先摆结论:
1. 论文提供了一种分析和构造概率散度的直接思路,从而简化了构建新 GAN 框架的过程;
2. 推导出了一个称为 GAN-QP 的 GAN 框架,这个 GAN 不需要像 WGAN 那样的 L 约束,又不会有 SGAN 的梯度消失问题,实验表明它至少有不逊色于、甚至优于 WGAN 的表现。

▲ GAN-QP效果图
论文的实验最大做到了 512 x 512 的人脸生成(CelebA HQ),充分表明了模型的有效性(效果不算完美,但是模型特别简单)。有兴趣的朋友,欢迎继续阅读下去。
直面对偶空间
我们现在要构建一个 GAN 框架,一般包含三个步骤:
● 寻求一种良好的概率散度;● 找出它的对偶形式;
● 转化为极小-极大游戏(min-max game)。
问题是:真正对训练过程有用的是第二、第三步,第一步并不是那么必要。
事实上,从原空间要定义一个新的散度很难,定义了之后也不一定容易转化为对偶形式。然而,我们可以直接在对偶空间分析,由此可以发现一批新的、形态良好的散度。换言之,我们其实可以直接在对偶空间中论述一个式子是否满足散度的定义,从而直接给出可优化的目标,而不需要关心它具体是 JS 散度还是 W 距离了。
下面我们来举例说明这个思路。
散度
首先我们来给出散度的定义:
如果 D[p,q] 是关于 p,q 的标量函数,并且满足:
● D[p,q]≥0 恒成立;● D[p,q]=0⇔p=q。
那么称 D[p,q] 为 p,q 的一个散度,散度与“距离”的主要差别是散度不用满足三角不等式,也不用满足对称性。但是散度已经保留了度量差距的最基本的性质,所以我们可以用它来度量 p,q 之间的差异程度。
SGAN
基本定义
我们先来看 SGAN 中的判别器 loss,定义:
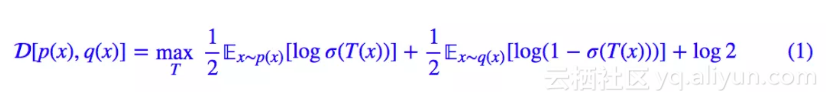
这其实就是 JS 散度的对偶形式。但是我们可以直接基于这个定义来证明它是一个散度,然后讨论这个散度本身的性质,而根本不需要知道它是 JS 散度。
怎么证明?只需要证明这个结果满足刚才说的散度的两点要求。注意,按照我们的逻辑,我们不知道它是 JS 散度,但我们可以从数学角度证明它是一个散度。
其实如果读者真的明白了式 (1) 的含义,证明就不困难了。式 (1) 先定义了一个期望的式子,然后对 T 取最大(用更准确的说法是求“上确界”),取最大的结果才是散度。再强调一遍,“取最大之后的结果才是散度”,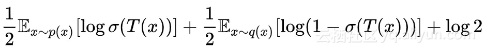 这个式子并不是散度。
这个式子并不是散度。
具体的证明过程略微冗长,就不完整摆出来了,请读者自行去看原文的附录。或者看下面的 WGAN 的部分,因为 WGAN 的部分相对简单。
对抗网络
假如有了散度之后,我们就可以通过缩小两个概率分布的散度,来训练生成模型了。也就是说接下来要做的事情应该是:

