本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
以下为译文
机器学习理论 part II- 泛化界限(第I部分内容点此;第III部分内容点此)
上节总结到最小化经验风险不是学习问题的解决方案,并且判断学习问题可解的条件是求:
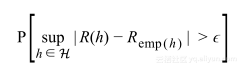
在本节中将深度调查研究该概率,看其是否可以真的很小。
独立同分布
为了使理论分析向前发展,作出一些假设以简化遇到的情况,并能使用从假设得到的理论推理出实际情况。
我们对学习问题作出的合理假设是训练样本的采样是独立同分布的,这意味着所有的样本是相同的分布,并且每个样本之间相互独立。
大数法则
如果重复一个实验很多次,这些实验的平均值将会非常接近总体分布的真实均值,这被称作大数规则,若重复次数是有限次m,则被称作弱大数法则,形式如下:
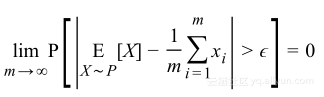
将其用在泛化概率上,对于单假设h有
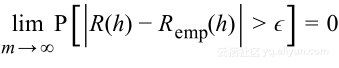
hoeffding不等式
集中不等式提供了关于大数法则是如何变化的更多信息,其中一个不等式是Heoffding不等式:
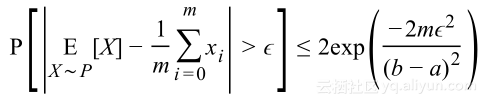
将其应用到泛化概率上,假设错误限定在0和1之间,则对于假设h有
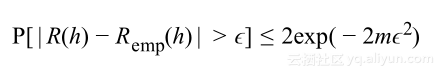
这意味着训练与泛化误差之间的差大于![]() 的概率是随着数据集的大小成指数衰减。
的概率是随着数据集的大小成指数衰减。
泛化界限:第一次尝试
为了针对整个假设空间都有泛化差距大于![]() ,表示如下:
,表示如下:
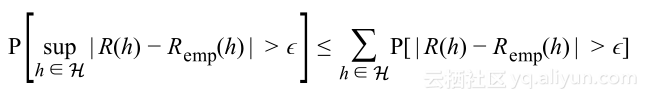
使用布尔不等式,可以得到
使用Heoffding不等式分析,能够准确知道概率界限,以下式结束:
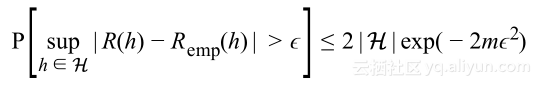
置信度1-δ有
![]()
使用基本代数知识,用δ表示![]() 得到:
得到:
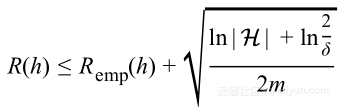
上式就是第一次泛化界限,该式表明泛化错误是受到训练误差加上以假设空间大小和数据集大小的函数的限定。
检验独立性假设
首先需要问自己是否每一个可能的假设都需要考虑?答案是简单的,由于学习算法需要搜索整个假设空间以得到最优的解决方案,尽管这个答案是正确的,我们需要更正式化的答案:
泛化不等式的公式化揭示了主要的原因,需要处理现存的上确界,上确界保证了存在最大泛化差距大于![]() 的可能性。如果忽略某个单假设,则可能会错过“最大泛化差距”并失去这一优势,这不是我们能够承担的,因此需要确保学习算法永远不会落在一个有最大泛化差距大于
的可能性。如果忽略某个单假设,则可能会错过“最大泛化差距”并失去这一优势,这不是我们能够承担的,因此需要确保学习算法永远不会落在一个有最大泛化差距大于![]() 的假设上。
