在上一篇关于Python中的线性回归的文章之后,我想再写一篇关于训练测试分割和交叉验证的文章。在数据科学和数据分析领域中,这两个概念经常被用作防止或最小化过度拟合的工具。我会解释当使用统计模型时,通常将模型拟合在训练集上,以便对未被训练的数据进行预测。
在统计学和机器学习领域中,我们通常把数据分成两个子集:训练数据和测试数据,并且把模型拟合到训练数据上,以便对测试数据进行预测。当做到这一点时,可能会发生两种情况:模型的过度拟合或欠拟合。我们不希望出现这两种情况,因为这会影响模型的可预测性。我们有可能会使用具有较低准确性或不常用的模型(这意味着你不能泛化对其它数据的预测)。
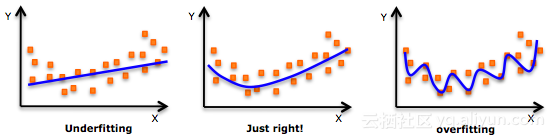
什么是模型的过度拟合(Overfitting)和欠拟合(Underfitting)?
过度拟合
过度拟合意味着模型训练得“太好”了,并且与训练数据集过于接近了。这通常发生在模型过于复杂的情况下,模型在训练数据上非常的准确,但对于未训练数据或者新数据可能会很不准确。因为这种模型不是泛化的,意味着你可以泛化结果,并且不能对其它数据进行任何推断,这大概就是你要做的。基本上,当发生这种情况时,模型学习或描述训练数据中的“噪声”,而不是数据中变量之间的实际关系。这种噪声显然不是任何新数据集的一部分,不能应用于它。
欠拟合
与过度拟合相反,当模型欠拟合的时候,它意味着模型不适合训练数据,因此会错过数据中的趋势特点。这也意味着该模型不能被泛化到新的数据上。你可能猜到了,这通常是模型非常简单的结果。例如,当我们将线性模型(如线性回归)拟合到非线性的数据时,也会发生这种情况。不言而喻,该模型对训练数据的预测能力差,并且还不能推广到其它的数据上。
实例
值得注意的是,欠拟合不像过度拟合那样普遍。然而,我们希望避免数据分析中的这两个问题。你可能会说,我们正在试图找到模型的欠拟合与过度拟合的中间点。像你所看到的,训练测试分割和交叉验证有助于避免过度拟合超过欠拟合。
训练测试分割
正如我之前所说的,我们使用的数据通常被分成训练数据和测试数据。训练集包含已知的输出,并且模型在该数据上学习,以便以后将其泛化到其它数据上。我们有测试数据集(或子集),为了测试模型在这个子集上的预测。

我们将使用Scikit-Learn library,特别是其中的训练测试分割方法。我们将从导入库开始:
快速地看一下导入的库:
· Pandas —将数据文件作为Pandas数据帧加载,并对数据进行分析;
· 在Sklearn中,我导入了数据集模块,因此可以加载一个样本数据集和linear_model,因此可以运行线性回归;
· 在Sklearn的子库model_selection中,我导入了train_test_split,因此可以把它分成训练集和测试集;
· 在Matplotlib中,我导入了pyplot来绘制数据图表;
好了,一切都准备就绪,让我们输入糖尿病数据集,将其转换成数据帧并定义列的名称:
现在我们可以使用train_test_split函数来进行分割。函数内的test_size=0.2表明了要测试的数据的百分比,通常是80/20或70/30左右。
# create training and testing vars
X_train, X_test, y_train, y_test = train_test_split(df, y, test_size=0.2)
print X_train.shape, y_train.shape
print X_test.shape, y_test.shape
(353, 10) (353,)
(89, 10) (89,)现在我们将在训练数据上拟合模型:
# fit a model
lm = linear_model.LinearRegression()
model = lm.fit(X_train, y_train)
predictions = lm.predict(X_test)正如所看到的那样,我们在训练数据上拟合模型并尝试预测测试数据。让我们看一看都预测了什么:
predictions[0:5]
array([ 205.68012533, 64.58785513, 175.12880278, 169.95993301,
