背景
1. 想看电影。2. 需要有免费的电影资源。
只要我们有了免费的电影资源后,就可以愉快的看电影了,或者把免费电影链接发给某个姑娘,嘿嘿嘿!
如何获取电影资源
国内的视频网站有:腾讯视频、爱奇艺、优酷等等,今天就看爱奇艺上的电影好了。
● 电影资源这些数据都在 html 页面上,所以先撸一个通过请求 url 获取 html 页面的方法。
ps:也可以使用现成的库 比如 Axios。
fetch.js
const http = require('http');
const https = require('https');
const urlMd = require('url');
module.exports = function (url, callback){ let urlInfo = urlMd.parse(url); let fetcher = urlInfo.protocol === 'http:' ? http : https; let req = fetcher.request({
hostname: urlInfo.hostname,
path: urlInfo.path,
}, (res) => {
console.log(`状态码: ${res.statusCode}`); if (res.statusCode === 200) { let content = [];
res.on('data', (chunk) => {
content.push(chunk);
})
res.on('end', () => { let b = Buffer.concat(content);
callback && callback(null,b.toString());
})
} else {
callback(new Error(`状态码:${res.statusCode}`));
}
})
req.end();
req.on('error', (err) => {
callback(err);
})
}复制代码● 注意:因为后面要用 util.promisify 来包裹此函数,所以 callback 需要符合 nodejs 规定,第一个参数必须为 err。
1. 通过 util.parse 解析出使用 http 还是 https
3. 通过 req.end 发送
4. 请求成功后,判断状态码 200 为成功,否则为失败( 304 也可能是成功,这里没有扩展)
● 寻找电影所在的地址
发现这个页面满足了我们的需要,接下来获取到电影所在的 html 即可。

当前的url: http://list.iqiyi.com/www/1/-------------11-1-1-iqiyi--.html
当点击下一页的时候发现 url 变成了:http://list.iqiyi.com/www/1/-------------11-2-1-iqiyi--.html
对比发现 url 只改变了一个数字,那么是不是它可以控制页码呢?,验证后果然如此。
index.js
function getSourceURL(index) { return `http://list.iqiyi.com/www/1/-------------11-${index}-1-iqiyi--.html`
}复制代码2. 返回url
3. 打开爱奇艺
4. 点击电影频道
5. 点击全部
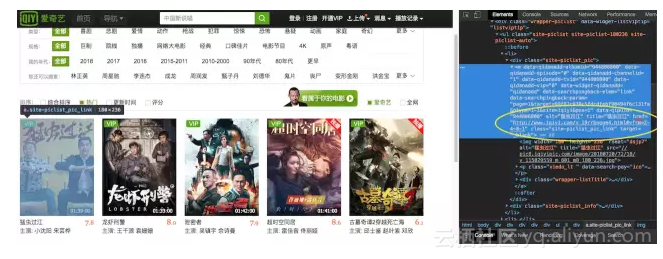
● 解析 html 获取电影数据
知道了电影所在的 url,也有了通过 url 获取 html 页面数据的方法,那么接下来就是要解析出 html 内的电影数据咯。(fetch 拉取到的 html 页面数据都是字符串形式)
index.js
const jsdom = require('jsdom');
const { JSDOM } = jsdom;
function parseHTML(html) {
const dom = new JSDOM(html); let aList = dom.window.document.querySelectorAll('div.site-piclist_pic > a');
aList = Array.from(aList); return aList.map((a) => { return { source: a.href,
title: a.title,
url: `${config.parseURL}${a.href}`
}
});
}复制代码config.json
"parseURL":"http://vip.jlsprh.com/index.php?url="复制代码2. 获取所有的电影标签
3. 返回需要的数据
config.parseURL 为解析视频的接口地址(通过电影url 可以免费播放,无需会员)
万里长征 还差一点
接下来通过并发(加快请求速度)来请求电影页面,解析并保存到本地。
config.json
{ "pageMaxNum":"20", "parseURL":"http://vip.jlsprh.com/index.php?url="
}复制代码index.js
const util = require('util');
const fetch = util.promisify(require('./fetch.js'));
const jsdom = require('jsdom');
const { JSDOM } = jsdom;
const fs = require('fs');
const config = require('./config.json');
(function () {
Promise.all(fetchHandler())
.then(d => parseHTML(d))
.then(d => saveToFile(d));
})()
function fetchHandler(){ let promiseList = []; for (let i = 1; i <= config.pageMaxNum; i++) {
promiseList.push(fetch(getSourceURL(i)));
} return promiseList;
}
function getSourceURL(index) { return `http://list.iqiyi.com/www/1/-------------11-${index}-1-iqiyi--.html`
}
function parseHTML(html) {
const dom = new JSDOM(html); let aList = dom.window.document.querySelectorAll('div.site-piclist_pic > a');
aList = Array.from(aList); return aList.map((a) => { return { source: a.href,
title: a.title,
url: `${config.parseURL}${a.href}`
}
});
}
function saveToFile(data) { let str = JSON.stringify(data);
fs.writeFile('./data.json', str, { flag: 'w+' }, (err) => { if (err) console.log(err);
})
}复制代码2. 利用 util.promisify 使 fetch 返回 promise
3. 利用 Promise.all 全部请求完成后在处理
4. 解析 html 取出所需数据
5. 保存到本地
结束语
全部撸完后,你会得到一个 data.json 文件(别忘记执行 node index),里面包含免费播放的链接地址。后续的话可以在撸一个前台页面,基于这些数据可以制作一个小电影网站了~
至此,一个小小的爬虫就学会了。是不是感觉很有成就感呢,只学习干巴巴的 API 的话可是相当枯燥,把这些知识转化为一个小项目,可以提高自己的动力和兴趣,把结果分享给朋友的话还能提高自己的成就感,何乐而不为呢。
原文发布时间为:2018-11-20
本文作者:春去春又来