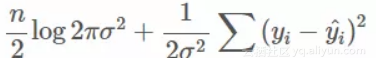让我从年初的一个flag说起:
我的新年目标:我在2018年期间绘制的每一幅图表都要包含不确定性估算
为什么立下这个flag?因为我在各种大会上听腻了人们争论每个月微件(widget)的数量是上升还是下降,或者微件方法X是否比微件方法Y更有效率。
而且我发现,对于几乎任何图表,量化不确定性都很有用,所以我也开始尝试。
然而我很快发现,我给自己挖了个深坑。几个月后:
现在已经是今年的第4个月,我要告诉你,估算不确定性的水还挺深。
我从未学过统计学,也没有通过机器学习来逆向了解过它。所以我算是半路出家,在慢慢自学统计知识。今年早些时候,我还只了解一些关于Bootstrapping算法(拔靴法)和置信区间的基本知识,但随着时间的推移,我学会了蒙特卡罗方法和逆Hessians矩阵(黑塞矩阵)等全套把戏。
这些方法很有用,我也想把这一年的经营教训分享给大家。
从数据开始
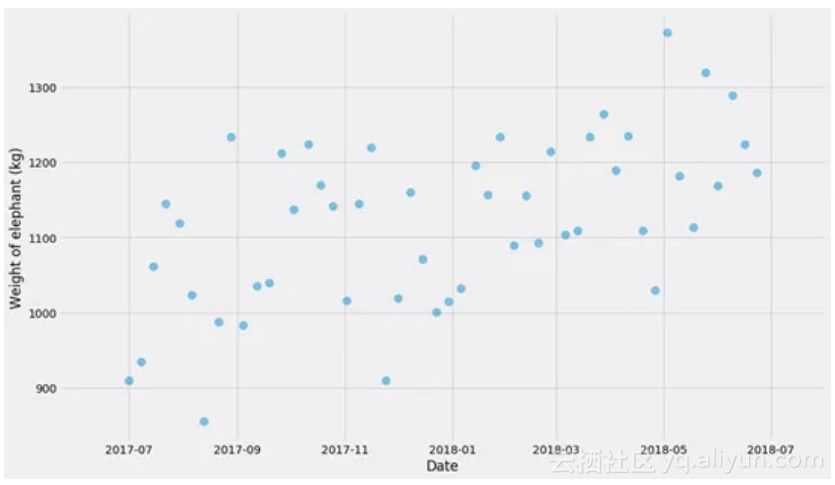
我相信没有具体例子是无法真正学到东西的,所以让我们先制造一些数据。我们将生成一个假的时间系列,其日期范围从2017-07-01至2018-07-31,比如说这个序列是一头大象重量的观测值。
def
generate_time_series
(k=
200
, m=
1000
, sigma=
100
, n=
50
,
start_date=datetime.date(
2017
,
7
,
1
)):
xs = numpy.linspace(
0
,
1
, n, endpoint=
False
)
ys = [k*x + m + random.gauss(
0
, sigma)
for
x
in
xs]
ts = [start_date + datetime.timedelta(x)*
365
for
x
in
xs]
x_scale = numpy.linspace(
-1
,
2
,
500
)
# for plotting
t_scale = [start_date + datetime.timedelta(x)*
365
for
x
in
x_scale]
return
xs, ys, ts, x_scale, t_scale
xs, ys, ts, x_scale, t_scale = generate_time_series()
在开始之前,我们需要做图来看看发生了什么!
pyplot
.scatter(ts, ys, alpha=
0.5
, s=
100
)
pyplot
.xlabel(
'Date'
)
pyplot
.ylabel(
'Weight of elephant (kg)'
)
首先,我们不用任何花哨的模型,我们只是将其分解为几个区间(bucket)并计算每个区间的平均值。不过,让我们先停下来谈谈不确定性。
数据分布与不确定性
之前我一直搞不清“不确定性”的意思,但我认为搞清楚这一点非常重要。我们可以为多种不同的数据估算分布:
1. 数据本身。给定一定的时间范围(t ,t '),在这个时间间隔内大象体重的分布是什么?