注意 D[p(x),q(x)] 是通过 maxT 操作实现的,所以组合起来就是一个 min-max 的过程,比如前面的例子,等价地就是:
![]()
这就是 SGAN。
所以我们发现,GAN 的过程其实就两步:1)通过 max 定义一个散度;2)通过 min 缩小两个分布的散度。这里的新观点,就是将 max 直接作为散度的定义的一部分。
性能分析
我们知道 SGAN 可能有梯度消失的风险,这是为什么呢?我们考察一个极端情形:
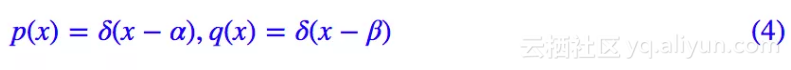
其中 α≠β。这样一来,两个分布分别只是单点分布,完全没有交集。这种情况下代入 (1),结果就是:
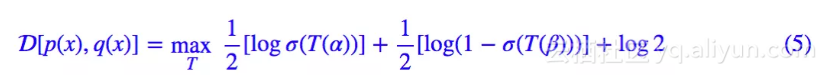
注意我们对 T 没有任何约束,所以为了取最大,我们可以让 T(α)→+∞,T(β)→−∞,从而得到上确界是一个常数 log2。即这种情况下 D[p(x),q(x)]=log2。
这就是说,对于两个几乎没有交集的分布,式 (1) 定义的散度给出的度量结果是常数 log2,常数就意味着梯度是 0,无法优化。而 WGAN 的那两篇文章则表明,“没有交集”理论上在 GAN 中是很常见的,所以这是 SGAN 的固有毛病。
一般的f散度
上面的几个小节已经完整了呈现了这种理解的流程:
1. 我们通过 max 定义一个数学式子,然后可以从数学角度直接证明这是一个散度,而不用关心它叫什么名字;
2. 通过 min 最小化这个散度,组合起来就是一个 min-max 的过程,就得到了一种 GAN;
3. 为了检查这种散度在极端情况下的表现,我们可以用 p(x)=δ(x−α),q(x)=δ(x−β) 去测试它。
上述关于 SGAN 的论述过程,可以平行地推广到所有的 f-GAN 中(参考《f-GAN简介:GAN模型的生产车间》[1]),各种 f 散度其实没有本质上的差异,它们有同样的固有毛病(要不就梯度消失,要不就梯度爆炸)。
WGAN
基本定义
现在我们转向一类新的散度:Wasserstein 距离。注意 Wasserstein 距离是一个严格的、满足公理化定义的距离,不过我们这里只关心它的散度性质。定义:
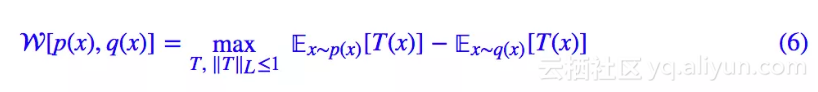
这里:

而 d(x,y) 是任意一种现成的距离。
可以直接证明它是一个散度。这个证明还算经典,所以将它写在这里:
1. 不管是什么 p(x),q(x),只要让 T(x)≡0,我们就得到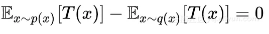 ,因为散度的定义是要遍历所有的 T 取最大的,所以它至少不会小于 0,这就证明了第一点非负性;
,因为散度的定义是要遍历所有的 T 取最大的,所以它至少不会小于 0,这就证明了第一点非负性;
2. 证明 p(x)=q(x) 时,W[p(x),q(x)]=0,也就是 W[p(x),p(x)]=0,这几乎是显然成立的了;
3. 证明 p(x)≠q(x) 时(严格来讲是它们不等的测度大于 0),W[p(x),q(x)]>0。这个相对难一点,但其实也很简单,只需要令 T0(x)=sign(p(x)−q(x)),那么显然有:
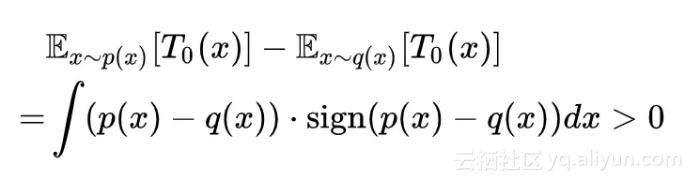
这样我们就直接地证明了 W[p(x),q(x)] 是满足散度的定义的。
对抗网络
同样地,有了新散度,就可以定义新 GAN 了:
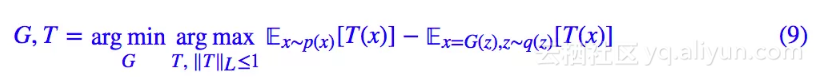
这就是 WGAN,相应的参考资料有互怼的艺术:从零直达WGAN-GP、WGAN-div:一个默默无闻的WGAN填坑者。
性能分析
同样地,用 p(x)=δ(x−α),q(x)=δ(x−β) 去测试 W[p(x),q(x)] 散度的性能,我们得到:
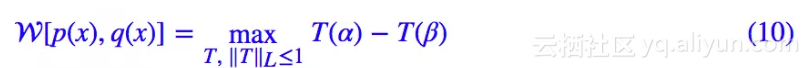
注意我们有 L 约束 ‖T‖L≤1,这意味着 |T(α)−T(β)|≤d(α,β),等号可以取到,所以:

