丰富的线上&线下活动,深入探索云世界
做任务,得社区积分和周边
资深技术专家手把手带教
技术交流,直击现场
让创作激发创新
海量开发者使用工具、手册,免费下载
极速、全面、稳定、安全的开源镜像
开发手册、白皮书、案例集等实战精华
解决隐式内存占用难题
监控vLLM等大模型推理性能
阿里云资深架构师经验分享——DevSecOps最佳实践
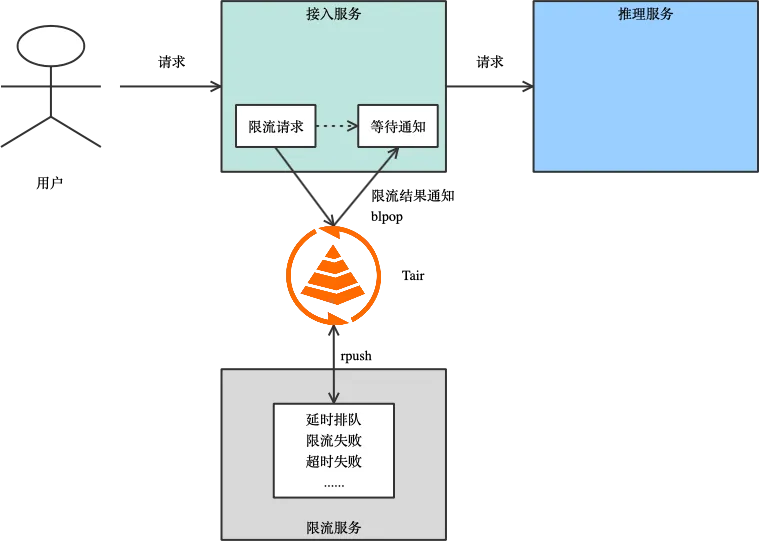
AI 推理场景的痛点和解决方案
