本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
以下为译文

这是构建深度学习模型来识别交通标志系列的第一部分。这部分是为我和想深入学习下去的人提供一些学习经验。市面上关于神经网络理论和数学证明的资料有很多,然而我关注的只是实战的部分。我会将我构件模型时候的经验写下来,和我的 源代码以及一些参考资料一并分享给大家。我的这篇文章对了解python并且有一定机器学习基础的人,能帮助他们接触到真实的实战项目。
在这部分中,我会简单介绍一下图形的分类。当然,我会尽可能的保持模型的简单性。在之后的部分中,我会增加卷积神经网络、数据增维、物体识别等方面的知识。
配置
我的代码发布在Jupyter notebook中,我用的python版本是3.5,TensorFlow版本是0.12。如果你喜欢在docker中运行代码,你可以用我的docker,它包含了许多深度学习的工具。可以用一下的命令来运行它。
docker run -it -p 8888:8888 -p 6006:6006 -v ~/traffic:/traffic waleedka/modern-deep-learning注意:我的工程目录是在~/traffic下,我在我的docker中将其映射到了/traffic目录下,如果你用了不同的目录,请修改它。
准备训练数据

找到一个合适的训练集是面临的首要问题。交通标志识别是一个研究比较充分的问题,因此我打算从网上找一个数据集。我用谷歌搜索关键字“交通标志数据集”,然后得到了许多选项。我最终选择了 比利时的交通标志数据集。因为用来训练,这个数据集已经足够大了,而在数据处理层面,它这个规模又很容易去处理。
你可以从这个网址中 http://btsd.ethz.ch/shareddata/.下载这个数据集。在这个页面上有许多数据,而我们需要的只是在BelgiumTS for Classification (cropped images)目录下的两个文件。
BelgiumTSC_Training (171.3MBytes)
BelgiumTSC_Testing (76.5MBytes)
解压文件后,尽量保持和我的路径一致,这样就可以直接运行代码而不用修改路径了。我的路径如下所示。
/traffic/datasets/BelgiumTS/Training/
/traffic/datasets/BelgiumTS/Testing/这两个目录下都包含62个子目录,它们都采用自然序号来命名,从00000到00061。目录名表示一个标签,而目录下的图片就是该标签的样本。
探索数据
如果用一个更正式的词来描述的话,这部分可以称为探索性数据分析。看起来这部分是可以跳过的,但是这部分中我用来检查数据的代码在整个项目中被复用了很多次。我经常在Jupyter notebooks 上做这样的工作并和我的组员分享。在项目开启的时候对代码足够的了解可以为将来的工作打下好的基础。
数据集中的图片是用一种古老的.ppm格式来存的。这个格式现在已经非常少见了,很多工具都不再支持它。这就意味着,我不能随意地打开某个文件夹,查看某张图。幸运的是Scikit Image library 支持这个格式。下面的代码会返回两个列表:图片和标签。
def load_data(data_dir):
# Get all subdirectories of data_dir. Each represents a label.
directories = [d for d in os.listdir(data_dir)
if os.path.isdir(os.path.join(data_dir, d))]
# Loop through the label directories and collect the data in
# two lists, labels and images.
labels = []
images = []
for d in directories:
label_dir = os.path.join(data_dir, d)
file_names = [os.path.join(label_dir, f)
for f in os.listdir(label_dir)
if f.endswith(".ppm")]
for f in file_names:
images.append(skimage.data.imread(f))
labels.append(int(d))
return images, labels
images, labels = load_data(train_data_dir)这个数据集不大,因此我能将它们加载到内存中。如果数据集大的话,就靠考虑批量载入数据了。
将图像加载到Numpy 数组中后,我将图像和标签都显示出来,具体代码在notebook上。下图是我们的数据集:

