接触过机器学习的小伙伴都应该知道,梯度下降法并不是一个机器学习算法,而是一种基于搜索的最优化方法,在机器学习尤其是深度学习的凸优化中使用尤为广泛。给定一个损失函数,如果该函数是凸函数,在学习率合适的情况下,它能够快速搜索到极小值。类似的还有梯度上升法,只是变换下正负号而已,一个是最大化效用函数,一个是最小化损失函数或者成本函数。在求一个函数的最大值或最小值时,沿其梯度方向进行搜索可能是最有效也是最普遍的方法之一。
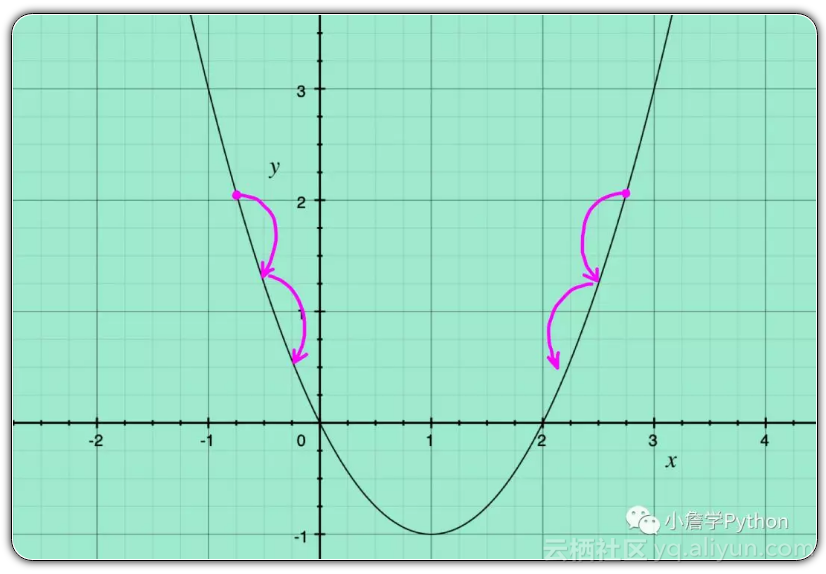
我们拿单一变量的凸函数来举个栗子,如上图。假如搜索的初始点在极小值的右边,其梯度(即导数)为正,则其负梯度方向是从当前位置指向极小值点的方向;假如搜索的初始点在极小值的左边,则其负梯度方向也是为从当前的搜索位置指向局部极小值的。由相关数学证明也可推得连续凸函数的负梯度方向总是指向局部极小值点,正梯度方向总是指向其局部极大值点。同时,也必须控制梯度下降的步长,即需要在梯度之前加上一个系数——学习率,否则可能会导致两个不良后果。
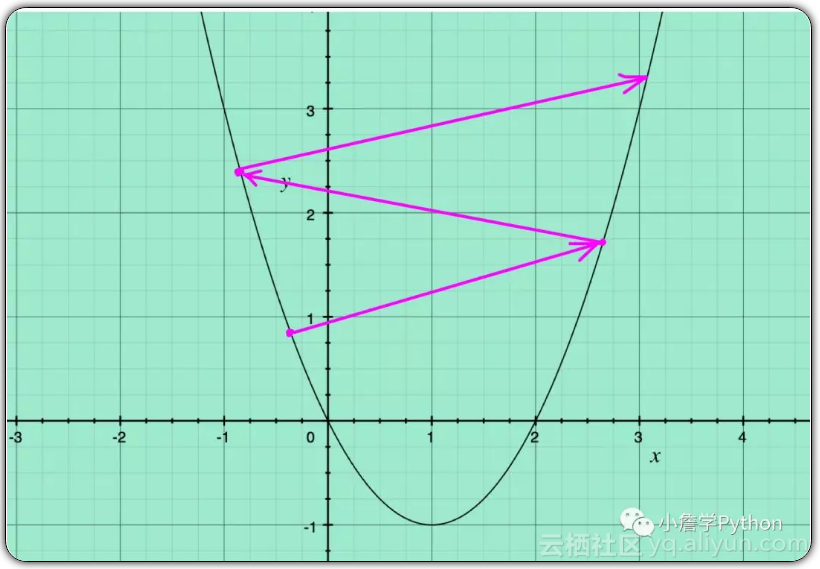
● 在搜索极小值的过程中搜索点在极小值点的周围来回跳动,不断震荡,但是仍然可以收敛到极小值;● 在搜索过程中,所计算的梯度越来越大,甚至导致计算上溢,搜索失败。如下图所示。
所以给梯度下降配上学习率,尤其是选择合适大小的学习率尤其重要。在深度学习中甚至专门有自适应调整学习率的算法,例如大名鼎鼎的 Adam,还有 AdaGrad 和 RMSProp 等,感兴趣的小伙伴去查阅下花书。
因为搜索初始点的关系,我们搜索到的极小值点可能并非是全局极小值点而只是局部极小值点,这依赖于搜索初始点的位置,广泛采用的解决方案就是进行多次搜索,每次都随机的在搜索域产生初始搜索点。重复搜索的次数越多,越有可能找到全局极小值点。
当在学习的过程中如果训练样本非常多的话,因为最终的代价函数是每个样本代价函数的总和,所以再求梯度的时候每个样本点都会参与进去,所以以上的梯度下降也叫做批量梯度下降。较大的训练数据集也意味着较大的计算成本,那我们利用以局部代替整体的思想,从训练数据集中随机抽取出一部分样本点来代替整个数据集,以减小计算开销,其实这就是深度学习中广泛采用的随机梯度下降法。废话有点多,接下来上代码。
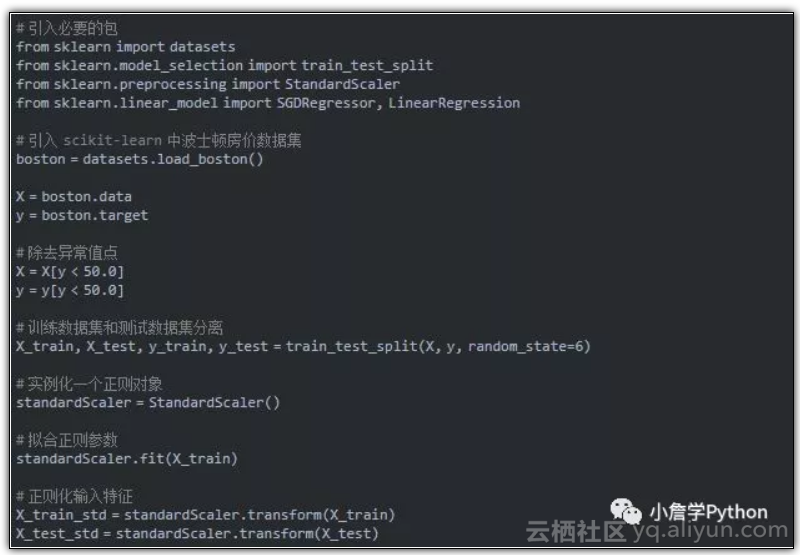
之后实例化一个对象,训练模型求其准确率。