2.某些参数的不确定性。如参数k在线性关系y = k t + m里,或者某些估算器的不确定性,就像许多观测值的平均值一样。
3.预测数值的不确定性。因此,如果我们预测日期为t(可能在未来)时大象的重量是y公斤,我们想知道数量y的不确定性。
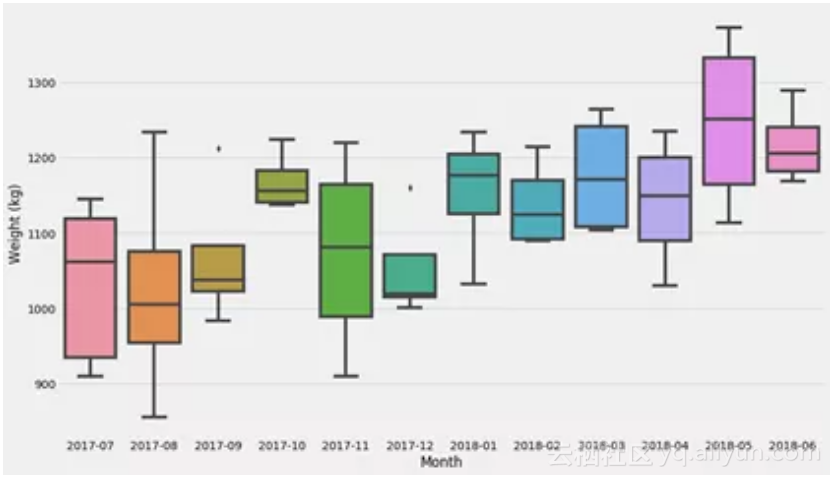
让我们从最基本的模型开始 - 只需在区间中分解问题。如果我们只是想学习一些关于分布和不确定性估计的基本概念,那么我推荐Seaborn软件包。Seaborn通常在数据帧上运行,因此我们需要进行转换:
d = pandas.DataFrame({
'x'
: xs,
't'
:
ts
,
'Weight (kg)'
: ys})
d[
'Month'
] = d[
't'
].apply(lambda
t:
t.
strftime
(
'%Y-%m'
))
seaborn.boxplot(data=d,
x
=
'Month'
,
y
=
'Weight (kg)'
)
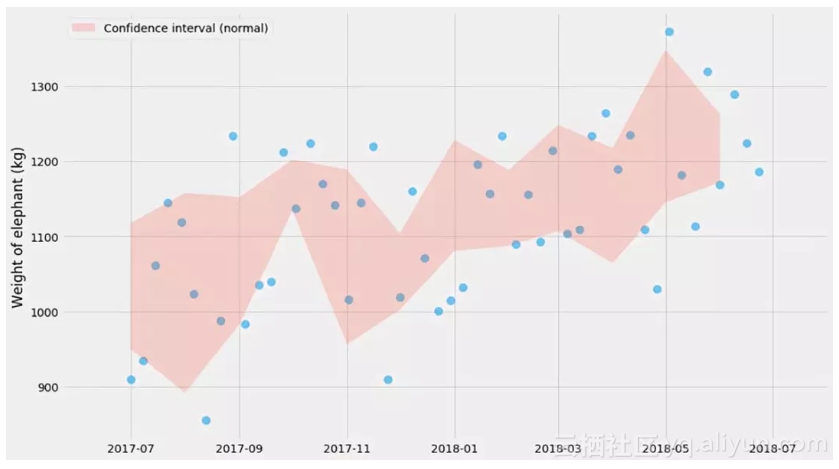
最后的图表显示了数据集的分布。现在让我们试着弄清楚一个非常常见的估算器的不确定性:均值!
计算均值的不确定性 - 正态分布
在一些宽松的假设下(我一会儿回来仔细研究它),我们可以计算均值估计量的置信区间:
这里¯ X是平均值和σ是标准差,也就是方差的平方根。我不认为记住这个公式非常重要,但我觉得记住置信区间的大小与样本数的平方根成反比这个关系还是有点用的。例如,这在当你运行的A/B测试是有用的-如果你要检测1%的差异,那么你需要大约0.01−2=10,000个样本。(这只是经验值,不要把它用于你的医疗设备软件)。
顺便说一句 – 数值1.96是怎么来的?它与不确定性估计的大小直接相关。± 1.96意味着你将覆盖概率分布的95%左右。
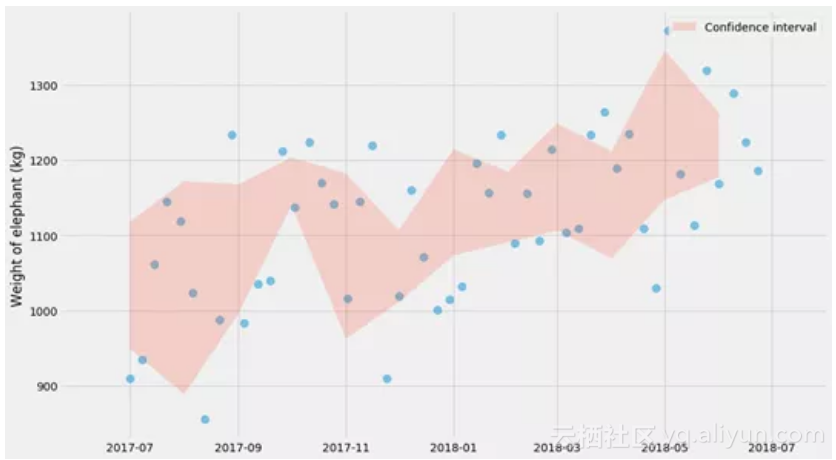
def plot_confidence_interval(observations_by_group):
groups =
list
(sorted(observations_by_group.