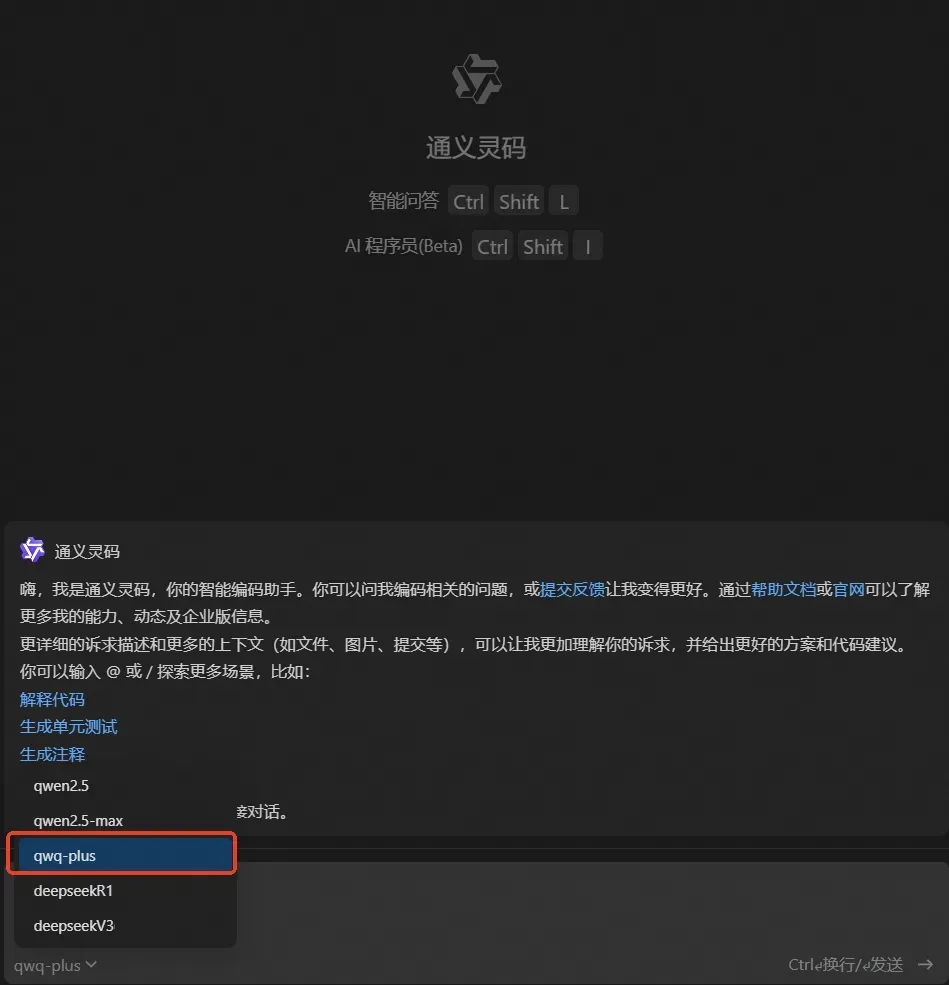
在IDEA中借助满血版 DeepSeek 提高编码效率
【自定义插件系列】0基础在阿里云百炼上玩转大模型自定义插件
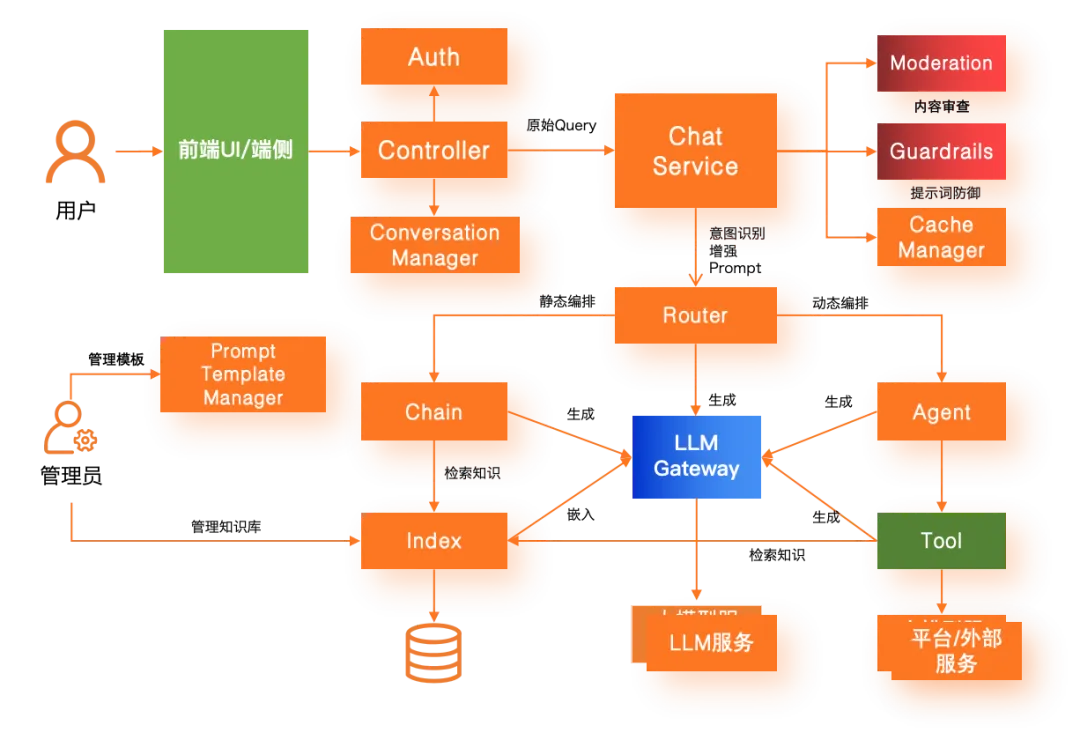
详解大模型应用可观测全链路
大模型无缝切换,QwQ-32B和DeepSeek-R1 全都要