这些数据集看起来还不错,因为图像很清晰且包含了大量角度和情况。更重要的是,在每张图中,交通标志都占据了很大的位置。这样一来,我们不需要做繁琐的物体识别工作,只用做好我们的物体分类就可以了。在以后我会再发一个关于物体识别的帖子。
看到数据集,我的第一反应是,这些数据集都是正方形的,但是缩放比例不同。我的神经网络需要一个固定大小的输入,因此,我需要做一些预处理。下面是标签32的图片例子:

看起来在数据集中,无论标志上的数是多少,所有的速度标志都被归为了一类。这些知识都是必要的,因为这样我们就知道我们想要什么。在刚开始的时候充分理解数据集确实可以减少很多不必要的麻烦。
我们继续探索其它标签。标签26和标签27很有意思,它们都是在一个红圈里有一个数字,因此我们的模型必须要对它们加以区分。
处理不同大小的图像

大多数的图像分类神经网络的输入都是一个固定的值,我们的第一个模型也同样,因此我们需要对图像进行调整,保证它们尺寸相同。
由于图片从不同的角度,因此有些图片被水平或者竖直拉伸。这样会带来问题么?我认为,在这个案例中不会,因为不同图片中的角度相差并不大。我的观点是,如果一张被拉伸的图片人眼可以识别的话,那么模型也应该能识别。
那么,图片的大小是多少呢,让我们打印出一些例子。
for image in images[:5]:
print("shape: {0}, min: {1}, max: {2}".format(
image.shape, image.min(), image.max()))
Output:
shape: (141, 142, 3), min: 0, max: 255
shape: (120, 123, 3), min: 0, max: 255
shape: (105, 107, 3), min: 0, max: 255
shape: (94, 105, 3), min: 7, max: 255
shape: (128, 139, 3), min: 0, max: 255从输出结果看,选取128128的尺寸是比较合适的。这个尺寸几乎完全保留了图片信息,但在项目刚开始的阶段,我决定使用小一些的尺寸,这样训练起来会快一些,版本迭代也会快一些。我分别使用1616和2020的尺寸做了实验,发现这些图片都太小了,因此我最终选择了3232的比例,这个比例容易识别而且尺寸是原来的1/16,可以充分减少模型计算量。具体图像如下所示:
我认为经常使用min和max函数并打印结果是个非常好的习惯。这是找到数据边界和排查bug的非常好的一种方式。我测试了一下,图片的颜色是标准的0-255颜色。