结果不是常数,所以即使在这种极端情况下我们可以也拉近两个分布的距离。所以从这一点看,WGAN 要比 SGAN 要好。
L约束
WGAN 的遗留问题就是如何往判别器加入 L 约束,目前有三种方案:参数裁剪、梯度惩罚、谱归一化,请参考深度学习中的Lipschitz约束:泛化与生成模型和WGAN-div:一个默默无闻的WGAN填坑者。
参数裁剪基本已经被弃用了。梯度惩罚原则上只是一个经验方法,有它的不合理之处,而且要算梯度通常很慢。谱归一化看起来最优雅,目前效果也挺好,不过也有限制的太死的可能性。进一步讨论请看WGAN-div:一个默默无闻的WGAN填坑者。
新散度,新GAN
现在的结论是:SGAN 可能有梯度消失的风险,WGAN 虽然很好,但需要额外的 L 约束。那么很自然就会问:有没有不需要 L 约束,又不会梯度消失的 GAN?鱼与熊掌能否兼得?
还真的可以,下面带你找一个。不对,其实不止一个,带你找一批都行。
平方势散度
基本定义
下面要给出的散度,形式是这样的:
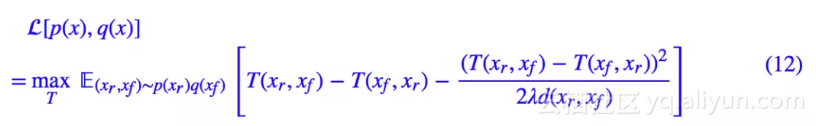
其中 λ>0 是一个超参数,d 可以是任意距离。
这个形式好像就在 WGAN 的基础上加了一个平方形式的势能,所以称为平方势散度(QP-div,quadratic potential divergence)。
论文的附录已经证明了式 (12) 确实是一个散度。
性能分析
用 p(x)=δ(x−α),q(x)=δ(x−β) 去测试这个散度,结果是:
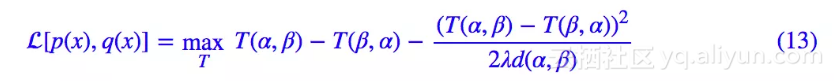
设 z=T(α,β)−T(β,α) 就得到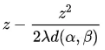 ,很熟悉有没有?这只是个二次函数的最大值问题呀,最大值是
,很熟悉有没有?这只是个二次函数的最大值问题呀,最大值是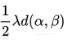 呀,所以我们就有:
呀,所以我们就有:

