新增原理
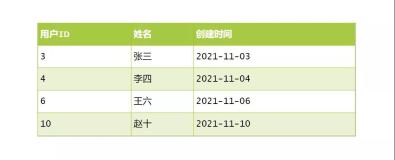
调用 put() 方法新增 key-value, 实际是调用 putVal() 方法完成. key 为空索引位置是 0, 索引位置相同则通过链表方式保存, 当链表长度超过 8 后转成红黑树保存; 当 key-value 数量超过阈值, 就要将数组 resize.
newNode()
key-value 实际是先构造成 Node 对象, 再进行保存, 如下:
// 如果没有下一个节点, next 设置为空
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}putVal()
/**
* hash: key的哈希值
* key
* value
* onlyIfAbsent: 如果为 true, 不会覆盖原来的值
* evict: 只有 afterNodeInsertion(evict) 会用到这个参数, 但是这个方法什么都没做
* 如果数组存在本身存在相同的 key, 结果会返回原来的值, 如果没有, 就返回空值
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// tab 表示数组, p 表示节点, n 表示数组长度, i表示索引值
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 对于数组为空, 首先是要初始化数组, 详情看 resize 方法
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 对应索引没有节点, 把新节点保存上去
// p 被赋值索引位置对应节点, 也就是父节点
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 索引位置已经有节点, 那么要进行链表或者树保存了
else {
// e 表示临时节点, k 表示临时 key
Node<K,V> e; K k;
// 比较父节点与新节点的哈希值, 实际可以不比较, 毕竟索引值一样说明哈希值也一样
// 当前节点 key 与新节点 key 比较, 相等就用 e 指向当前节点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 父节点 key 和新节点 key 不等, 并且是树型结构, 那么遍历树找到对应位置
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 父节点 key 和新节点 key 不等, 并且是链表结构, 那么遍历链表找到对应位置
else {
// binCount 表示链表长度, 开始遍历链表
for (int binCount = 0; ; ++binCount) {
// 当前节点的 next 为空, 说明这是最后一个节点
if ((e = p.next) == null) {
// 新建节点加到链表最后
p.next = newNode(hash, key, value, null);
// 如果链表长度超过 8, 把链表转换成树结构
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 当前节点 key 和新节点 key 相等, 终止链表的遍历
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
// p 指向下一个节点
p = e;
}
}
// 经过上面遍历, 如果数组本身已经保存与新节点 key 相等的节点, e 就会指向这个节点
// 否则 e 会指向树或者链表的最后, 也就是空
// 对于非空的 e, 视情况是否替换新的值
// afterNodeAccess 是空方法, 什么都不做
// 因为节点数量不变, 不需要扩容数组, 所以直接返回就行
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
// 记录 HashMap 结构修改的次数, 没用过
++modCount;
// 节点数量大于阈值, 数组将会被扩容
if (++size > threshold)
resize();
// 空方法
afterNodeInsertion(evict);
return null;
}这里用到了关于树的两个方法, 一个给树新增节点的 putTreeVal, 另一个是把链表转换成树结构的 treeifyBin, 这两个方法留到下一 part 讲.