的假设上。
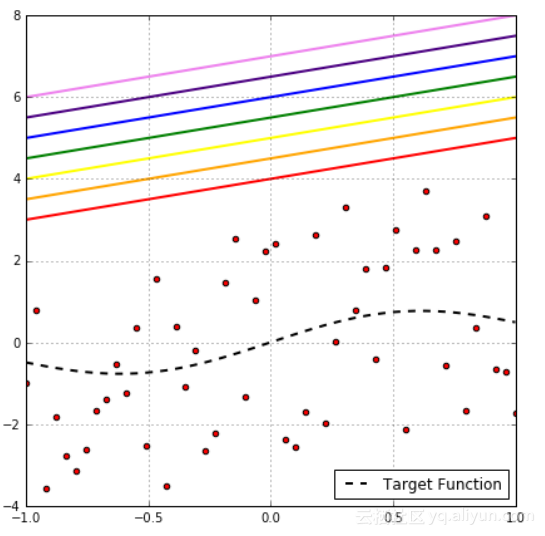
从上图可以看出是二分类问题,很明显彩色线产生的是相同的分类,它们有着相同的经验风险。如果只对经验风险感兴趣,但是需要考虑样本外的风险,表示如下:
为了确保上确界要求,需要考虑所有可能的假设。现在可以问自己,每一个有大泛化差距的假设事件可能是互相独立的吗?如果上图红线假设有大的泛化差距大于![]() ,那么可以肯定的是在该区域的每个假设也都会有。
,那么可以肯定的是在该区域的每个假设也都会有。
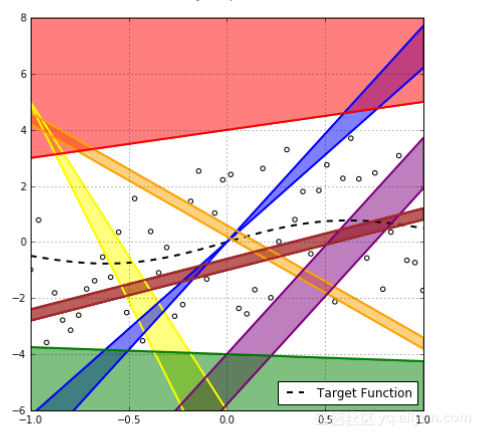
这对我们的数学分析是没有帮助的,由于区域之间看起来取决于样本点的分布,因此没有方法在数学上精确获取这些依赖性,于是这些统一的界限和独立假设看起来像是我们能够做的最佳近似,但它高估了概率并使得这些界限非常接近,性能不好。
对称引理
假设训练集是独立同分布,但不是只考虑数据集S的部分,假设有另外的数据集S’,大小为m,将其称作ghost数据集。使用ghost数据集可以证明:
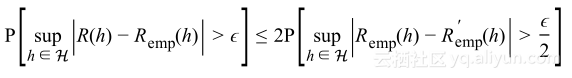 (1)
(1)
该式意味着最大泛化差距大于![]() 的概率几乎是S与S’之间的经验风险差概率大于
的概率几乎是S与S’之间的经验风险差概率大于![]() 的两倍,这被称作对称引理。
的两倍,这被称作对称引理。
生长函数
如果我们有许多假设有着相同的经验风险,可以放心地选择其中一个作为整个群的代表,将其称作有效假设并抛弃其它的假设。
假设在![]() 中的假设的独立性与之前在H的假设一样,使用一致限可以得到:
中的假设的独立性与之前在H的假设一样,使用一致限可以得到:
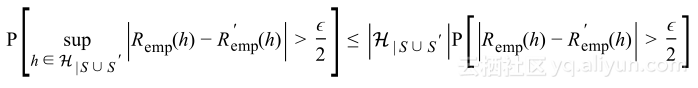 (2)
(2)
定义不同S数据集的标签值的最大数作为生长函数,对于二元分类情况,可以看到:
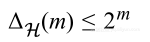
但由于是指数形式,随着m的增大而快速增长,这会导致不等式变坏的几率变得更快。
VC维
如果一个假设空间确实能够在数据点集上产生概率标签,我们可以说该假设空间打碎了该数据点集。但任何假设空间能打碎任何尺寸的数据集吗?下图展示的是2D的线性分类器有多少种方法标记3点(左边)和4点(右边)。

事实上,没有2D线性分类分类器可以打散任何4点的数据集,因为总是会有两个标签不能被线性分类器生成,如下图所示:
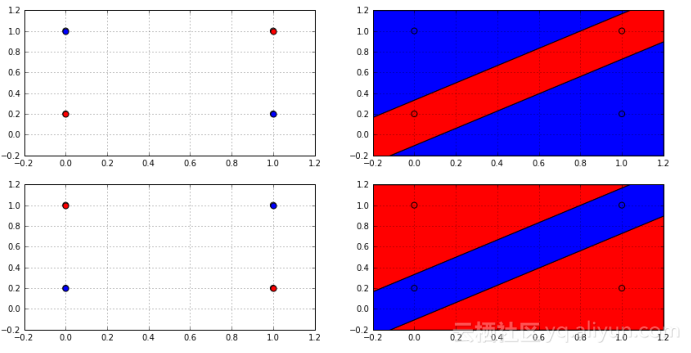
从图中的判定边界,可清晰知道没有线性分类器能产生这样的标签,因为没有线性分类器能够以这样的方式划分空间,这一事实能够用来获得更好的限定,这使用Sauer引理:
如果假设空间H不能打算任何大小超过k的数据集,那么有
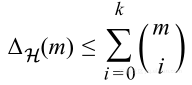
K是空间H能够打碎的最大数量点,也被称作Vapnik-Chervonenkis-dimension或者VC维数。