128.92035866])注:因为我在预测之后使用了[0:5],它只显示了前五个预测值。去掉[0:5]的限制就会使它输出我们模型创建的所有预测值。
让我们来绘制模型:
## The line / model
plt.scatter(y_test, predictions)
plt.xlabel(“True Values”)
plt.ylabel(“Predictions”)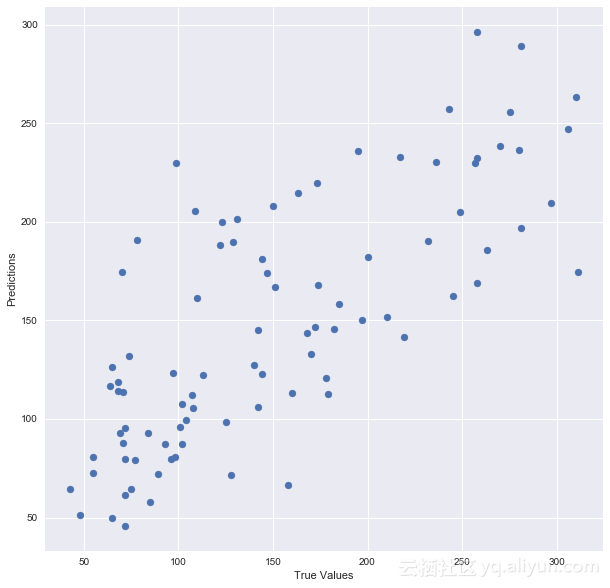
打印准确度得分:
print “Score:”, model.score(X_test, y_test)
Score: 0.485829586737总结:将数据分割成训练集和测试集,将回归模型拟合到训练数据,基于该数据做出预测,并在测试数据上测试预测结果。但是训练和测试的分离确实有其危险性,如果我们所做的分割不是随机的呢?如果我们数据的一个子集只包含来自某个州的人,或者具有一定收入水平但不包含其它收入水平的员工,或者只有妇女,或者只有某个年龄段的人,那该怎么办呢?这将导致过度拟合,即使我们试图避免,这就是交叉验证要派上用场了。
交叉验证
在前一段中,我提到了训练测试分割方法中的注意事项。为了避免这种情况,我们可以执行交叉验证。它非常类似于训练测试分割,但是被应用于更多的子集。意思是,我们将数据分割成k个子集,并训练第k-1个子集。我们要做的是,为测试保留最后一个子集。
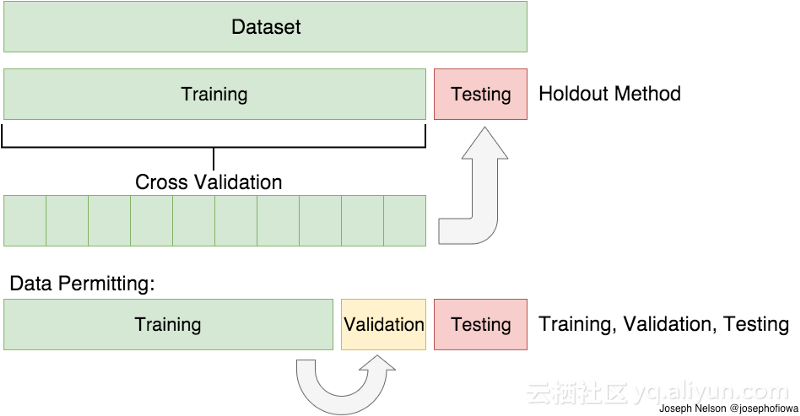
训练测试分割和交叉验证的可视化表示
有一组交叉验证方法,我来介绍其中的两个:第一个是K-Folds Cross Validation,第二个是Leave One Out Cross Validation (LOOCV)。
K-Folds 交叉验证
在K-Folds交叉验证中,我们将数据分割成k个不同的子集。我们使用第k-1个子集来训练数据,并留下最后一个子集作为测试数据。然后,我们对每个子集模型计算平均值,接下来结束模型。之后,我们对测试集进行测试。
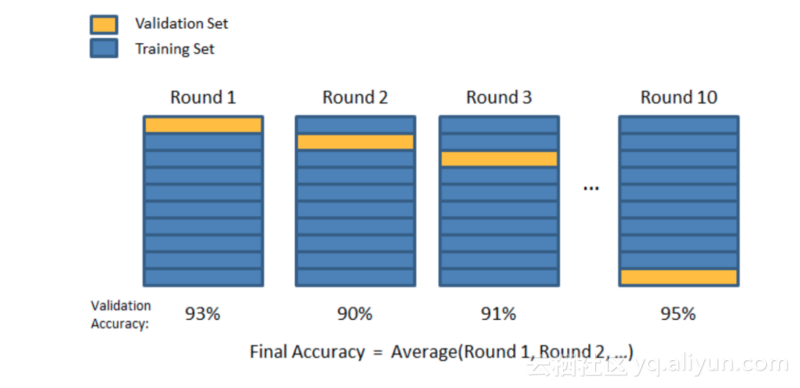
K-Folds的可视化表示
这里有一个在Sklearn documentation上非常简单的K-Folds例子:
fromsklearn.model_selection import KFold # import KFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]]) # create an array
y = np.array([1, 2, 3, 4]) # Create another array
kf = KFold(n_splits=2) # Define the split - into 2 folds
kf.get_n_splits(X) # returns the number of splitting iterations in the cross-validator
print(kf)
KFold(n_splits=2, random_state=None, shuffle=False)让我们看看结果:
fortrain_index, test_index in kf.split(X):
print(“TRAIN:”, train_index, “TEST:”, test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
('TRAIN:', array([2, 3]), 'TEST:', array([0, 1]))
('TRAIN:', array([0, 1]), 'TEST:', array([2, 3]))正如看到的,函数将原始数据拆分成不同的数据子集。这是个非常简单的例子,但我认为它把概念解释的相当好。
弃一法交叉验证(Leave One Out Cross Validation,LOOCV)
这是另一种交叉验证的方法,弃一法交叉验证。可以在Sklearn website上查看。在这种交叉验证中,子集的数量等于我们在数据集中观察到的数量。然后,我们计算所有子集的平均数,并利用平均值建立模型。然后,对最后一个子集测试模型。因为我们会得到大量的训练集(等于样本的数量),因此这种方法的计算成本也相当高,应该在小数据集上使用。如果数据集很大,最好使用其它的方法,比如kfold。
