杭州房租:钱塘两岸最高,奥体单间达4830元/月。不少人感叹:躲过了高房价,躲不过高房租,面对房租上涨,感觉身体被掏空。2018年的这个夏天,房租正在成为摧垮年轻人的“第一根稻草”,在杭州打拼的你,所在的城区房租涨了吗?你是否还能潇洒地说出 “买不起房子,就租嘛”?
这是在新浪财经看到的一篇新闻,因为初来杭州,房租涨没涨,我不清楚,但是房租高确确实实是存在的,说多了还是因为穷呐...
接下来就用Python来分析一下杭州的租房情况,看看房租究竟有多高?
数据收集&数据清洗
import re
import time
import requests
from lxml import etree
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
def get_city_areas(url):
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
areas = html.xpath('//ul[@class="new_di_tab sTab"]/a/@title')
areas_links = html.xpath('//ul[@class="new_di_tab sTab"]/a/@href')
for i in range(1, len(areas)):
area = areas[i].replace('杭州', '').replace('租房', '')
area_link = 'https://hz.5i5j.com' + areas_links[i]
try:
get_area_page(area, area_link)
except Exception as e:
continue
def get_area_page(area, link):
key = 1
num = 1
url = link
while key:
time.sleep(2)
response = requests.get(url, headers=headers)
html = response.text
nextpage_link_message = re.findall('<div.*?pageSty.*?href="(.*?)" class=', html, re.S)[0]
if nextpage_link_message:
if nextpage_link_message == 'javascript:void(0);':
key = 0
else:
url = 'https://hz.5i5j.com' + nextpage_link_message.strip("\"")
num += 1
else:
break
pages = num
print(pages)
if pages == 1:
pass
else:
for page in range(1, pages+1):
url = link + 'n' + str(page)
get_house_message(area, url)
def get_house_message(area, url):
print(url)
time.sleep(2)
try:
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
item = len(html.xpath("//h3[@class='listTit']/a/text()"))
for i in range(item):
title = html.xpath("//h3[@class='listTit']/a/text()")[i].replace(',', ',')
rooms_message = html.xpath("//div[@class='listX']/p[1]/text()")[i]
room_type = rooms_message[:10]
square = re.findall(r"\d+\.?\d*", rooms_message[15:25])[0]
position = html.xpath("//div[@class='listX']/p[2]/a/text()")[i]
price = html.xpath("//div[@class='jia']/p[1]/strong/text()")[i]
if room_type[0:1] != '多':
one_room_price = str(float(price) / float(room_type[0:1]))
with open('我爱我家杭州租房.txt', 'a', encoding='utf-8') as f:
f.write(area + ',' + title + ',' + room_type + ',' + room_type[0:1] + ',' + square + ',' + position.split(' ', 1)[0] + ',' + position.split(' ', 1)[1] + ',' + price + ',' + one_room_price + '\n')
except Exception as e:
print("have a problem")
time.sleep(20)
return get_house_message(area, url)
def main():
print("start the work")
url = 'https://hz.5i5j.com/zufang/'
get_city_areas(url)
if __name__ == '__main__':
time.sleep(2)
main()
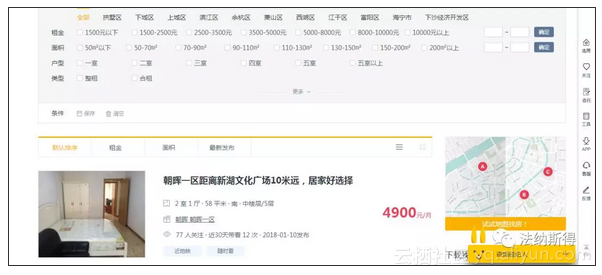
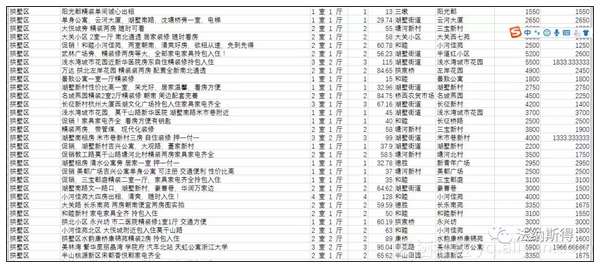
本次主要是对我爱我家租房网站进行信息爬取,为什么要爬取我爱我家呢,也主要是下班回去的路上能看见两家我爱我家的店面,所以感觉信息应该较为可靠,便对网站下手啦,爬取手段挺简单的, 出现的问题主要有以下几点:
①富阳区、海宁市没有房源信息,为空白无信息一页,直接跳过
②各个区域的租房信息总页数为 "..." ,所以无法直接获取,便通过下一页的链接,不断的判断,最后获取总页数
③正常来说一页网页里是有30个房源的,但是最后一页一般是没到30个房源,所以需要判断最后一页有多少房源
④租房信息的标题会有英文符的逗号,会导致后期txt文件转存为csv文件,出现错误,于是直接在信息获取的时候直接替换
⑤对房间类型(几室几厅)的获取,本来以为里面都是数字,但是出现了 "多室多厅" 这种的,所以也予以判断删除,因为后面需要对单间价格进行计算,会出现错误
最后成功获取信息。
数据可视化
import pandas as pd
from pyecharts import Bar, Line, Overlap
f = open(r'C:\Users\Administrator\Desktop\xuexi\我爱我家杭州租房.xlsx', 'rb')
df = pd.read_excel(f, sep=',', header=None, encoding='utf-8', names=['area', 'title', 'room_type', 'room_quantity', 'square', 'xiaoqu', 'loupan', 'price', 'one_room_price'])
area_message = df.groupby(['area'])
area_com = area_message['one_room_price'].agg(['mean', 'count'])
area_com.reset_index(inplace=True)
area_message_last = area_com.sort_values('count', ascending=False)
attr = area_message_last['area']
v1 = area_message_last['count']
v2 = area_message_last['mean']
line = Line("杭州主城区单间均价")
line.add("主城区", attr, v2, is_stack=True,xaxis_rotate=30, yaxis_min=0, mark_point=["max", "min"], xaxis_interval=0, line_color='lightblue', line_width=4, mark_point_textcolor='black', mark_point_color='lightblue', is_splitline_show=False)
bar = Bar("杭州主城区出租房数量&单间均价")
bar.add("主城区", attr, v1, is_stack=True, xaxis_rotate=30, yaxis_min=0, xaxis_interval=0, is_splitline_show=False)
overlap = Overlap()
overlap.add(bar)
overlap.add(line, yaxis_index=1, is_add_yaxis=True)
overlap.render('杭州主城区出租房数量&单间均价.html')
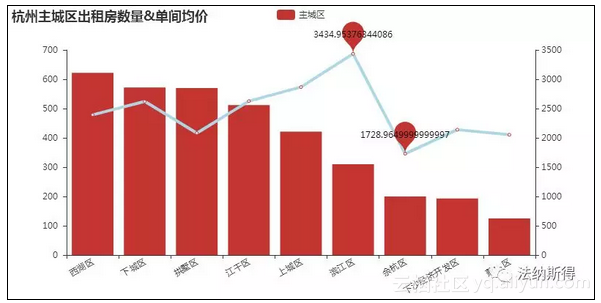
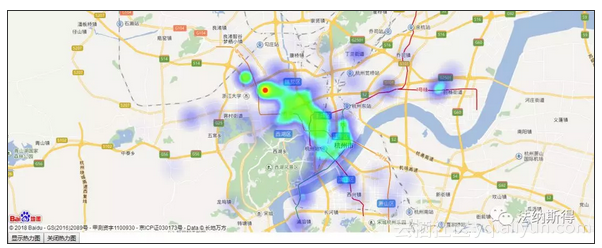