这不就跟 WGAN 差不多了嘛,哪怕对于极端分布,也不会有梯度消失的风险。鱼与熊掌真的可以兼得。
GAN-QP
对抗网络
有了散度就可以构建对抗网络,我们最终给出的形式为:
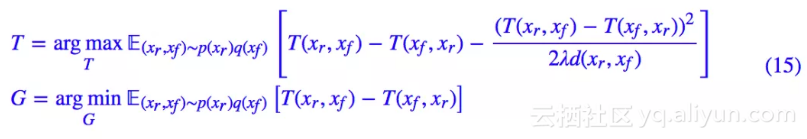
我在论文中称之为 GAN-QP。
注意不要把二次项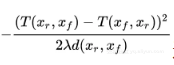 这一项加入到生成器的 loss 中(理论上不成问题,但是用梯度下降优化时会有问题。),因为这一项的分母是 d(xr,xf),一旦最小化二次项,等价于最小化 d(xr,xf),也就是用 d(xr,xf) 来度量图片的差距,这是不科学的。
这一项加入到生成器的 loss 中(理论上不成问题,但是用梯度下降优化时会有问题。),因为这一项的分母是 d(xr,xf),一旦最小化二次项,等价于最小化 d(xr,xf),也就是用 d(xr,xf) 来度量图片的差距,这是不科学的。
解的分析
通过变分法可以证明(还是在附录),判别器的最优解是:
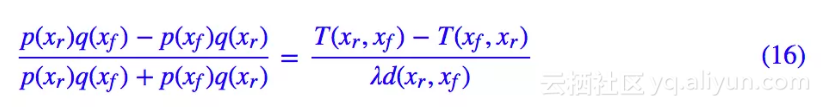
由这个最优解,我们可以得到两点结论。首先,不难证明最优解满足:
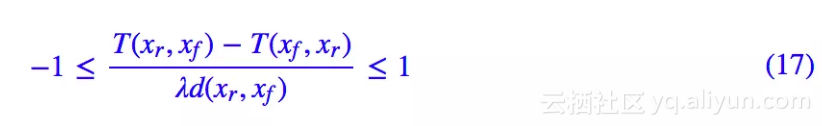
也就是说最优解自动满足 L 约束。所以我们可以认为 GAN-QP 是一种自适应 L 约束的方案。
其次,将最优解代入生成器的 loss,那么得到判别器的目标是:
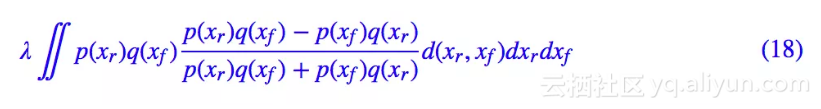
这也是一个概率散度,并且我们也从理论上证明了它不会梯度消失/爆炸(跟柯西不等式有关)。此外,还可以看到 λ 只是一个缩放因子,事实上并不重要,从而这个 GAN-QP 对 λ 是鲁棒的,λ 不会明显影响模型的效果。
实验结果
论文在 CelebA HQ 数据集上,比较了多种 GAN 与 GAN-QP 的效果,表明 GAN-QP 能媲美甚至超越当前最优的模型。
注意,模型 (15) 中,T 是 (xr,xf) 的二元函数,但实验表明,取最简单的一元特例 T(xr,xf)≡T(xr) 即可,即 T(xr,xf)−T(xf,xr) 用 T(xr)−T(xf) 就够了,改成二元函数并没有明显提升(但也可能是我没调好)。这样的话,形式上就跟 WGAN-GP 非常相似了,但理论更完备。
代码开源:
https://github.com/bojone/gan-qp
128 x 128
在 128 x 128 分辨率上,我们进行了较为全面的比较,定量指标是 FID。结果如下图:
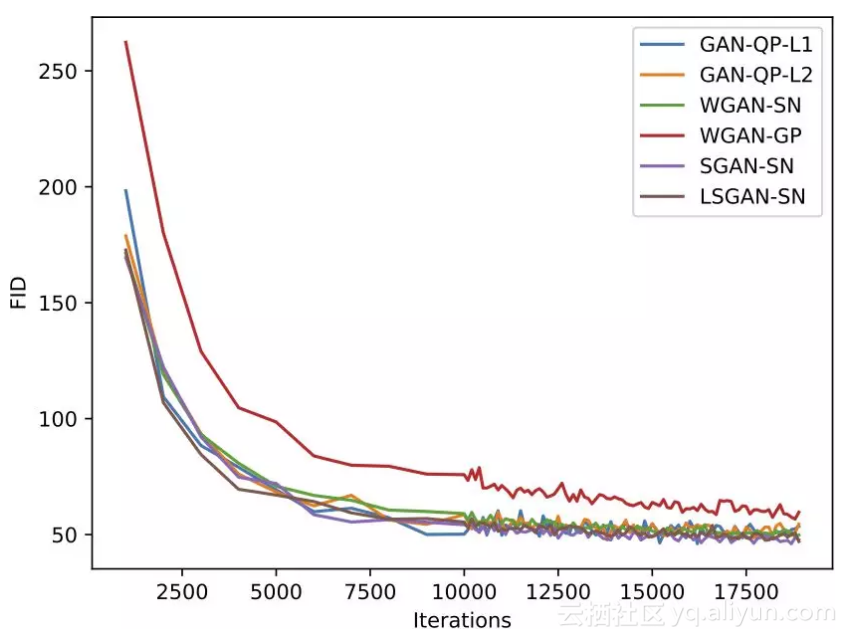
▲ 不同GAN的FID定量曲线
以及下表:

256 与 512
在 128 分辨率上,最好的表现是 GAN-QP 和 SGAN-SN,不过在 256 x 256 分辨率上,它们的表现就拉开了差距:

我最大把 GAN-QP 的实验做到了 512 x 512 的人脸生成,效果还是不错的,最终的 FID 是 26.44:

▲ 512 x 512人脸效果图
论文综述
这篇文章源于我对概率散度的思考,企图得到一种更直接的理解概率散度的方案,其中还受启发于 WGAN-div。
幸好,最后把这条路走通了,还得到了一些新结果,遂提交到 Github 中,供各位参考,希望得到各位前辈高手的指点。事实上,基于类似的思路,我们可以构造很多类似的散度,比如将平方换成 4 次、6 次方等,只不过理论分析起来就会困难一些了。
限于算力,加之我不是专门研究 GAN 的,所以实验方面可能做得不够完善,基本能论证结论即可,请大家体谅,当然也欢迎各位的指导。