生长函数的界限是通过sauer引理提供的,确实是比之前的指数形式好很多,运用代数运算,能够证明:
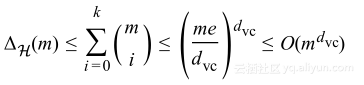
这样我们能够针对生长函数使用VC维数作为其替身,![]() 将会是复杂度或者假设空间丰富度的测量。
将会是复杂度或者假设空间丰富度的测量。
VC泛化界限
通过结合公式1与公式2可以得到Vapnik-Chervonenkis理论,形式如下:
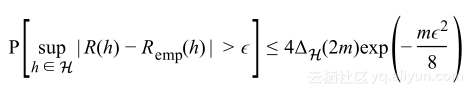
重新将其表述作为泛化误差上的界限,得到VC泛化界限:
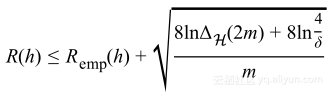
或者使用![]() 表示生长函数上的界限得到:
表示生长函数上的界限得到:
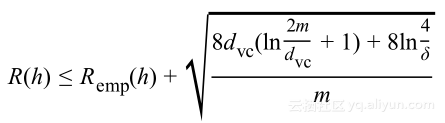
该式清晰并间接表示了学习问题是否可解,并针对无限假设空间,对其泛化误差有着有限的界限。
基于分布的界限
事实上,![]() 是带有值的自由分布:通过不利用结构和数据样本的分布,该界限会趋向于松弛。对于数据点是线性分开的,包含半径为R,两个非常接近点之间的边缘ρ,可以证明得到针对假设分类器有:
是带有值的自由分布:通过不利用结构和数据样本的分布,该界限会趋向于松弛。对于数据点是线性分开的,包含半径为R,两个非常接近点之间的边缘ρ,可以证明得到针对假设分类器有:
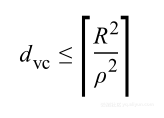
这就是支持向量机(SVM)背后的理论依据。
一个不等式去管理所有的它们
上面的所有分析是针对二元分类问题,然而VC的概念上的框架一般也适用于多分类与回归问题。根据相关研究人员的工作,不管这些工作产生的界限是多么的精确,总会有如下的形式:
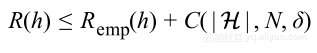
其中C是假设空间复杂度、数据集大小以及置信度δ的函数,这个不等式基本说明泛化误差能够分解为两部分:经验训练误差和学习模型的复杂度。该不等式的形式对于任何学习问题、不管多么准确界限而言都是适用的。
参考文献:
l Mohri, Mehryar, Afshin Rostamizadeh, and Ameet Talwalkar. Foundations of machine learning. MIT press, 2012.
l Shalev-Shwartz, Shai, and Shai Ben-David. Understanding machine learning: From theory to algorithms. Cambridge University Press, 2014.
l Abu-Mostafa, Y. S., Magdon-Ismail, M., & Lin, H. (2012). Learning from data: a short course.
文章原标题《Machine Learning Theory - Part II》,作者:Mostafa Samir,译者:海棠
文章为简译,更为详细的内容,请查看原文
