温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
1.概述
在CDH的默认安装包中,是不包含Kafka,Kudu和Spark2的,需要单独下载特定的Parcel包才能安装相应服务。本文档主要描述在离线环境下,在CentOS6.5操作系统上基于CDH5.12.1集群,使用Cloudera Manager通过Parcel包方式安装Kudu、Spark2和Kafka的过程。
-
内容概括
- Kudu安装
- Spark2安装
- Kafka安装
- 服务验证
-
测试环境
- 操作系统版本:CentOS6.5
- CM和CDH版本5.12.1
- 使用CM管理员admin用户
- 操作系统采用root用户操作
-
前置条件
- CDH集群运行正常
2.Kudu安装
CDH5.12.1打包集成Kudu1.4,并且Cloudera提供官方支持。不再需要安装Kudu的csd文件,安装完Kudu,Impala即可直接操作Kudu。
以下安装步骤描述如何使用Cloudera Manager来安装和部署Kudu1.4
2.1Kudu的Parcel部署
1.从Cloudera官网下载Kudu的Parcel包,下载地址如下
http://archive.cloudera.com/kudu/parcels/5.12.1/KUDU-1.4.0-1.cdh5.12.1.p0.10-el6.parcel
http://archive.cloudera.com/kudu/parcels/5.12.1/KUDU-1.4.0-1.cdh5.12.1.p0.10-el6.parcel.sha1
http://archive.cloudera.com/kudu/parcels/5.12.1/manifest.json2.将以上3个文件下载到http服务所在服务器的/var/www/html/kudu1.4目录
[root@ip-172-31-6-148~]# cd /var/www/html/
[root@ip-172-31-6-148 html]# mkdir kudu1.4
[root@ip-172-31-6-148 html]# cd kudu1.4/
[root@ip-172-31-6-148 kudu1.4]# ll
total 474140
-rw-r--r-- 1 rootroot 485506175 Aug 30 14:55 KUDU-1.4.0-1.cdh5.12.1.p0.10-el6.parcel
-rw-r--r-- 1 rootroot 41 Aug 30 14:55KUDU-1.4.0-1.cdh5.12.1.p0.10-el6.parcel.sha1
-rw-r--r-- 1 rootroot 2646 Aug 30 14:55 manifest.json
[root@ip-172-31-6-148 kudu1.4]# 
3.验证http是否能够正常访问

2.2安装Kudu服务
1.通过CM界面配置Kudu的Parcel地址,并下载,分发,激活Kudu。



已分配激活

2.回到CM主页,添加Kudu服务

选择Kudu服务,点击“继续”

选择Master和Tablet Server,点击“继续”

配置相应的目录,注:无论是Master还是Tablet根据实际情况,数据目录(fs_data_dir)应该都可能有多个,以提高并发读写,从而提高Kudu性能。

启动Kudu服务

安装完毕

2.3配置Impala
从CDH5.10开始,安装完Kudu后,默认Impala即可直接操作Kudu进行SQL操作,但为了省去每次建表都需要在TBLPROPERTIES中添加kudu_master_addresses属性,建议在Impala的高级配置项中设置KuduMaster的地址和端口:--kudu_master_hosts=ip-172-31-6-148.fayson.com:7051

