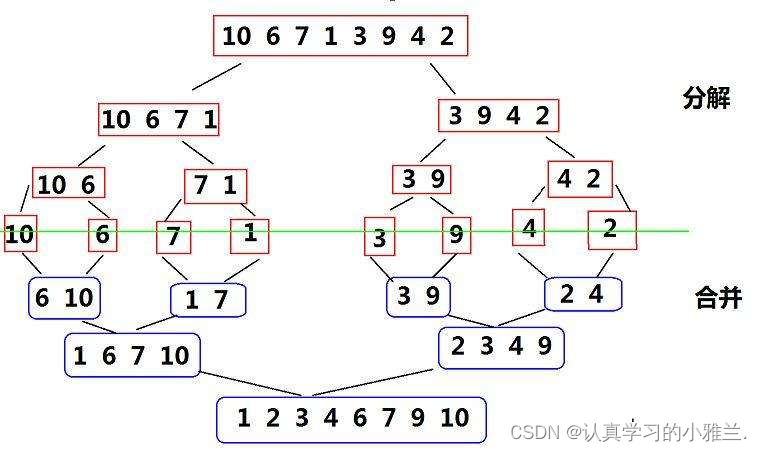
归并排序——“数据结构与算法”
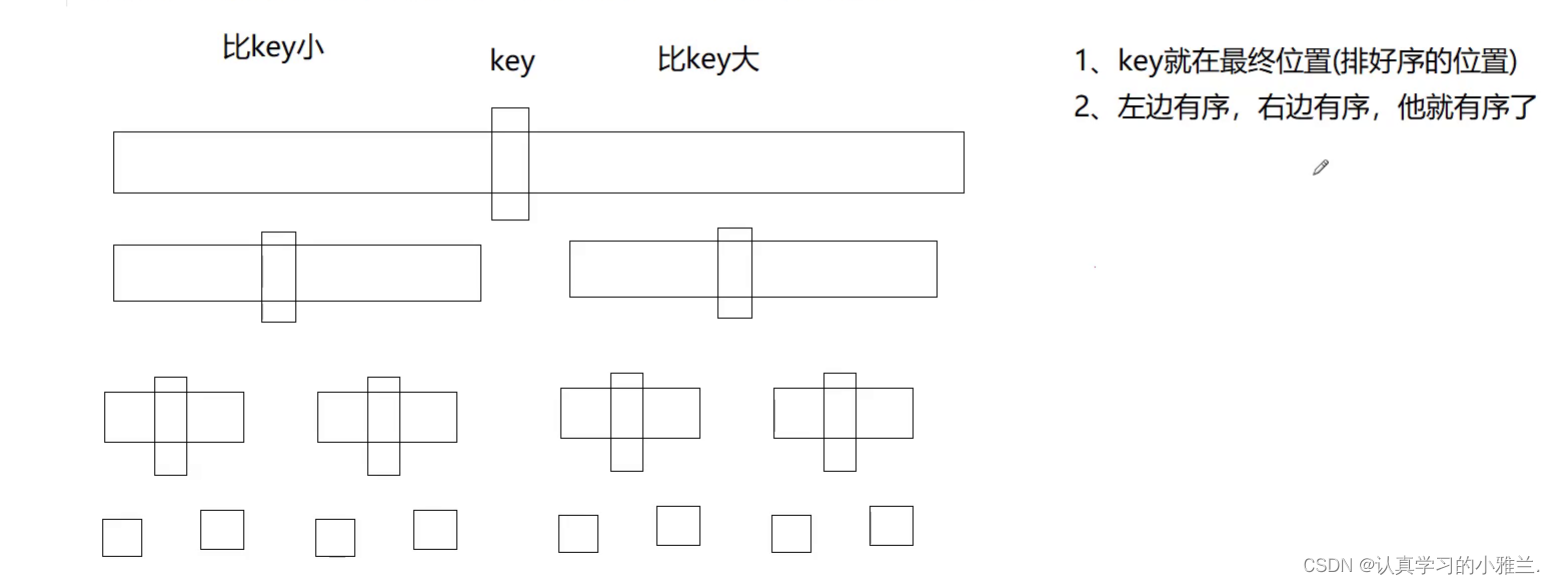
快速排序——“数据结构与算法”