最小可行模型
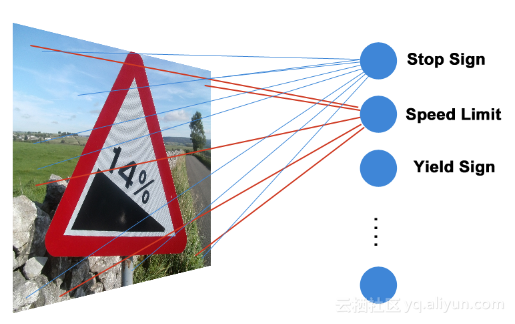
我们已经来到这部分最有趣的部分。依据极简的原则,我们设计的网络只有一层,而且只为每个标签配一个神经元。
这个神经网络有62个神经元,每个神经元以像素点的RGB值作为输入。实际上,每个神经元接受32*32=3072个输入。这是一个全连接层,因为每个神经元都连到每一个输入。你可能对下面的公式很熟悉。
y = xW + b我选择从最简单的模型开始,因为这样解释起来容易而且调试也不麻烦,最重要是训练很快。这个部分结束后,从简单模型扩展比从复杂模型扩展容易很多。
构建TensorFlow图
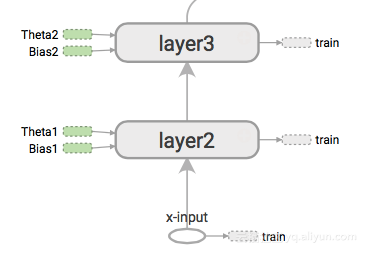
TensorFlow用执行图的方式来隐藏神经网络的架构。这个图中包含加、乘、改造等方法。这些操作对数据的张量上进行处理。
让我们一步一步地解释构建图的代码,下面是全部的代码,你可以先浏览一下。
with graph.as_default():
# Placeholders for inputs and labels.
images_ph = tf.placeholder(tf.float32, [None, 32, 32, 3])
labels_ph = tf.placeholder(tf.int32, [None])
# Flatten input from: [None, height, width, channels]
# To: [None, height * width * channels] == [None, 3072]
images_flat = tf.contrib.layers.flatten(images_ph)
# Fully connected layer.
# Generates logits of size [None, 62]
logits = tf.contrib.layers.fully_connected(images_flat, 62, tf.nn.relu)
# Convert logits to label indexes (int).
# Shape [None], which is a 1D vector of length == batch_size.
predicted_labels = tf.argmax(logits, 1)
# Define the loss function.
# Cross-entropy is a good choice for classification.
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
logits, labels_ph))
# Create training op.
train = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
# And, finally, an initialization op to execute before training.
# TODO: rename to tf.global_variables_initializer() on TF 0.12.
init = tf.initialize_all_variables()首先我创建了一个Graphic对象。TensorFlow拥有一个默认的全局graphic,但是我不建议使用它。全局变量很不好用,因为它会带来很多意想不到的bug。我们创建Graphic的方式如下所示:
graph = tf.Graph()然后我为图像和标签定义占位符。占位符是TensorFlow中使用的用来从主程序中接受输入的方法。在with graph.as_default()方法中,我定义了所有的占位符以及其他的操作。这样我就为我的graphic对象做了一些定制。
with graph.as_default():
images_ph = tf.placeholder(tf.float32, [None, 32, 32, 3])
labels_ph = tf.placeholder(tf.int32, [None])images_ph的占位符形式大概是[None, 32, 32, 3],这个分别表示[批次,高,宽,通道],批次是None表
示批次是灵活的,这就意味着我们可以在不改变代码的情况下修改批次。请注意参数的顺序,因为在像NCHW这样的模型中,参数的顺序是不同的。
接下来,我定义了全连接层。与往常不同,我没有实现y = xW + b等式,我使用了一个简单的非线性函数来实现激活函数的功能。我期望输入是个1维的数组,所以首先我将图片平整化。
我使用ReLU 作为激活函数。
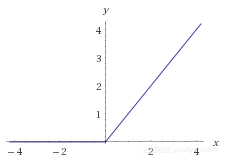
f(x) = max(0, x)所有负数的函数值都是0,这样对于分类任务和训练速度来说都会强于sigmoid和tanh函数。如果想了解详细,请点击这里和这里。
# Flatten input from: [None, height, width, channels]
# To: [None, height * width * channels] == [None, 3072]
images_flat = tf.contrib.layers.flatten(images_ph)
# Fully connected layer.
# Generates logits of size [None, 62]
logits = tf.contrib.layers.fully_connected(images_flat, 62,
tf.nn.relu)
全连接层的输出是一个长度为62的logits向量,从技术上讲,这是[None,62],因为我们处理一批logits向量。