多个master可以以“,”分割如:
--kudu_master_hosts=ip-172-31-6-148.fayson.com:7051,ip-172-31-6-148.fayson.com:7051
3.Spark2安装
集群的jdk版本为jdk1.7.0_67,从Spark2.2.0版本后不再支持Java7、Python2.6和Hadoop2.6.5之前的版本,所以此处选择Spark 2.1.0版本部署。
3.1安装csd文件
1.下载csd文件,下载地址如下:
http://archive.cloudera.com/spark2/csd/SPARK2_ON_YARN-2.1.0.cloudera1.jar2.将csd文件移动至/opt/cloudera/csd目录下
[root@ip-172-31-6-148csd]# pwd
/opt/cloudera/csd
[root@ip-172-31-6-148 csd]#ll
total 16
-rw-r--r-- 1 rootroot 16109 Mar 29 06:58 SPARK2_ON_YARN-2.1.0.cloudera1.jar
[root@ip-172-31-6-148 csd]# 
如果csd目录不存在,则创建
[root@ip-172-31-6-148cloudera]# mkdir csd
[root@ip-172-31-6-148 cloudera]# chown cloudera-scm:cloudera-scm csd/3.重启Cloudera Manager服务
[root@ip-172-31-6-148~]# service cloudera-scm-serverrestart
Stopping cloudera-scm-server: [ OK ]
Starting cloudera-scm-server: [ OK ]
[root@ip-172-31-6-148 ~]# 
3.2Spark2的Parcel部署
1.下载Spark2的Parcel包,下载地址如下
http://archive.cloudera.com/spark2/parcels/2.1.0/SPARK2-2.1.0.cloudera1-1.cdh5.7.0.p0.120904-el6.parcel
http://archive.cloudera.com/spark2/parcels/2.1.0/SPARK2-2.1.0.cloudera1-1.cdh5.7.0.p0.120904-el6.parcel.sha1
http://archive.cloudera.com/spark2/parcels/2.1.0/manifest.json2.将上述3个文件下载至/var/www/html/spark2.1.0目录下
[root@ip-172-31-6-148html]# cd /var/www/html/
[root@ip-172-31-6-148 html]# mkdir spark2.1.0
[root@ip-172-31-6-148 html]# cd spark2.1.0/
[root@ip-172-31-6-148 spark2.1.0]# ll
total 173052
-rw-r--r-- 1 rootroot 4677 Mar 29 06:58 manifest.json
-rw-r--r-- 1 rootroot 177185276 Mar 29 06:58 SPARK2-2.1.0.cloudera1-1.cdh5.7.0.p0.120904-el6.parcel
-rw-r--r-- 1 rootroot 41 Mar 29 06:58SPARK2-2.1.0.cloudera1-1.cdh5.7.0.p0.120904-el6.parcel.sha1
[root@ip-172-31-6-148 spark2.1.0]# 
3.验证是否部署成功

3.3安装Spark2
1.通过CM管理界面配置Spark2的Parcel地址并保存


2.点击下载、分配并激活

3.回到CM主页,添加Spark2

4.选择Spark2,点击“继续”

5.为新的Spark2选择一组依赖,点击“继续”

6.选择History Server和Gateway节点,点击“继续”

7.启动Spark2服务,服务启动完成后,点击“继续”

8.Spark2安装完成

4.Kafka安装
4.1Kafka版本选择
| Kafka版本 | 版本特性 | 最低支持CM版本 | 支持CDH版本 | 是否集成到CDH |
|---|---|---|---|---|
| 2.2.x | | Cloudera Manager 5.9.x | CDH 5.9.x and higher | 否 |
| 2.1.x | Sentry authorization | Cloudera Manager 5.9.x | CDH 5.9.x and higher | 否 |
| 2.0.x | Enhanced security | Cloudera Manager 5.5.3 | CDH 5.4.x and higher | 否 |
| 1.4.x | Distributed both as package and parcel | Cloudera Manager 5.2.x | CDH 5.4.x, 5.5.x, 5.6.x | 否 |
| 1.3.x | Includes Kafka Monitoring | Cloudera Manager 5.2.x | CDH 5.4.x, 5.5.x, 5.6.x | 否 |
| 1.2.x | | Cloudera Manager 5.2.x | CDH 5.4.x, 5.5.x, 5.6.x | 否 |
4.2Kafka的Parcel部署
1.从Cloudera官网下载Kafka的Parcel包,下载地址如下
http://archive.cloudera.com/kafka/parcels/2.1.1.18/KAFKA-2.1.1-1.2.1.1.p0.18-el6.parcel
http://archive.cloudera.com/kafka/parcels/2.1.1.18/KAFKA-2.1.1-1.2.1.1.p0.18-el6.parcel.sha1
http://archive.cloudera.com/kafka/parcels/2.1.1.18/manifest.json2.将上述3个文件下载至/var/www/html/kafka2.1.1.18目录下
[root@ip-172-31-6-148html]# cd /var/www/html/
[root@ip-172-31-6-148 html]# mkdir kafka2.1.1.18
[root@ip-172-31-6-148 html]# cd kafka2.1.1.18/
[root@ip-172-31-6-148 kafka2.1.1.18]# ll
total 66536
-rw-r--r-- 1 rootroot 68116503 Mar 27 17:39 KAFKA-2.1.1-1.2.1.1.p0.18-el6.parcel
-rw-r--r-- 1 rootroot 41 Mar 27 17:39KAFKA-2.1.1-1.2.1.1.p0.18-el6.parcel.sha1
-rw-r--r-- 1 rootroot 5252 Mar 27 17:40 manifest.json
[root@ip-172-31-6-148 kafka2.1.1.18]# 
3.验证是否部署成功