keys
()))
lo_bound = []
hi_bound = []
for
group in group
s:
series = observations_by_group[group]
mu, std, n = numpy.mean(series), numpy.std(series),
len
(series)
lo_bound.
append
(mu -
1.96
*std*n**-
0.5
)
hi_bound.
append
(mu +
1.96
*std*n**-
0.5
)
pyplot.fill_between(groups, lo_bound, hi_bound, alpha=
0.2
,
label=
'Confidence interval (normal)'
)
pyplot.scatter(
ts
, ys, alpha=
0.5
, s=
100
)
observations_by_month = {}
for
month,
y
in zip(d[
'Month'
], d[
'Weight (kg)'
]):
observations_by_month.setdefault(month, []).
append
(
y
)
plot_confidence_interval(observations_by_month)
pyplot.ylabel(
'Weight of elephant (kg)'
)
pyplot.legend()
请注意,这是指均值的不确定性,这与数据分布本身不是一回事。这就是为什么你看到在红色阴影区域内的蓝色点数远少于95%。如果我们添加更多的点,红色阴影区域将变得越来越窄,而其中蓝色点数仍将具有差不多的比例。然而,理论上真正的平均值应该有95%时间处于红色阴影区域内。
我之前提到,置信区间的公式仅适用于一些宽松的假设。那些假设是什么?是正态的假设。根据中心极限定理,这对于大量的观测值也是可行的。
所有结果为0或1时的置信区间
让我们看看我经常使用的一种数据集:转化。为了论证,我们假设正在进行一个有一定影响的A / B测试,并且我们正试图了解各州对转化率的影响。转化结果是0或1。生成此数据集的代码并不是非常重要,因此不要过多关注:
STATES = [
'CA'
,
'NY'
,
'FL'
,
'TX'
,
'PA'
,
'IL'
,
'OH'
]
GROUPS = [
'test'
,
'control'
]
def
generate_binary_categorical
(states=STATES, groups=GROUPS, k=
400
,
zs=[
0
,
0.2
], z_std=
0.1
, b=
-3
, b_std=
1
):
# Don't pay too much attention to this code. The main thing happens in
# numpy.random.binomial, which is where we draw the "k out of n" outcomes.
output = {}
e_obs_per_state = numpy.random.exponential(k, size=len(states))
state_biases = numpy.random.normal(b, b_std, size=len(states))
for
group, z
in
zip(groups, zs):
noise = numpy.random.normal(z, z_std, size=len(states))
ps =
1
/ (
1
+ numpy.exp(-(state_biases + noise)))
ns = numpy.random.poisson(e_obs_per_state)
ks = numpy.random.binomial(ns, ps)
output[group] = (ns, ks)
return
output
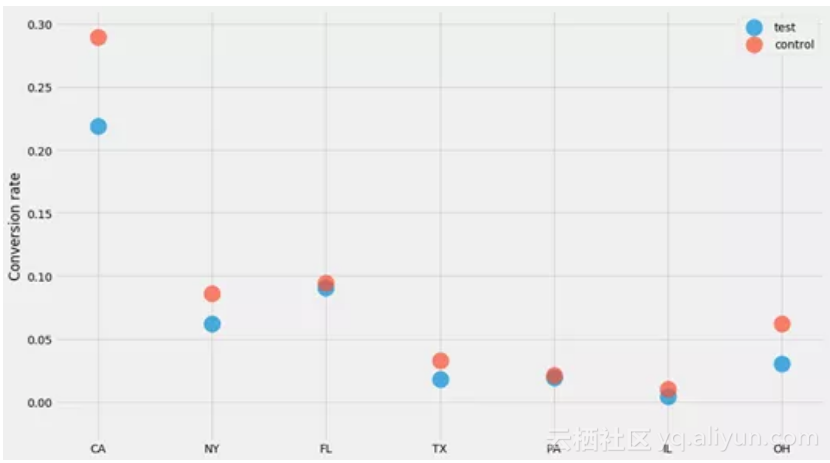
对于每个州和每个“组”(测试和控制),我们生成了n个用户,其中k个已转化。让我们绘制每个州的转化率,看看发生了什么!
