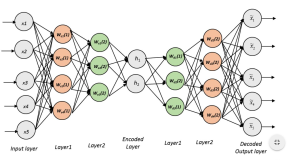
最近在 kaggle 上学习些 keras 的使用方法,这里总结下 AutoEncoder 使用方式
模型定义
对于 AutoEncoder 模型定义有两种方式:
- Encoder 和 Decoder 分开定义,然后通过 Model 进行合并
- Encoder 和 Decoder 同一个 Model 进行定义,在 Encoder 最后一层设置特定名称,然后在取出直接使用即可
分开定义
from operator import mul
from functools import reduce
def product(dset):
return reduce(mul, dset)
def encoder_model(x_shape, y_shape):
"""
定义 Encoder 部分模型,这里将最后一层的数据维度记录下来,作为 Decoder 输入层后的接下来的一层大小
"""
inp = Input(shape=x_shape)
m = Conv2D(16, (3, 3), activation='relu', padding='same')(inp)
m = MaxPooling2D((2, 2), padding='same')(m)
m = Conv2D(8, (3, 3), activation='relu', padding='same')(m)
m = MaxPooling2D((2, 2), padding='same')(m)
m = Conv2D(8, (3, 3), activation='relu', padding='same')(m)
shape = m.shape
m = Flatten()(m)
outp = Dense(y_shape)(m)
return inp, outp, shape[1:]
def decoder_model(x_shape, x_shape_2d):
"""
定义 Decoder 部分模型
"""
inp = Input(shape=x_shape)
m = Dense(product(x_shape_2d))(inp)
# 数据维度的转换 1D 转为 2D
m = Reshape(x_shape_2d)(m)
m = Conv2D(8, (3, 3), activation='relu', padding='same')(m)
m = UpSampling2D((2, 2))(m)
m = Conv2D(8, (3, 3), activation='relu', padding='same')(m)
m = UpSampling2D((2, 2))(m)
outp = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(m)
return inp, outp
# 定义 encoder 模型
encoder_inp, encoder_outp, shape = encoder_model((28, 28, 1), 100)
encoder = Model(inputs=encoder_inp, outputs=encoder_outp)
encoder.summary()
print(shape)
# 定义 decoder 模型
decoder_inp, decoder_outp = decoder_model(encoder_outp.shape[1:], shape)
decoder = Model(inputs=decoder_inp, outputs=decoder_outp)
decoder.summary()
# 定义 autoencoder 模型
autoencoder = Model(inputs=encoder_inp, outputs=decoder(encoder(encoder_inp)), name='autoencoder')
autoencoder.compile(loss='binary_crossentropy', optimizer='adam')
autoencoder.summary()
noise = np.random.normal(loc=0.5, scale=0.5, size=x_train.shape)
x_train_noisy = x_train + noise
noise = np.random.normal(loc=0.5, scale=0.5, size=x_cv.shape)
x_cv_noisy = x_cv + noise
autoencoder.fit(x_train_noisy, x_train, validation_data=(x_cv_noisy, x_cv),
epochs=100, batch_size=128)
同时定义
input_img = Input(shape=(28, 28, 1)) # adapt this if using `channels_first` image data format
x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same', name='encoder')(x)
# at this point the representation is (4, 4, 8) i.e. 128-dimensional
x = Conv2D(8, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(input_img, decoded)
autoencoder.compile(loss='binary_crossentropy', optimizer='adam')
autoencoder.summary()
autoencoder.fit(x_train, x_train, batch_size=64, epochs=100, verbose=1, validation_data=(x_cv, x_cv))
encoder = Model(inputs=autoencoder.input,
outputs=autoencoder.get_layer('encoder').output)
这样通过 AutoEncoder 模型的训练来训练 Encoder 模型
使用 Encoder
x_encoded = encoder.predict(x_cv_noisy)
print(x_encoded[:1])
常见问题
- Loss 高居不下
可以通过如下几个方面进行改善:
- 对输入数据进行归一化,输出的数据很容易拟合
x_train = normalize(x_train).reshape(-1, 28, 28, 1).astype(float32) / 255
# 在 Decoder 输出的内容需要展示为图片时候,简单的乘以 255 即可
x_decoded = autoencoder.predict(x_cv_noisy)
imgs = np.concatenate([x_test[:num], x_cv_noisy[:num], x_decoded[:num]])
imgs = imgs.reshape((rows * 3, cols, image_size, image_size))
imgs = np.vstack(np.split(imgs, rows, axis=1))
imgs = imgs.reshape((rows * 3, -1, image_size, image_size))
imgs = np.vstack([np.hstack(i) for i in imgs])
# 将数据进行还原即可
imgs = (imgs * 255).astype(np.uint8)
- 降低学习率,归一化之后,数据基本都是小数,学习率高了会不容易拟合
sgd = SGD(lr=1e-4, decay=1e-6, momentum=0.4, nesterov=True)
- 修改权重初始化的方式
m = Conv2D(16, 3, activation=LeakyReLU(alpha=0.2), padding='same', kernel_initializer='glorot_normal')(m)
·「参考」
Why my training and validation loss is not changing?
Building Autoencoders in Keras