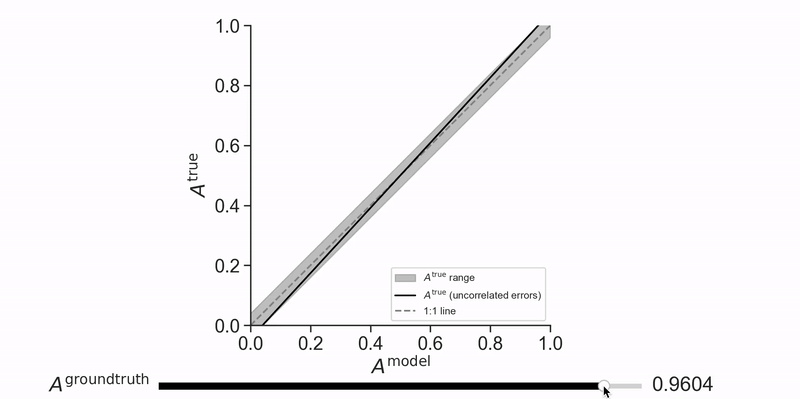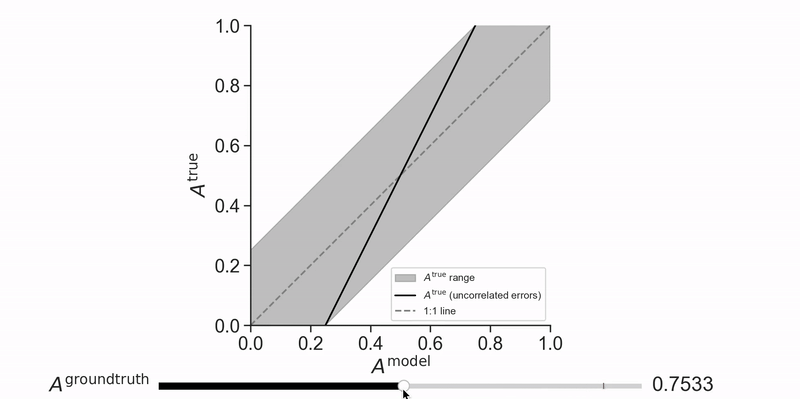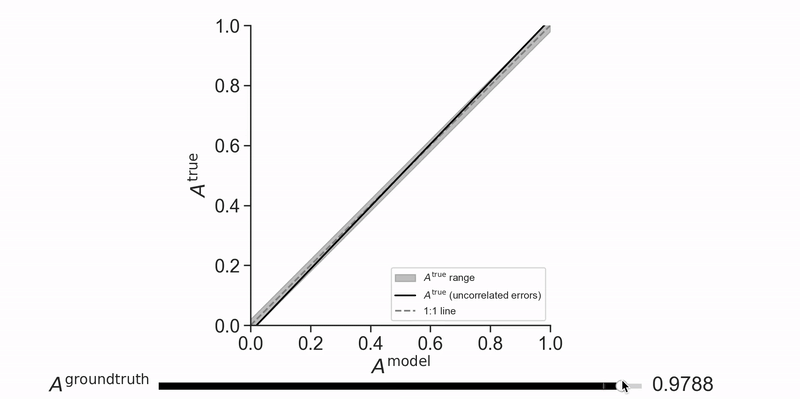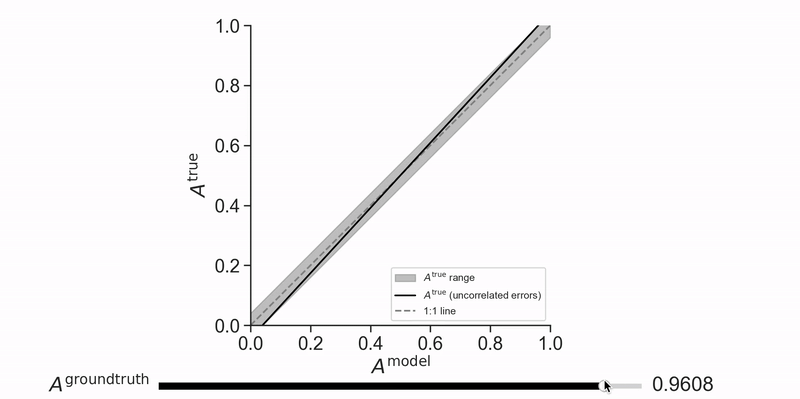
标签噪声下的模型评估:如何准确评估AI模型的真实性能,提高模型性能测量的可信度
YashanDB更换服务器IP
YashanDB离线升级回退
YashanDB滚动升级回退