data = generate_binary_categorical()
for
group, (ns, ks)
in
data.items():
pyplot.scatter(STATES, ks/ns, label=group, alpha=
0.7
, s=
400
)
pyplot.ylabel(
'Conversion rate'
)
pyplot.legend()
由于所有结果都是0或1,并且以相同(未知)概率绘制,我们知道1和0的数量遵循二项分布。这意味着“n个用户中 k个已转化”的情形的置信区间是Beta分布。
记住置信区间的公式使我获益良多,而且我觉得比起我以前用的(基于法线的)公式,我可能更倾向用它。特别需要记住的是:
n, k =
100
,
3
scipy.stats.beta.ppf([
0.025
,
0.975
], k, n-k)
array([
0.00629335
,
0.07107612
])
代入n和k的值可以算出95%的置信区间。在这个例子里,我们看到如果我们有100个网站访问者,其中3个购买了产品,那么置信区间就是0.6%-7.1%。
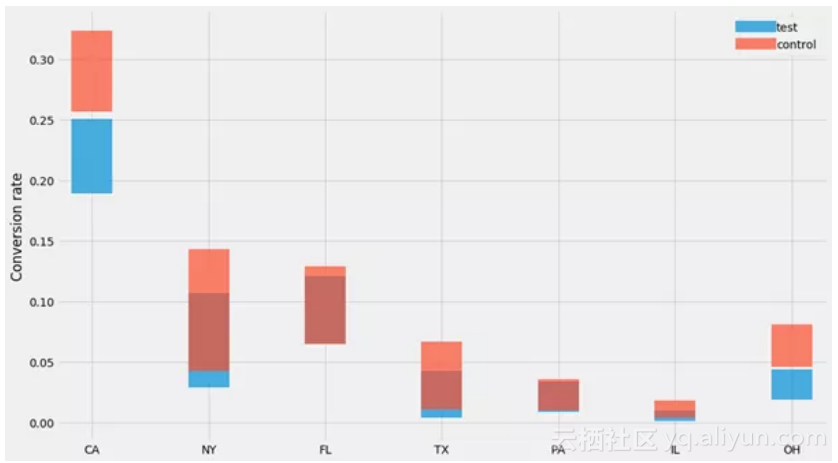
让我们用我们的数据集试试:
for
group, (ns, ks)
in
data.items():
lo = scipy.stats.beta.ppf(
0.025
, ks, ns-ks)
hi = scipy.stats.beta.ppf(
0.975
, ks, ns-ks)
mean = ks/ns
pyplot.errorbar(STATES, y=mean, yerr=[mean-lo, hi-mean],
label=group, alpha=
0.7
, linewidth=
0
, elinewidth=
50
)
pyplot.ylabel(
'Conversion rate'
)
pyplot.legend()
哎哟不错噢~
Bootstrapping算法(拔靴法)
另一种有用的方法是bootstrapping算法(拔靴法),它允许你在无需记忆任何公式的情况下做同样的统计。这个算法的核心是计算均值,但是是为n次再抽样(bootstrap)计算均值,其中每个bootstrap是我们观测中的随机样本(替换)。对于每次自助抽样,我们计算平均值,然后将在97.5%和2.5%之间的均值作为置信区间:
lo_bound = []
hi_bound = []
months = sorted(observations_by_month.keys())
for
month
in
months:
series = observations_by_month[month]
bootstrapped_means = []
for
i
in
range(
1000
):
# sample with replacement
bootstrap = [random.choice(series)
for
_
in
series]
bootstrapped_means.append(numpy.mean(bootstrap))
lo_bound.append(numpy.percentile(bootstrapped_means,
2.5
))
hi_bound.append(numpy.percentile(bootstrapped_means,
97.5
))
pyplot.scatter(ts, ys, alpha=
0.5
, s=
100
)
pyplot.fill_between(months, lo_bound, hi_bound, alpha=