分析了我爱我家的3000多套出租房信息,可以看出房源主要集中在西湖区、下城区、拱墅区、江干区、上城区。这里的房租我把它特意计算为单间价格,其中滨江区房租最高,这估计也是滨江作为高新区,阿里网易华为吉利海康威视等诸多上市公司云集的结果,毕竟大厂的员工薪水摆在那里,自然而然也就抬高了滨江的房租。针对房源的小区分布,我基于百度地图的API制作了一份房源分布热力图,也能更直观的看出来分布情况。
xiaoqu_message = df.groupby(['xiaoqu'])
xiaoqu_com = xiaoqu_message['one_room_price'].agg(['mean', 'count'])
xiaoqu_com.reset_index(inplace=True)
xiaoqu_message_last = xiaoqu_com.sort_values('count', ascending=False)[0:20]
attr = xiaoqu_message_last['xiaoqu']
v1 = xiaoqu_message_last['count']
v2 = xiaoqu_message_last['mean']
line = Line("杭州小区单间均价")
line.add("小区", attr, v2, is_stack=True, xaxis_rotate=30, yaxis_min=0, mark_point=["max", "min"], xaxis_interval=0, line_color='lightblue', line_width=4, mark_point_textcolor='black', mark_point_color='lightblue', is_splitline_show=False)
bar = Bar("杭州小区出租房数量&单间均价")
bar.add("小区", attr, v1, is_stack=True, xaxis_rotate=30, yaxis_min=0, xaxis_interval=0, is_splitline_show=False)
overlap = Overlap()
overlap.add(bar)
overlap.add(line, yaxis_index=1, is_add_yaxis=True)
overlap.render('杭州小区出租房数量&单间均价.html')
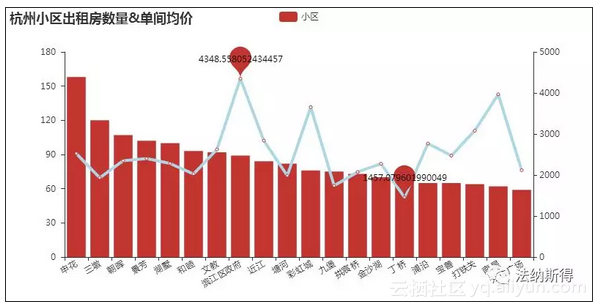
其中申花和三墩都是属于西湖区,这也与上面的西湖区的房源数量最多有了对应,滨江区政府的价格还是最高,对于滨江区政府的印象就是靠近吉利汽车,海康威视,还有就是距离钱塘江岸边很近,滨江区的图书馆也在那里,借书可以支付宝免押金,这点果断好评。
loupan_message = df.groupby(['loupan'])
loupan_com = loupan_message['one_room_price'].agg(['mean', 'count'])
loupan_com.reset_index(inplace=True)
loupan_message_last = loupan_com.sort_values('count', ascending=False)[0:20]
attr = loupan_message_last['loupan']
v1 = loupan_message_last['count']
v2 = loupan_message_last['mean']
line = Line("杭州楼盘单间均价")
line.add("楼盘", attr, v2, is_stack=True, xaxis_rotate=30, yaxis_min=0, mark_point=["max", "min"], xaxis_interval=0, line_color='lightblue', line_width=4, mark_point_textcolor='black', mark_point_color='lightblue', is_splitline_show=False)
bar = Bar("杭州楼盘出租房数量&单间均价")
bar.add("楼盘", attr, v1, is_stack=True, xaxis_rotate=30, yaxis_min=0, xaxis_interval=0, is_splitline_show=False)
overlap = Overlap()
overlap.add(bar)
overlap.add(line, yaxis_index=1, is_add_yaxis=True)
overlap.render('杭州楼盘出租房数量&单间均价.html')
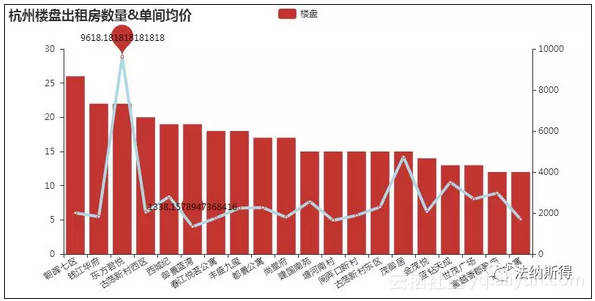
这里东方君悦的房租及其的高,因为初来杭州对这些地产也不了解,特意百度了一下,原来是在钱塘江边,靠近市民中心,江景房、管家式服务、高端酒店式公寓,简直租房界的贵族...