YashanDB离线升级
解锁YashanDB高效查询的关键功能 Group by分组
YashanDB滚动升级
如何创建Linux交换文件?Linux交换文件最新创建方法
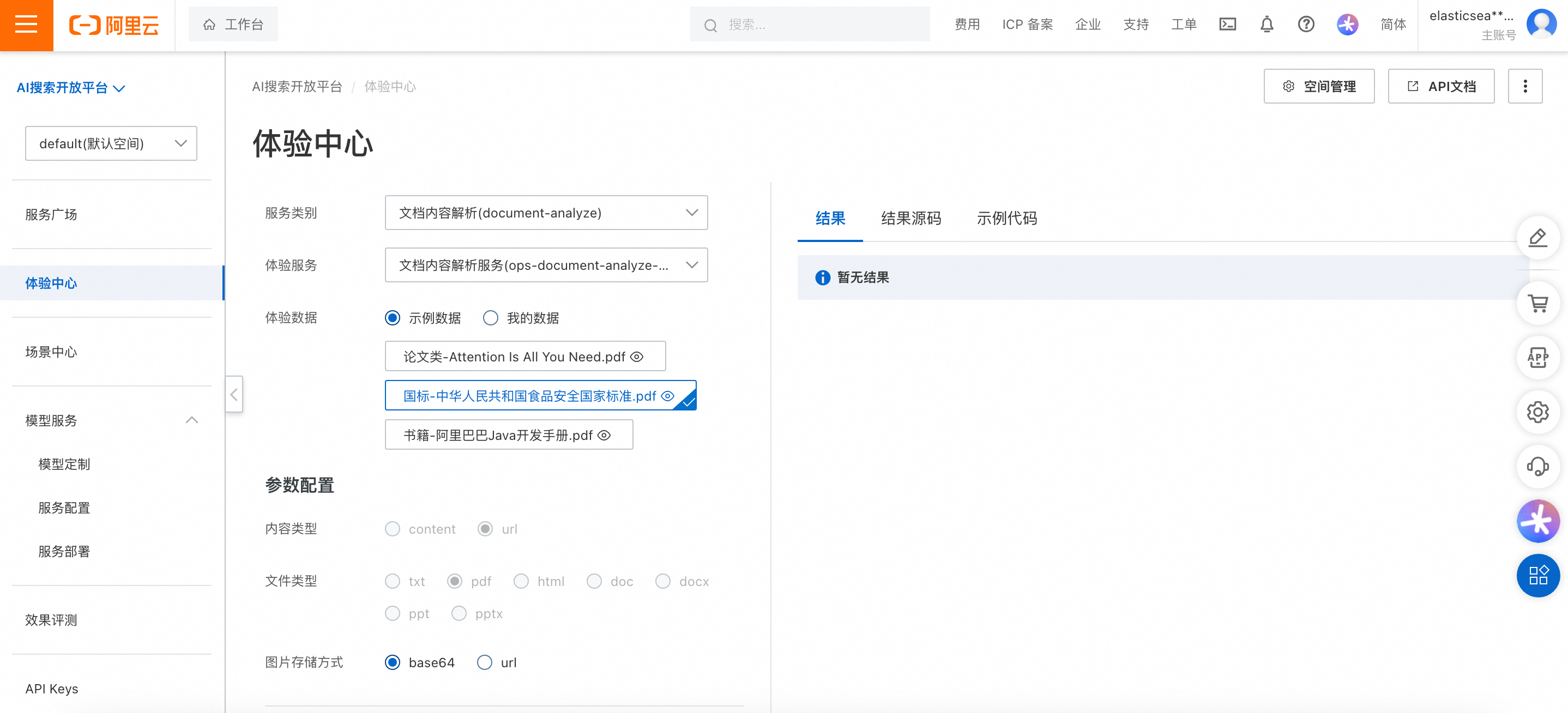
阿里云 AI 搜索开放平台新发布:增加 QwQ 模型
YashanDB升级前准备
YashanDB安装常见问题
YashanDB Linux客户端安装
YashanDB Windows客户端安装
