线性回归可能是机器学习中最简单、最基础的算法了。但一定不要因为它简单就轻视它的存在,因为它也是很多更高级机器学习算法的基础,比如多项式回归、岭回归、 LASSO 回归等。线性回归的核心归结为求解正规方程(由样本特征x所得预测值y'和实际值y差的平方和,对x求偏导并使其为0所得的方程组),也就是利用最小二乘法求解方程系数。当x为一个n维向量时,方程的物理意义也被扩展为求解一个n维超平面前的系数。在介绍线性回归之前,让我们先了解下衡量线性回归预测结果好坏的指标。
1、相关评价标准
1)均方误差 MSE (Mean Squared Error) :
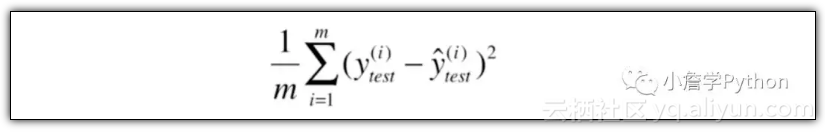
2)均方根误差 RMSE (Root Mean Squared Error) :

3)平均绝对误差 MAE (Mean Absolute Error) :
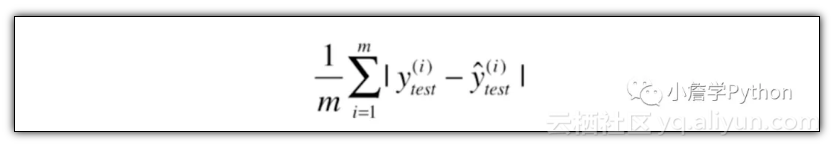
4)R方误差 ( R Squared ) :
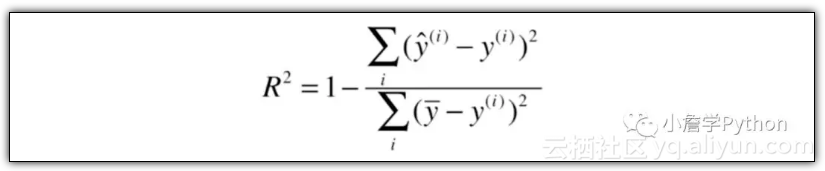
应根据不同的应用场景和需求来选择不同的评价指标,没有其中一个平白无故的比另一个更好。具体来说,RMSE就是MSE的平方根,但它的量纲与要预测的y值的量纲相同,更有意义,MAE 因为带有绝对值而不方便求导,而 R Squared 因为无量化而更具有通用的比较性。我们可以通过向量化计算在 Python 中很容易的实现这4中指标的计算。同时,你也可以直接在 scikit-learn 中的 metrics 中直接调用 mean_squared_error,mean_absolute_error,r2_score 方法直接计算得到 MSE、MAE、R Squared。
2、线性回归
1)小引—— kNN 回归
首先我们先回顾下上次的 kNN ,其实 kNN 不仅可以用于分类,还可以用来解决回归问题。以此来引入回归问题的鼻祖——线性回归。
Talk is cheap, let's see the code!
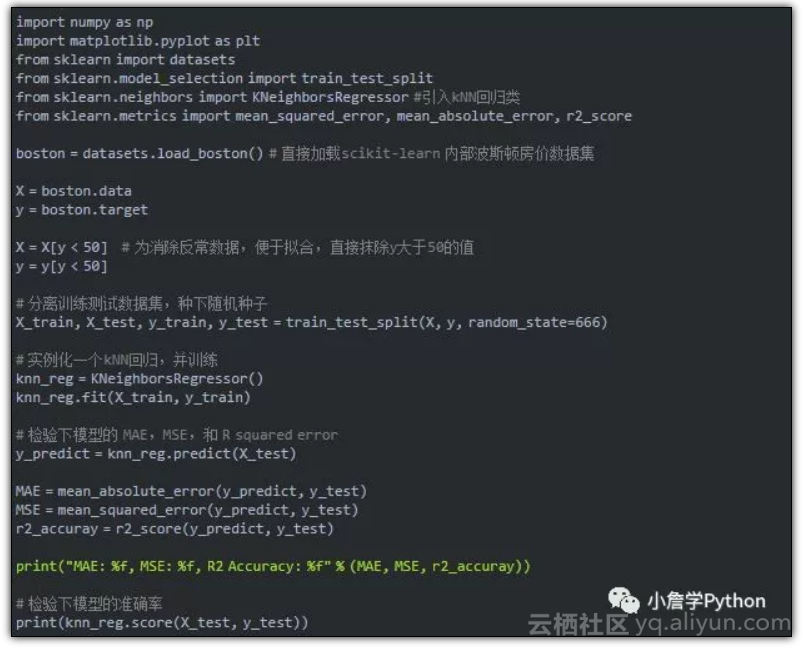
结果如下:
MAE: 3.651057, MSE: 25.966010, R2 Accuracy: 0.4644840.602674505081
准确率并不是太高呢!比我抛硬币好不了多少,是不是因为我们使用的是 kNN 回归默认的模型,而没有调整任何超参数的原因的。那我们接下来先介绍下 kNN 回归的各个超参数,再用网格搜索的方式搜索 kNN 回归的最佳超参数。
● n_neighbors ——即 k 值,默认n_neighbors=5;weights:表示是否为距离加权重,默认 weights=’uniform’;● algorithm —— 用于计算距离的算法,默认algorithm=’auto’,即根据 fit 方法传入值选择合适算法;
● p ——明可夫斯基距离的指数,默认p=2(欧氏距离),p=1 为曼哈顿距离;
● n_jobs ——调用CPU的核心数,默认 n_jobs=None;
上次我们学习kNN分类器的时候,用到了2层 for 循环搜索最佳超参数,这次我们直接调用 scikit-learn 中的方法搜索 kNN 回归的最佳超参数。实现如下:
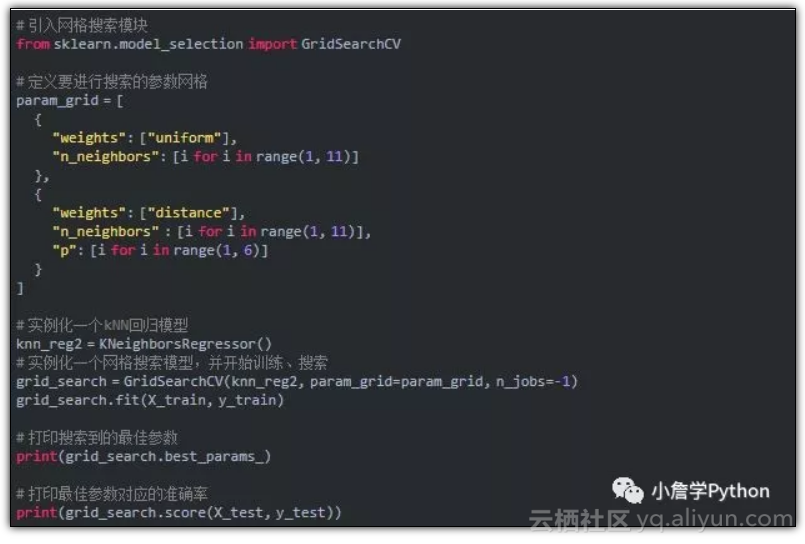
结果如下:
{'n_neighbors': 6, 'p': 1, 'weights': 'distance'}0.735424490609
好像准确度还不是很高呢!?是不是 kNN 这个算法太简单,已经落伍了呢?
其实,我们在选择一种机器学习方法的时候是受领域限制的,不同的领域,不同种类的数据可能就适合不同的机器学习方法,没有一种机器学习方法面对各种问题而无往不利,总是得到最佳结果(暂且不谈深度学习),而且模型准确率的高低还受到数据质量的影响。那么我接下来看看线性回归在波斯顿房价数据集上表现怎样。
2)Linear Regression
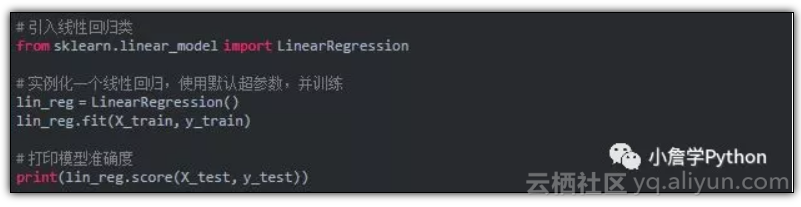