0.2
,
label=
'Confidence interval'
)
pyplot.ylabel(
'Weight of elephant (kg)'
)
pyplot.legend()
神奇吧,这些图表与之前的图表非常相似!(正如我们本该期待的那样)
Bootstrapping算法很不错,因为它可以让你回避了任何关于生成数据的概率分布的问题。虽然它可能有点慢,但它基本上是即插即用的,并且几乎适用于所有问题。
不过请注意bootstrapping也存在不可用的情形。我的理解是,当样本数量趋于无穷大时,bootstrapping会收敛到正确的估计值。但如果你使用的是小样本集,你会得到不靠谱的结果。我通常不会相信对任何少于50个样本的问题的bootstrapping再抽样,所以你最好也不要这样做。
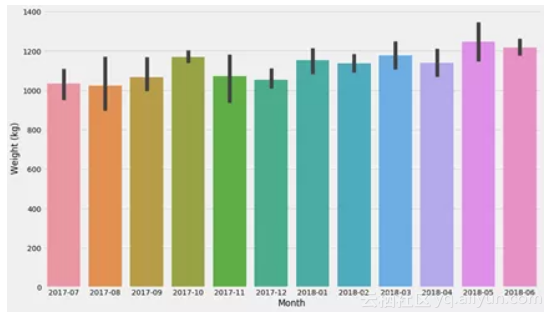
边注,Seaborn的 barplot实际上使用bootstrapping来绘制置信区间:
seaborn.barplot(data=d, x='Month', y='Weight (kg)')
同样,Seaborn非常适合进行探索性分析,其中一些图表可以用于基本的统计。
回归
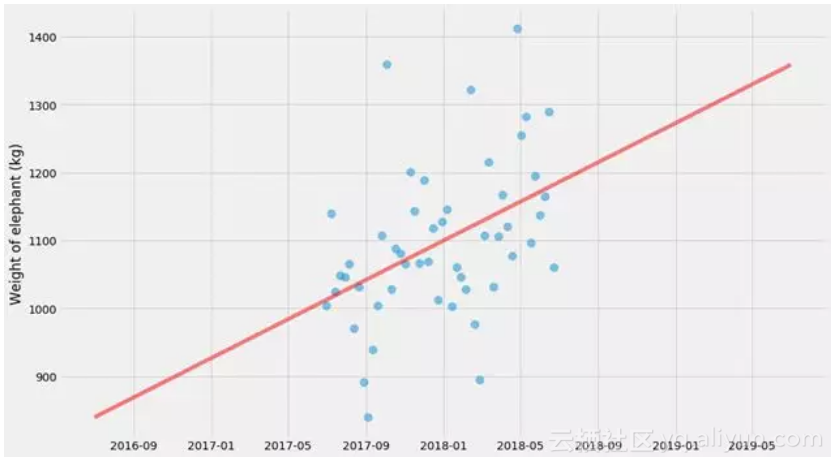
让我们提高一个档次。我们将在这一群点上做一个线形回归。
我将以我认为最普遍的方式来做这件事。我们将定义一个模型(在这种情况下是一条直线),一个损失函数(与该直线的平方偏差),然后使用通用求解器(scipy.optimize.minimize)对其进行优化。
xs, ys, ts, x_scale, t_scale = generate_time_series()
def
model
(xs, k, m):
return
k * xs + m
def
l2_loss
(tup, xs, ys):
k, m = tup
delta = model(xs, k, m) - ys
return
numpy.dot(delta, delta)
k_hat, m_hat = scipy.optimize.minimize(l2_loss, (
0
,
0
), args=(xs, ys)).x
pyplot.scatter(ts, ys, alpha=
0.5
, s=
100
)
pyplot.plot(t_scale, model(x_scale, k_hat, m_hat), color=
'red'
,
linewidth=
5
, alpha=
0.5
)
pyplot.ylabel(
'Weight of elephant (kg)'
)
具有不确定性的线性回归,使用最大似然方法
我们只拟合k和m,但这里没有不确定性估计。有几件事我们可以估计不确定性,但让我们从预测值的不确定性开始。
我们可以通过在拟合k和m的同时在直线周围拟合正态分布来做到这一点。我将使用最大似然方法来做到这一点。如果你不熟悉这种方法,不要害怕!如果统计学存在方法能够很容易实现(它是基本概率理论)并且很有用,那就是这种方法。
实际上,最小化平方损失(我们刚刚在前面的片段中做过)实际上是最大可能性的特殊情况!最小化平方损失与最大化所有数据概率的对数是一回事。这通常称为“对数似然”。
所以我们已经有一个表达式来减少平方损失。如果我们使方差为未知变量σ2,我们可以同时拟合它!我们现在要尽量减少的数量变成了
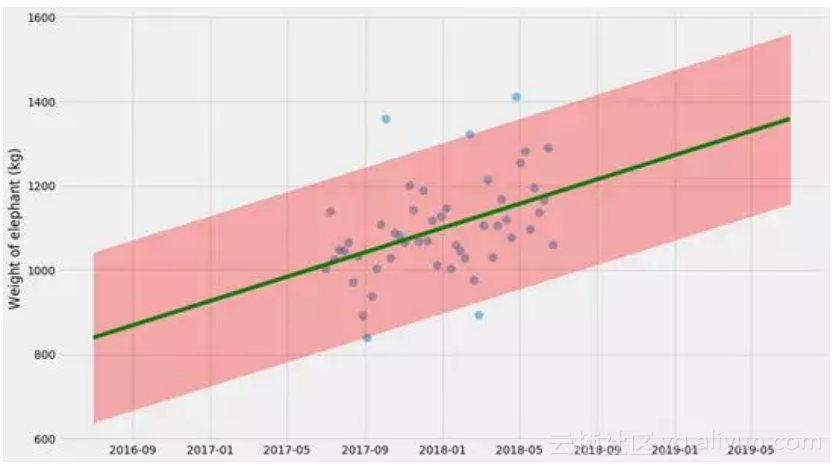
在这里 ^yi=kxi+m是我们模型的预测值。让我们尝试拟合它!