YashanDB初始数据库
YashanDB守护进程
YashanDB环境变量
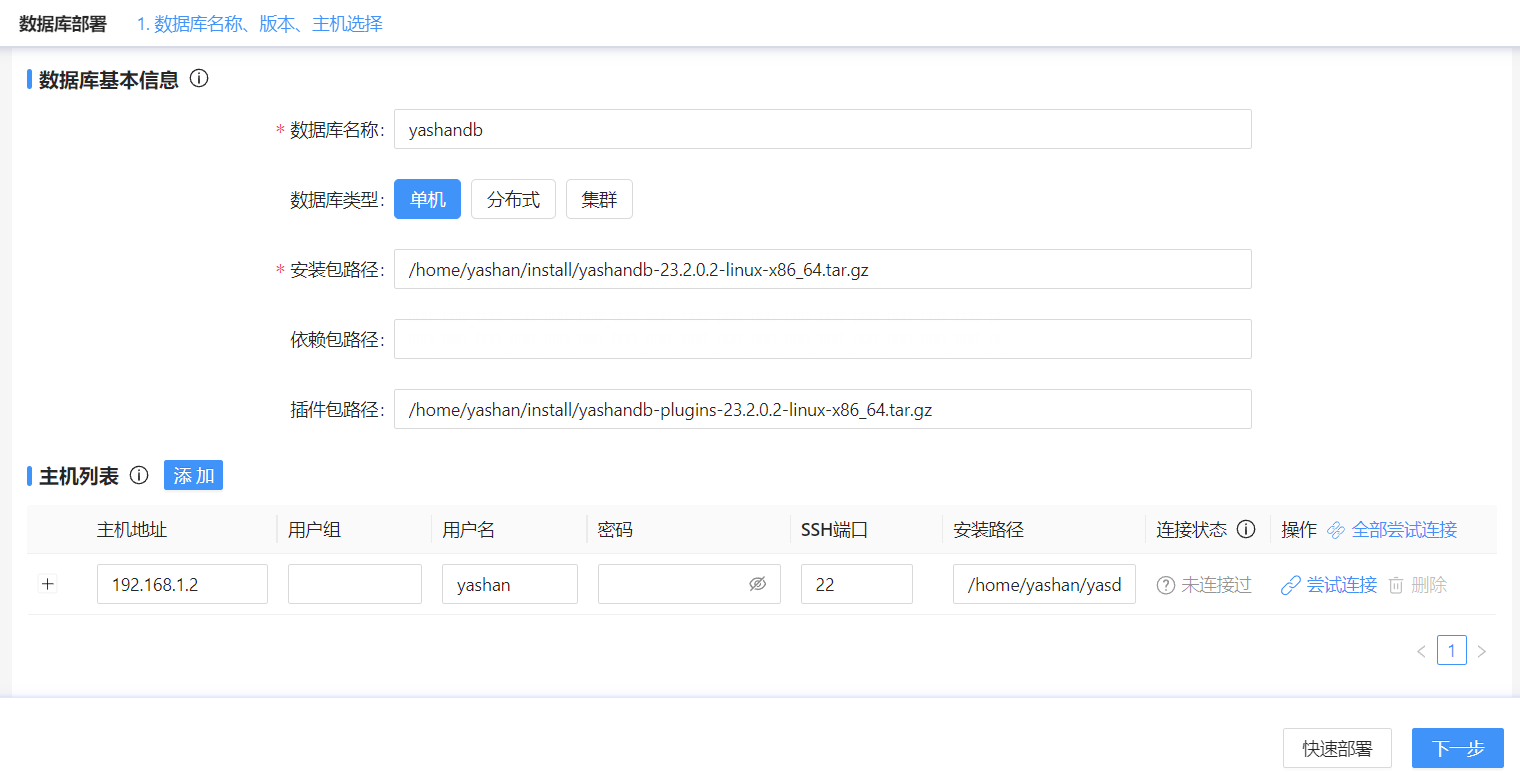
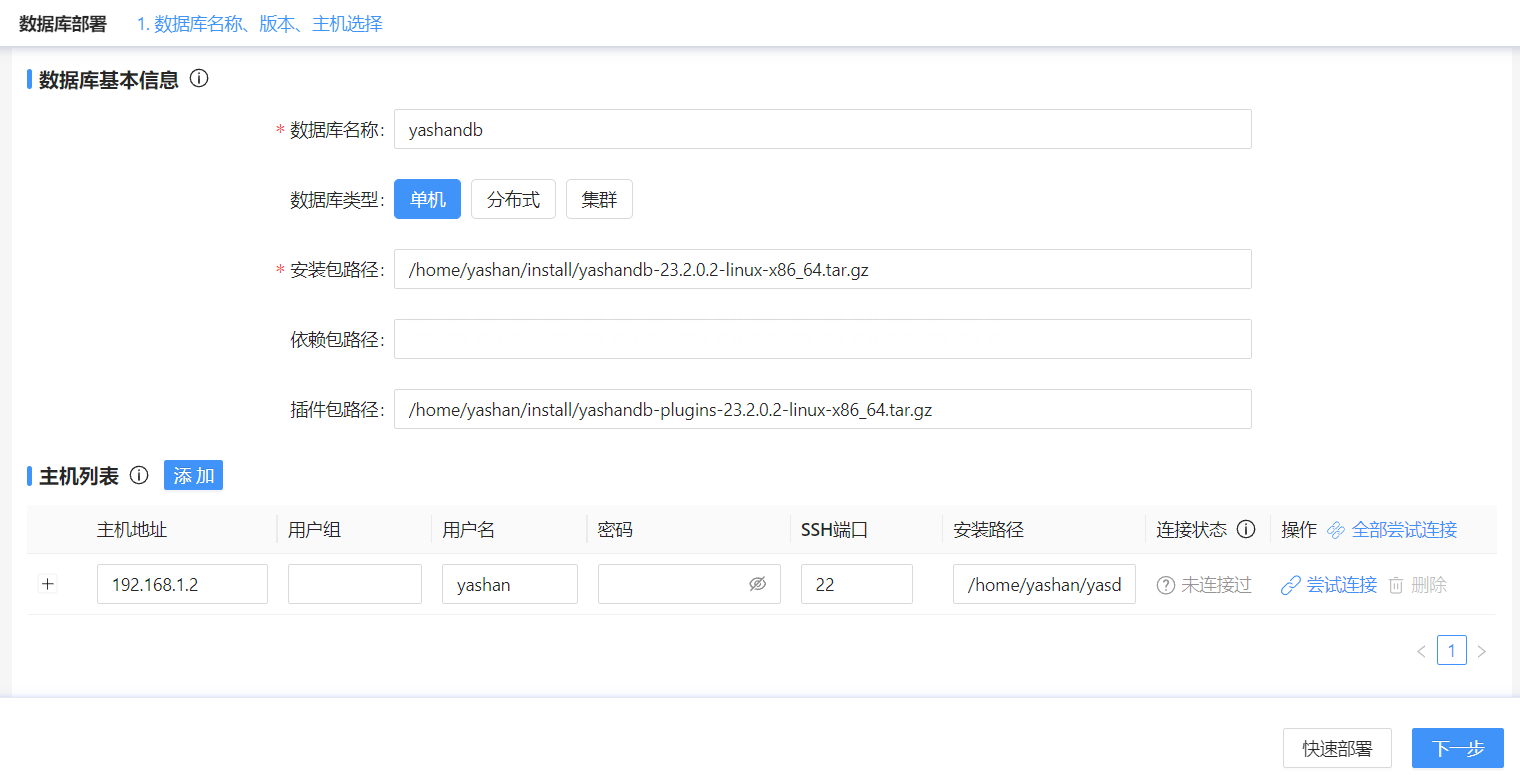
YashanDB分布式可视化部署
关于Node.js,一定要学这个10+万Star项目 !!
YashanDB单机(主备)可视化部署
YashanDB共享集群部署
YashanDB分布式部署