让我们看看Sklearn上的另一个例子:
fromsklearn.model_selectionimportLeaveOneOut
X = np.array([[1, 2], [3, 4]])
y = np.array([1, 2])
loo = LeaveOneOut()
loo.get_n_splits(X)
fortrain_index, test_indexinloo.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
print(X_train, X_test, y_train, y_test)以下是输出:
('TRAIN:', array([1]), 'TEST:', array([0]))
(array([[3, 4]]), array([[1, 2]]), array([2]), array([1]))
('TRAIN:', array([0]), 'TEST:', array([1]))
(array([[1, 2]]), array([[3, 4]]), array([1]), array([2]))那么,我们应该使用什么方法呢?使用多少子集呢?拥有的子集越多,我们将会由于偏差而减少误差,但会由于方差而增加误差;计算成本也会上升,显然,拥有的子集越多,计算所需的时间就越长,也将需要更多的内存。如果利用数量较少的子集,我们减少了由于方差而产生的误差,但是由于偏差引起的误差会更大。它的计算成本也更低。因此,在大数据集中,通常建议k=3。在更小的数据集中,正如我之前提到的,最好使用弃一法交叉验证。
让我们看看以前用过的一个例子,这次使用的是交叉验证。我将使用cross_val_predict函数来给每个在测试切片中的数据点返回预测值。
# Necessary imports:
from sklearn.cross_validation import cross_val_score, cross_val_predict
from sklearn import metrics之前,我给糖尿病数据集建立了训练测试分割,并拟合了一个模型。让我们看看在交叉验证之后的得分是多少:
# Perform 6-fold cross validation
scores = cross_val_score(model, df, y, cv=6)
print “Cross-validated scores:”, scores
Cross-validated scores: [ 0.4554861 0.46138572 0.40094084 0.55220736 0.43942775 0.56923406]正如你所看到的,最后一个子集将原始模型的得分从0.485提高到0.569。这并不是一个惊人的结果,但我们得到了想要的。
现在,在进行交叉验证之后,让我们绘制新的预测图:
# Make cross validated predictions
predictions = cross_val_predict(model, df, y, cv=6)
plt.scatter(y, predictions)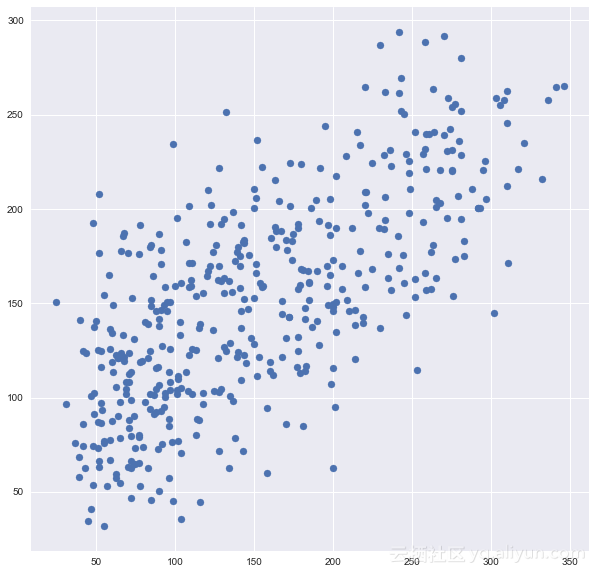
你可以看到这和原来的图有很大的不同,是原来图的点数的六倍,因为我用的cv=6。
最后,让我们检查模型的R²得分(R²是一个“表示与自变量分离的可预测的因变量中方差的比例的数量”)。可以看一下我们的模型有多准确:
accuracy = metrics.r2_score(y, predictions)
print “Cross-Predicted Accuracy:”, accuracy
Cross-Predicted Accuracy: 0.490806583864
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Train/Test Split and Cross Validation in Python》
作者:Adi Bronshtein
译者:奥特曼,审校:袁虎。
文章为简译,更为详细的内容,请查看原文