import
scipy.optimize
def
neg_log_likelihood
(tup, xs, ys):
# Since sigma > 0, we use use log(sigma) as the parameter instead.
# That way we have an unconstrained problem.
k, m, log_sigma = tup
sigma = numpy.exp(log_sigma)
delta = model(xs, k, m) - ys
return
len(xs)/
2
*numpy.log(
2
*numpy.pi*sigma**
2
) + \
numpy.dot(delta, delta) / (
2
*sigma**
2
)
k_hat, m_hat, log_sigma_hat = scipy.optimize.minimize(
neg_log_likelihood, (
0
,
0
,
0
), args=(xs, ys)
).x
sigma_hat = numpy.exp(log_sigma_hat)
pyplot.scatter(ts, ys, alpha=
0.5
, s=
100
)
pyplot.plot(t_scale, model(x_scale, k_hat, m_hat),
color=
'green'
, linewidth=
5
)
pyplot.fill_between(
t_scale,
model(x_scale, k_hat, m_hat) -
1.96
*sigma_hat,
model(x_scale, k_hat, m_hat) +
1.96
*sigma_hat,
color=
'red'
, alpha=
0.3
)
pyplot.legend()
pyplot.ylabel(
'Weight of elephant (kg)'
)
这里的不确定性估计实际上不是100%,因为它没有考虑k,m和σ本身的不确定性。这是一个不错的近似,但要做到正确,我们需要同时做这些事情。所以我们这样做吧。
再次启用Bootstrapping!
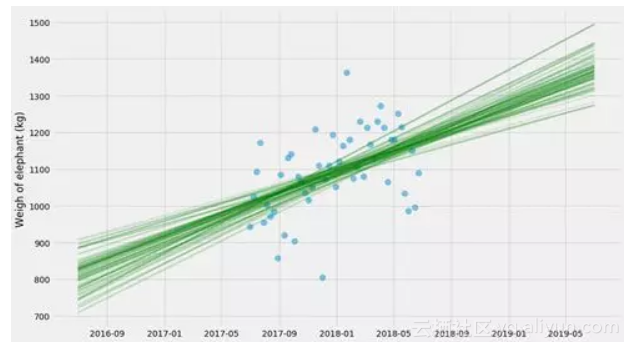
所以让我们把它提升到一个新的水平,并尝试估计k和m和σ的不确定性估计! 我认为这将显示bootstrapping基本上是如何切割 - 你可以将它插入几乎任何东西,以估计不确定性。
对于每个bootstrap估计,我将绘制一条线。我们也可以采用所有这些线并计算置信区间:
pyplot.scatter(ts, ys, alpha=
0.5
, s=
100
)
xys = list(zip(xs, ys))
curves = []
for
i
in
range(
100
):
# sample with replacement
bootstrap = [random.choice(xys)
for
_
in
xys]
xs_bootstrap = numpy.array([x
for
x, y
in
bootstrap])
ys_bootstrap = numpy.array([y
for
x, y
in
bootstrap])
k_hat, m_hat = scipy.optimize.minimize(
l2_loss, (
0
,
0
), args=(xs_bootstrap, ys_bootstrap)
).x
curves.append(model(x_scale, k_hat, m_hat))
# Plot individual lines
for
curve
in
curves:
pyplot.plot(t_scale, curve, alpha=
0.1
, linewidth=
3
, color=
'green'
)
# Plot 95% confidence interval
lo, hi = numpy.percentile(curves, (
2.5
,
97.5
), axis=
0
)
pyplot.fill_between(t_scale, lo, hi, color=
'red'
, alpha=
0.5
)
pyplot.ylabel(
'Weight of elephant (kg)'
)
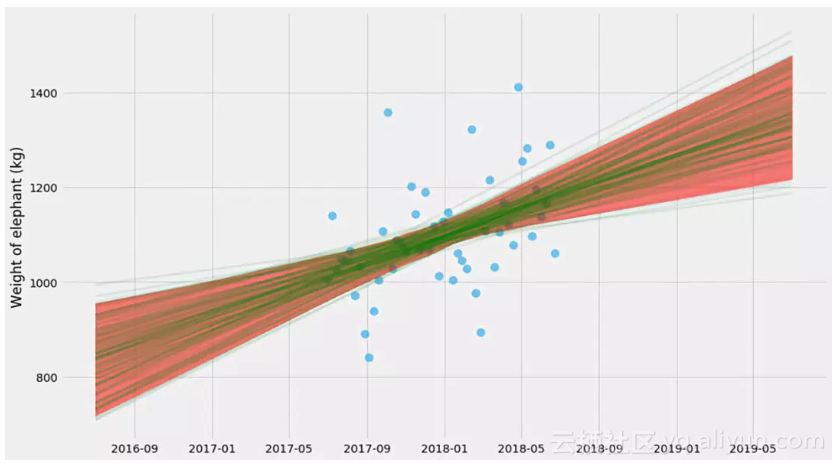
哇,这里发生了什么?这种不确定性与之前的情节非常不同。这看起来很混乱,直到你意识到他们展示了两个非常不同的东西:
● 第一个图找到k和m的一个解,并显示预测的不确定性。所以,如果你被问到下个月大象体重的范围是什么,你可以从图表中得到它。
● 第二个图找到了k和m的许多解,并显示了kx + m的不确定性。因此,这回答了一个不同的问题 - 大象体重随时间变化的趋势是什么,趋势的不确定性是什么?