YashanDB服务端安装(命令行)
YashanDB下载软件包方法
YashanDB目录划分
YashanDB安装初始环境调整
YashanDB安装前操作系统参数调整
YashanDB安装前依赖项准备
YashanDB安装前服务器准备
YashanDB安装部署
YashanDB TPC-C测试介绍
YashanDB元数据和数据导入导出
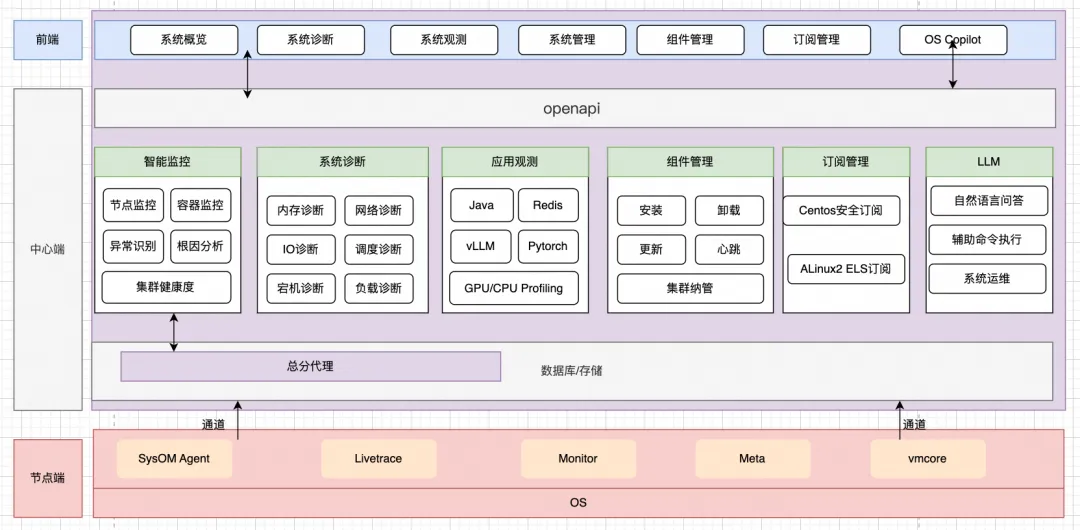