结果:
CPU times: user 2 ms, sys: 941 µs, total: 2.94 msWall time: 1.38 ms0.73551631052094557
实例化一个使用随机梯度下降的线性回归模型。

得到结果:
CPU times: user 902 µs, sys: 469 µs, total: 1.37 msWall time: 766 µs0.74803818104616793
一些细心的小伙伴看到我从 scikit-learn 的 linear_model 直接 import SGDRegressor(),实例化后直接拿去训练而在这过程中并没有传入其他的机器学习模型感到奇怪,因为前面说了梯度下降只是优化算法,而不是机器学习的模型学习算法。
的确是这样,正如注释里所说,scikit-learn 之所以可以这样做是因为它在 SGDRegressor() 中集成的是线性回归,在学习模型的过程中使用的随机梯度下降进行优化搜索,使用了随机梯度下降法的默认模型似乎比没有使用该算法的模型准确率稍微有所提高,训练速度也会稍微快了一些。
接下来我们介绍下一些可调整的超参数,并进行调参,顺便看下调过参后一些模型的表现。
● penalty:正则项的惩罚方式,默认 penalty=’l2’, 使用 L2 正则,‘l1’ 和 ‘elasticnet’ ;
● random_state:shuffle 数据时使用其来种随机种子;
● n_iter:对训练数据集重复训练的次数,深度学习中常用 Epoch 表示;
更多超参数请小伙伴们自行查阅官方文档,我就不啰嗦啦!
设置 n_iter 超参如下,得到对应结果 。

CPU times: user 1.7 ms, sys: 659 µs, total: 2.36 msWall time: 1.17 ms0.74863538201180846
与 sgd_reg 相比只能算是略微的提高,那再变大试试。

CPU times: user 6.8 ms, sys: 789 µs, total: 7.59 ms
Wall time: 6.14 ms0.73539011191275572
聪明的读者有没有发现这个问题,迭代次数增加,精确度并不一定增加 。为啥呢?
已知 n_iter 是训练数据集重复训练的次数,当 n_iter 过大时,很可能是在训练数据集上发生了过拟合,导致模型 sgd_reg3 的准确率与前者相比却有所下降。而且随着 n_iter 的变大,训练时间会延长。
没有免费的午餐定理表明:在所有可能的数据生成分布上平均之后,每一个分类算法在未事先观测的点上都有相同的错误率。换言之,在某种意义上,没有一个机器学习算法总是比其他的要好。最先进的算法和简单地将所有点归为同一类的简单算法有着相同的平均性能。
今天的分享就到这里了,关于 SGDRegressor 模型还有很多其他超参数的调整,请小伙伴们自己在下面亲手操作下,会收获更多哦。还是那句话,如果你们中有大神路过,还请高抬贵脚,勿踩勿喷。好了,期待与小伙伴们共同进步!
原文发布时间为:2018-11-26
本文作者:蜉蝣扶幽