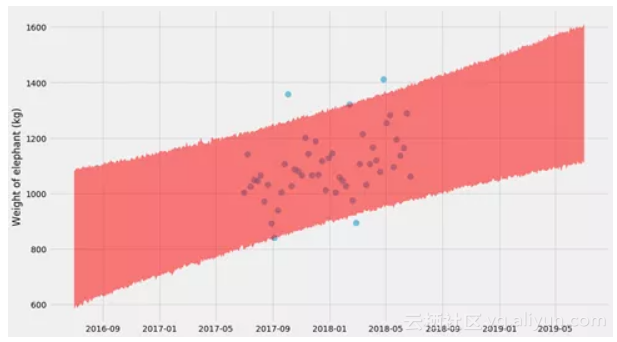
事实证明,我们可以将这两种方法结合起来,并通过拟合绘制bootstrapping样本并同时拟合k,m和σ使其更加复杂。然后,对于每个估算,我们可以预测新值y。我们这样做:
pyplot.scatter(ts, ys, alpha=
0.5
, s=
100
)
xys = list(zip(xs, ys))
curves = []
for
i
in
range(
4000
):
# sample with replacement
bootstrap = [random.choice(xys)
for
_
in
xys]
xs_bootstrap = numpy.array([x
for
x, y
in
bootstrap])
ys_bootstrap = numpy.array([y
for
x, y
in
bootstrap])
k_hat, m_hat, log_sigma_hat = scipy.optimize.minimize(
neg_log_likelihood, (
0
,
0
,
0
), args=(xs_bootstrap, ys_bootstrap)
).x
curves.append(
model(x_scale, k_hat, m_hat) +
# Note what's going on here: we're _adding_ the random term
# to the predictions!
numpy.exp(log_sigma_hat) * numpy.random.normal(size=x_scale.shape)
)
# Plot 95% confidence interval
lo, hi = numpy.percentile(curves, (
2.5
,
97.5
), axis=
0
)
pyplot.fill_between(t_scale, lo, hi, color=
'red'
, alpha=
0.5
)
pyplot.ylabel(
'Weight of elephant (kg)'
)
哎呦,又不错!它现在变得很像回事了 - 如果仔细观察,你会看到一个双曲线形状!
这里的技巧是,对于(k,m,σ)的每个bootstrap估计,我们还需要绘制随机预测。正如您在代码中看到的,我们实际上是将随机正态变量添加到y的预测值。这也是为什么这个形状最终变成一个大波浪形的原因。
不幸的是,bootstrapping对于这个问题来说相当缓慢 - 对于每个bootstrap,我们需要拟合一个模型。让我们看看另一个选项:
马尔可夫链蒙特卡罗方法
现在它会变得有点狂野了~~
我将切换到一些贝叶斯方法,我们通过绘制样本来估计k,m和σ。它类似于bootstrapping,但MCMC有更好的理论基础(我们使用贝叶斯规则从“后验分布”中抽样),并且它通常要快几个数量级。
为此,我们将使用一个名为emcee的库,我发现它很好用。 它所需要的只是一个Log—likelihood函数,我们之前已经定义过了! 我们只需要用它的负数。
import
emcee
xs, ys, ts, x_scale, t_scale = generate_time_series()
def
log_likelihood
(tup, xs, ys):
return
-neg_log_likelihood(tup, xs, ys)
ndim, nwalkers =
3
,
10
p0 = [numpy.random.rand(ndim)
for
i
in
range(nwalkers)]
sampler = emcee.EnsembleSampler(nwalkers, ndim, log_likelihood,
args=[xs, ys])
sampler.run_mcmc(p0,
10000
)
让我们绘制k和m的采样值!