4.3安装Kafka服务
1.通过CM配置Kafka的Parcel包地址并保存


2.点击下载、分配并激活

3.回到CM主页,添加Kafka服务

4.选择Kafka服务,点击“继续”

5.为Kafka选择一组依赖关系,点击“继续”

6.选择Kafka Broker和Gateway,点击“继续”

7.根据集群环境修改Kafka配置,点击“继续”

8.Kafka安装完成

9.修改Kafka Broker的heap大小,默认为50M,可能会导致Kafka启动失败

保存配置,重新部署客户端并重启相应服务。
5.服务验证
5.1Kudu验证
建表语句如下:
CREATE TABLE my_first_table(
id BIGINT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU;通过Impala-shell创建Kudu表
[impala@ip-172-31-6-148root]$ impala-shell -iip-172-31-10-118.fayson.com
...
[ip-172-31-10-118.fayson.com:21000] > show tables;
Query: show tables
+------------+
| name |
+------------+
| test |
| test_table |
+------------+
Fetched 2 row(s) in 0.06s
[ip-172-31-10-118.fayson.com:21000] > CREATE TABLEmy_first_table(
> id BIGINT,
> name STRING,
> PRIMARY KEY(id)
> )
>PARTITION BY HASH PARTITIONS 16
> STORED AS KUDU;
Query: create TABLE my_first_table(
id BIGINT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU
Fetched 0 row(s) in 2.43s
[ip-172-31-10-118.fayson.com:21000] >
插入数据并查询
[ip-172-31-10-118.fayson.com:21000]> insert into my_first_table values(1,'fayson');
Query: insert into my_first_table values(1,'fayson')
...
Modified 1 row(s), 0 row error(s) in 3.92s
[ip-172-31-10-118.fayson.com:21000] >select * from my_first_table;
...
+----+--------+
| id | name |
+----+--------+
| 1 | fayson |
+----+--------+
Fetched 1 row(s) in 1.02s
[ip-172-31-10-118.fayson.com:21000] > 
通过Kudu Master Web UI查看

5.2Spark2验证
[root@ip-172-31-6-148~]# spark2-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). ForSparkR, use setLogLevel(newLevel).
17/09/11 09:46:22 WARN spark.SparkContext: Support for Java 7 is deprecated as of Spark 2.0.0
Spark context Web UI available at http://172.31.6.148:4040
Spark context available as 'sc' (master = yarn, app id =application_1505121236974_0001).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/__/ '_/
/___/ .__/\_,_/_//_/\_\ version 2.1.0.cloudera1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_67)
Type in expressions tohave them evaluated.
Type :help for more information.
scala> var textFile=sc.textFile("/fayson/test/a.txt")
textFile: org.apache.spark.rdd.RDD[String] =/fayson/test/a.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> textFile.count()
res0: Long = 3
scala> 
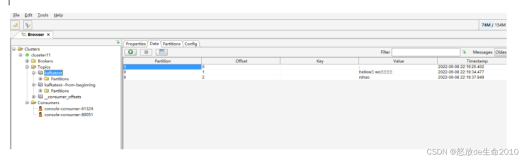
5.3Kafka验证
1.创建一个test的topic
[root@ip-172-31-6-148hive]# kafka-topics --create--zookeeper ip-172-31-6-148.fayson.com:2181 --replication-factor 3 --partitions1 --topic test
2.向topic发送消息
[root@ip-172-31-6-148hive]# kafka-console-producer--broker-list ip-172-31-10-118.fayson.com:9092 --topic test
3.消费topic的消息
[root@ip-172-31-6-148hive]# kafka-console-consumer --zookeeperip-172-31-6-148.fayson.com:2181 --topic test --from-beginning
4.查看topic描述信息
[root@ip-172-31-6-148hive]# kafka-topics --describe--zookeeper ip-172-31-6-148.fayson.com:2181 --topic test
醉酒鞭名马,少年多浮夸! 岭南浣溪沙,呕吐酒肆下!挚友不肯放,数据玩的花!
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
原创文章,欢迎转载,转载请注明:转载自微信公众号Hadoop实操