price_info = df['one_room_price']
bins = [0, 1000, 1500, 2000, 2500, 3000, 3500, 4000, 5000, 6000, 7000, 8000, 9000, 10000]
level = ['0-1000', '1000-1500', '1500-2000', '2000-2500', '2500-3000', '3000-3500', '3500-4000', '4000-5000', '5000-6000', '6000-7000', '7000-8000', '8000-9000', '10000以上']
price_stage = pd.cut(price_info, bins=bins, labels=level).value_counts().sort_index()
attr = price_stage.index
v1 = price_stage.values
bar = Bar("杭州出租房单间价格区间及数量")
bar.add("",attr,v1,is_stack=True, xaxis_rotate=30, yaxis_min=0, xaxis_interval=0, is_splitline_show=False)
bar.render("杭州出租房单间价格区间及数量.html")
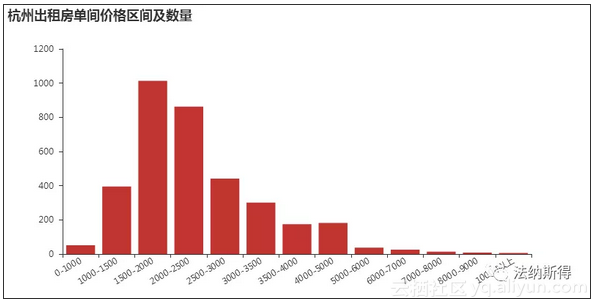
单间价格主要集中在1000-3000,这点我是深有体会的,毕竟上个月刚在杭州找的房子,本来自己的预算是1000-2000,网上一了解,好点的房子都是需要2000+,便找了个老小区入住,不得不向金钱大佬屈服,最后房租在2000以下,离公司挺近的,交通也算便利。
square_info = df['square']
bins = [0, 30, 60, 90, 120, 150, 200, 300]
level = ['0-30', '30-60', '60-90', '90-120', '120-150', '150-200', '200+']
square_stage = pd.cut(square_info, bins=bins, labels=level).value_counts().sort_index()
attr = square_stage.index
v1 = square_stage.values
pie = Pie("杭州出租房房屋面积分布", title_pos='center')
pie.add("", attr, v1, radius=[40, 75], label_text_color=None, is_label_show=True, legend_orient="vertical", legend_pos="left",)
pie.render('杭州出租房房屋面积分布.html')
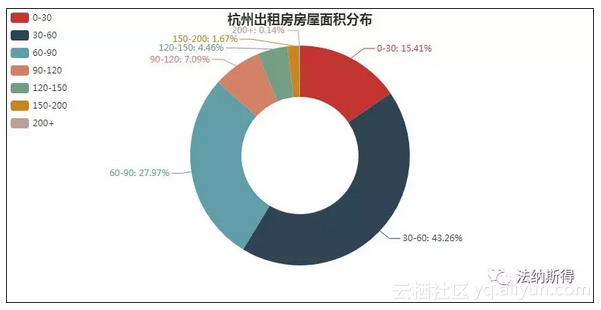
可以看出杭州的出租房大多是分布在30到90平米之间,这也符合常态,毕竟面积过大,租不起,面积过小,住的不舒坦。
square_info = df['square']
bins = [0, 30, 60, 90, 120, 150, 200, 300]
level = ['0-30', '30-60', '60-90', '90-120', '120-150', '150-200', '200+']
df['square_level'] = pd.cut(square_info, bins=bins, labels=level)
df_message = df[['area', 'title', 'room_type', 'room_quantity', 'square', 'xiaoqu', 'loupan', 'price', 'one_room_price', 'square_level']]
prices_message = df_message.groupby(['square_level'])
prices_com = prices_message['price'].agg(['mean', 'count'])
prices_com.reset_index(inplace=True)
attr = prices_com['square_level']
v1 = prices_com['mean']
bar = Bar("杭州出租房房屋面积&价位分布")
bar.add("房租", attr, v1, is_stack=True, xaxis_rotate=30, yaxis_min=0, xaxis_interval=0, is_splitline_show=False)
bar.render("杭州出租房房屋面积&价位分布.html")
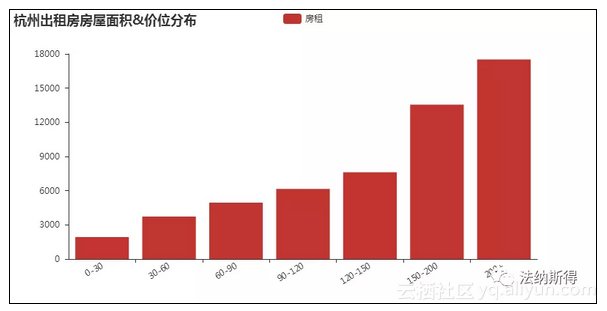
这里不是采用的单间价格,而是房间的总价,可以看出随着房屋面积的增加,租金便也随其增加,符合常态。
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
import pandas as pd
import jieba
f = open(r'C:\Users\Administrator\Desktop\xuexi\我爱我家杭州租房.xlsx', 'rb')
df = pd.read_excel(f, sep=',', header=None, encoding='utf-8', names=['area', 'title', 'room_type', 'room_quantity', 'square', 'xiaoqu', 'loupan', 'price', 'one_room_price'])
text = ''
for line in df['title']:
text += ' '.join(jieba.cut(line, cut_all=False))
backgroud_Image = plt.imread('room.jpg')
wc = WordCloud(
background_color='white',
mask=backgroud_Image,
font_path='C:\Windows\Fonts\STZHONGS.TTF',
max_words=2000,
max_font_size=150,
random_state=30
)
wc.generate_from_text(text)
img_colors = ImageColorGenerator(backgroud_Image)
wc.recolor(color_func=img_colors)
plt.imshow(wc)
plt.axis('off')
wc.to_file("房子.jpg")
print('生成词云成功!')