结果为 0.800891619952 。
80% 好像还不错,毕竟是默认模型嘛。让我们看下线性回归都有哪些超参数呢!
● fit_intercept ——默认 fit_intercept=True,决定是否计算模型截距;● normalize ——默认 normalize=False,如果fit_intercept=True,X 会在被减去均值并除以 L2 正则项之前正则化;
● n_jobs——计算时所使用的CPU核心数;

结果为:
array([ -1.14235739e-01, 3.12783163e-02, -4.30926281e-02,-9.16425531e-02, -1.09940036e+01, 3.49155727e+00,-1.40778005e-02, -1.06270960e+00, 2.45307516e-01,-1.23179738e-02, -8.80618320e-01, 8.43243544e-03,-3.99667727e-01])
线性回归的特征系数是具有实际意义的,系数为负说明 y 值与该特征负相关,系数为正说明该特征与 y 值正相关,且值越大,相关度越高。我们拿波斯顿房价数据集举例说明,通过查找官方文档,我们得到这13个特征(按顺序排列)的实际意义:
Attribute Information (in order)
● CRIM——per capita crime rate by town● ZN——proportion of residential land zoned for lots over 25,000 sq.ft.
● INDUS——proportion of non-retail business acres per town
● CHAS——Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
● NOX——nitric oxides concentration (parts per 10 million)
● RM——average number of rooms per dwelling
● AGE——proportion of owner-occupied units built prior to 1940
● DIS——weighted distances to five Boston employment centres
● RAD——index of accessibility to radial highways
● TAX——full-value property-tax rate per $10,000
● PTRATIO——pupil-teacher ratio by town
● B——1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
● LSTAT——% lower status of the population
● MEDV——Median value of owner-occupied homes in $1000's
为方便对应,我们将这13个特征的名字按其系数大小排下序:
![]()
结果为
array(['NOX', 'DIS', 'PTRATIO', 'LSTAT', 'CRIM', 'CHAS', 'INDUS', 'AGE','TAX', 'B', 'ZN', 'RAD', 'RM'],
由此可知特征 'NOX' 与房价的负相关度最高,查看官方文档说明可知,其代表———房子附近的氮氧化物的浓度,我们根据常识就知道,氮氧化物有毒,房子附近氮氧化物浓度高的,价钱肯定便宜。特征 'RM' 代表房子的平均房间数,同样的,根据我们的生活经验,房间数越多的房子一般也越贵,大家想想是不是。
今天的分享就到这里了,关于 Linear Regression 还有很多超参数的调整,请小伙伴们自己在下面亲手操作下,会收获更多哦。还是那句话,如果你们中有大神路过,还请高抬贵脚,勿踩勿喷,嘻嘻。期待与小伙伴们共同进步!
原文发布时间为:2018-11-22
本文作者:蜉蝣扶幽