# Grab the last 10 from each walker
samples = sampler.chain[:,
-10
:, :].reshape((
-1
, ndim))
pyplot.scatter(ts, ys, alpha=
0.5
, s=
100
)
for
k, m, log_sigma
in
samples:
pyplot.plot(t_scale, model(x_scale, k, m), alpha=
0.1
,
linewidth=
3
, color=
'green'
)
pyplot.ylabel(
'Weigh of elephant (kg)'
)
这些方法还有一些内容 - 采样有点挑剔,需要一些人工参与才能正常工作。我不想在这里深入解释所有细节,而且我自己就是一个门外汉。但它通常比booststrapping快几个数量级,并且它还可以更好地处理数据更少的情况。
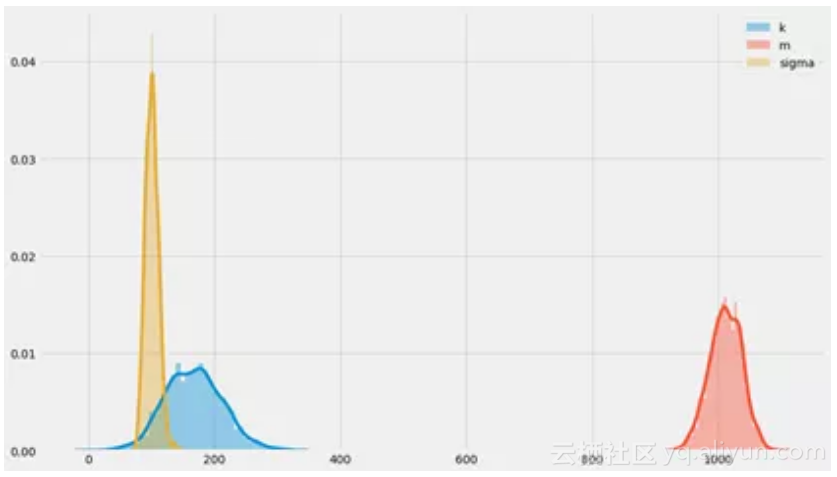
我们最终得到了k,m,σ后验分布的样本。我们可以看看这些未知数的概率分布:
# Grab slightly more samples this time
samples = sampler.chain[:,
-500
:, :].reshape((
-1
, ndim))
k_samples, m_samples, log_sigma_samples = samples.T
seaborn.distplot(k_samples, label=
'k'
)
seaborn.distplot(m_samples, label=
'm'
)
seaborn.distplot(numpy.exp(log_sigma_samples), label=
'sigma'
)
pyplot.legend()
你可以看到围绕k = 200,m = 1000,σ= 100时的分布中心,我们原本也是如此构建它们的!这看起来挺令人放心的~
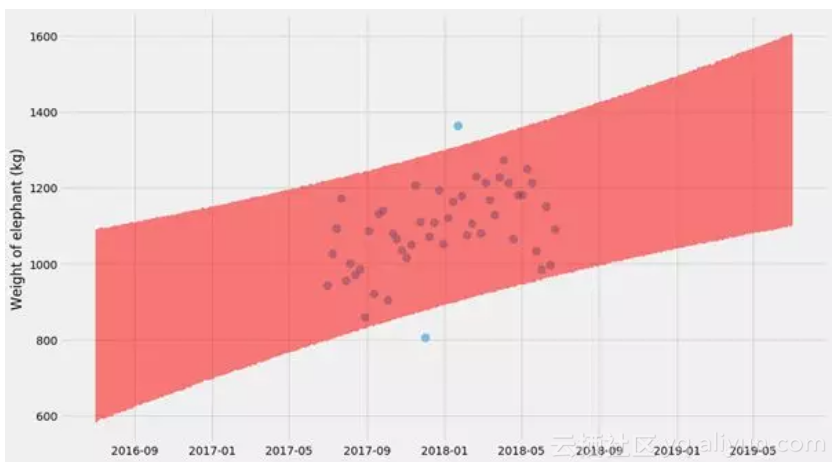
最后,我们可以使用与boostraps相同的方法绘制预测的完全不确定性:
pyplot.scatter(ts, ys, alpha=
0.5
, s=
100
)
samples = sampler.chain[:,
-4000
:, :].reshape((
-1
, ndim))
curves = []
for
k, m, log_sigma
in
samples:
curves.append(
model(x_scale, k, m) +
numpy.exp(log_sigma) * numpy.random.normal(size=x_scale.shape)
)
# Plot 95% confidence interval
lo, hi = numpy.percentile(curves, (
2.5
,
97.5
), axis=
0
)
pyplot.fill_between(t_scale, lo, hi, color=
'red'
, alpha=
0.5
)
pyplot.ylabel(
'Weight of elephant (kg)'
)
这些贝叶斯方法并没有在这里结束。特别是有几个库可以解决这些问题。事实证明,如果您以更结构化的方式表达问题(而不仅仅是负对数似然函数),您可以将采样比例调整为大问题(如数千个未知参数)。对于Python来说,有PyMC3和PyStan,以及稍微更小众一点的Edward和Pyro。
结语
似乎我把你们带进了一个深坑 - 但这些方法其实可以走得更远。事实上,强迫自己估计我做的任何事情的不确定性是一个很好的体验,可以逼着自己学习很多的统计知识。
根据数据做出决策很难!但如果我们对量化不确定性更加严格,我们可能会做出更好的决策。现在要做到这一点并不容易,但我真的希望我们能够使用更便捷的工具,从而看到这些方法的普及。
原文发布时间为:2018-11-27