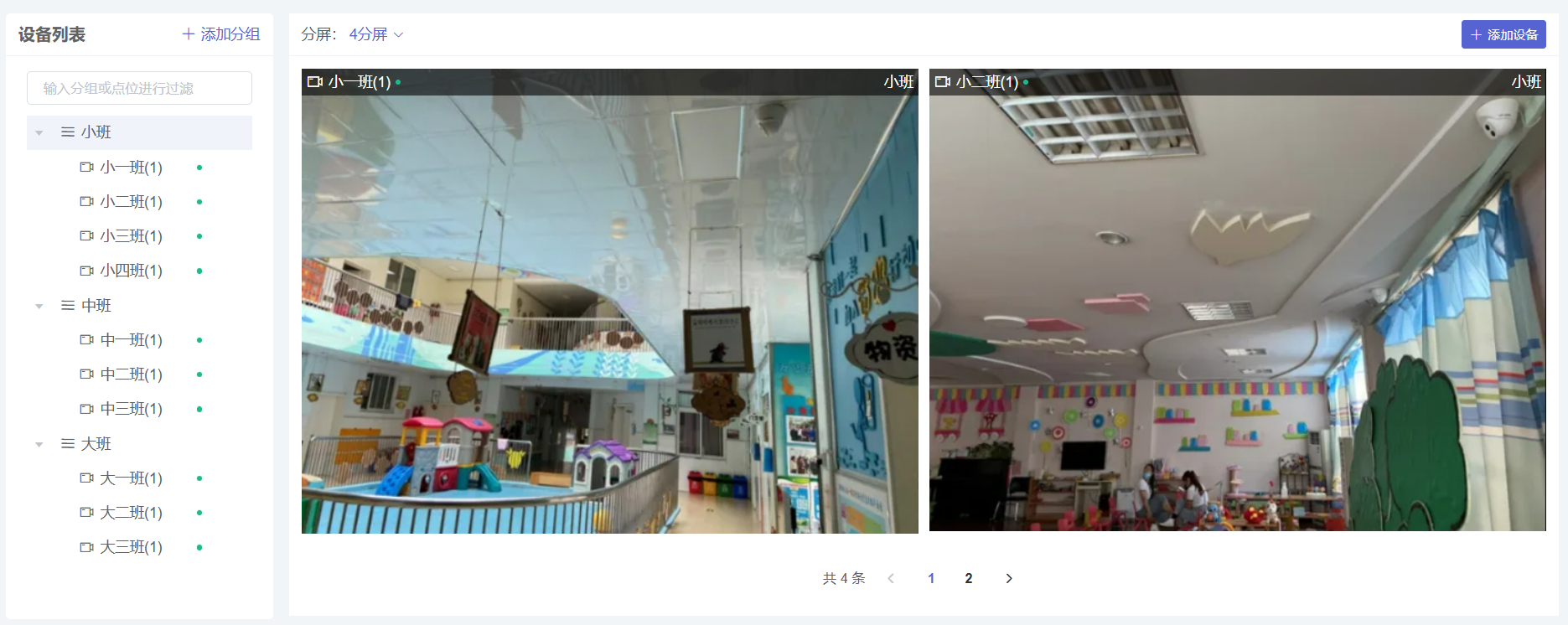
安全监控系统:技术架构与应用解析
YashanDB csv数据快速导入
YashanDB JDBC驱动应用示例
YashanDB事务操作
YashanDB数据操作
销售易与纷享销客产品力对比:谁更胜一筹?
百观科技基于阿里云 EMR 的数据湖实践分享
YashanDB索引操作
建站必备!推荐20款免费WordPress主题下载合集!
YashanDB表操作
社区积分兑好礼