针对租房信息的标题制作词云,可以看出拎包入住是出现最多的,这也与我爱我家的主打广告相契合,毕竟天天路过,想不知道都难,精装、合租、家电齐全、交通便利、随时看房,这些也是一般租房者所关心的,当然价格也是不容忽视的。
import json
import requests
import pandas as pd
def get_lnglat(address):
url = 'http://api.map.baidu.com/geocoder/v2/'
output = 'json'
ak = '你的密匙'
city = '杭州市'
uri = url + '?' + 'address=' + '杭州' + address + '&city=' + city + '&output=' + output + '&ak=' + ak
response = requests.get(uri)
message = json.loads(response.text)
return message
f = open(r'C:\Users\Administrator\Desktop\xuexi\我爱我家杭州租房.xlsx', 'rb')
df = pd.read_excel(f, sep=',', header=None, encoding='utf-8', names=['area', 'title', 'room_type', 'room_quantity', 'square', 'xiaoqu', 'loupan', 'price', 'one_room_price'])
xiaoqu_message = df.groupby(['xiaoqu'])
xiaoqu_com = xiaoqu_message['xiaoqu'].agg(['count'])
xiaoqu_com.reset_index(inplace=True)
file = open(r'C:\Users\Administrator\Desktop\cuiqingcai\point.json', 'w')
for i in range(len(xiaoqu_com['xiaoqu'])):
b = xiaoqu_com['xiaoqu'][i]
c = xiaoqu_com['count'][i]
lng = get_lnglat(b)['result']['location']['lng']
lat = get_lnglat(b)['result']['location']['lat']
lng_lat_count = '{"lat":' + str(lat) + ',"lng":' + str(lng) + ',"count":' + str(c) + '},'
file.write(lng_lat_count)
file.close()
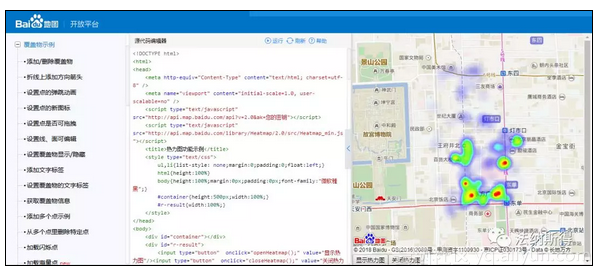
这个是经纬度获取的代码,通过调用百度地图的API,实现对地点的经纬度获取,然后在
http://lbsyun.baidu.com/jsdemo.htm#c1_15
里添加你的密匙及获取的经纬度,然后调整地图中心点经纬度(30.28,120.16)、地图层级(12)、半径大小(35)、最大数量(160),便可得到热力图,这里面需要注意的就是信息完善,因为地点信息不完整,会导致经纬度查询错误,返回错误的经纬度,所以针对返回错误经纬度的地点,进行手动查询地点信息,最后获取相对完整的地点信息,然后再在表格中手动修改(自己大概有个十几个)。
原文发布时间为: 2018-11-30
本文作者:法纳斯特
本文来自云栖社区合作伙伴“程序员共成长”,了解相关信息可以关注“程序员共成长”。