logits向量的一行可能是 [0.3, 0, 0, 1.2, 2.1, .01, 0.4, ….., 0, 0]这样的形式。数值越高,说明图片属于标签的可能性越大,logits并不是概率,它的值可以是任意的,而且总和不一定是1。Logists的值是多少无所谓,关键是它们之间相对的大小关系。当然,使用softmax函数也可以将logits转换为概率。
在这个应用中,我们只需要数值最大的那个标签。Argmax函数实现了这一个功能。
# Convert logits to label indexes.
# Shape [None], which is a 1D vector of length == batch_size.
predicted_labels = tf.argmax(logits, 1)Argmax的输出是一个0到61的数。
损失函数和梯度下降
选择合适的损失函数本身就是一个研究领域,在这里我不会进行过多的探讨,我们只需要知道,交叉熵是分类任务最常见的函数。如果你对交叉熵的概念陌生的话,点击这里和这里,我们有个非常好的解释说明。
交叉熵是两个概率向量之间差别的量度。我们需要将logit转化为概率。sparse_softmax_cross_entropy_with_logits简化了这样的功能。它以logit向量和实际标签为输入,然后做了三件事情。第一件就是将形如 [None]的标签索引转换成[None, 62]的形式。第二件事是使用softmax函数将它们转换成预测logits 和标签logits。最后就算出它们的交叉熵。这将生成形如[None](长度=批量大小的1维数据)的损失向量,我们通过reduce_mean()获取单个损失值。
loss = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(
logits, labels_ph))选择优化算法又是另一个需要做的选择。通常我使用ADAM 优化器,因为它比简单的梯度下降算法收敛地要快。这篇帖子详尽的描述了不同梯度下降算法的对比。
train = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)图中的最后一点是初始化操作。它将所有值设置为0(或者是任意的随机值)。
init = tf.initialize_all_variables()请注意,上面的方法不执行任何操作,它仅仅构建图和描述输入。我们在上面定义的变量,例如init,loss,predicted_labels不包含数值,它们是我们接下来要执行的操作的引用。
训练循环
在这里,我们使用迭代的方式来减小损失函数。在开始训练之前,我们需要创建一个Session对象。在之前,我提到了Graphic对象,它包含了模型素有的操作,而Session则保存了模型中所有的变量。如果Graphic保存了等式 y=xW+b,那么Session保存着具体的数值。
session = tf.Session(graph=graph)一般来说,启动session之后会初始化操作,系统初始化和初始化变量。
session.run(init)接下来,我们重复地循环训练操作。当然,最好在训练过程中打印数值来监控训练的过程。
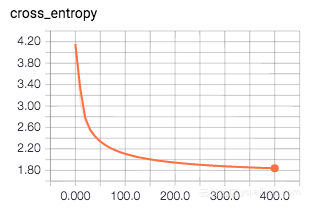
for i in range(201):
_, loss_value = session.run(
[train, loss],
feed_dict={images_ph: images_a, labels_ph: labels_a})
if i % 10 == 0:
print("Loss: ", loss_value)如果你想知道,我将循环设置为201,以使i%10条件满足最后一轮,并打印最后一个损失值。 输出应该看起来像这样:
Loss: 4.2588
Loss: 2.88972
Loss: 2.42234
Loss: 2.20074
Loss: 2.06985
Loss: 1.98126
Loss: 1.91674
Loss: 1.86652
Loss: 1.82595
...使用模型
现在我们在Session 对象中已经有一个训练好的模型了,我们调用session.run。正如在训练集中的一样,predicted_labels 返回了argmax函数的输出,这就是我们运行时需要的。我随机选择了10个图片,并把它们的实际标签和预测标签打印了出来。
# Pick 10 random images
sample_indexes = random.sample(range(len(images32)), 10)
sample_images = [images32[i] for i in sample_indexes]
sample_labels = [labels[i] for i in sample_indexes]
# Run the "predicted_labels" op.
predicted = session.run(predicted_labels,
{images_ph: sample_images})
print(sample_labels)
print(predicted)
Output:
[15, 22, 61, 44, 32, 22, 57, 38, 56, 38]
[14 22 61 44 32 22 56 38 56 38]在notebook中,我准备了一个可视化的函数,它大体上看起来像下图所示那样。

结果显示,我们的模型奏效了,但并没有亮化它的准确率。你可能会发现,这是用来分类训练图像,因此,我们不知道推广到没见过的图像,它的准确性怎么样,在以后的工作中,我们会计算更好的评估指标。
评估
为了评估我们的模型应对没见过的数据的准确率,我用训练中没有使用过的数据作为测试集。BelgiumTS 提供了两个分离的数据集,一个是用来训练,一个用来测试。
在notebook中,我载入测试集,修改图片大小,然后计算准确性。下面是用来计算准确性的相关代码。
# Run predictions against the full test set.
predicted = session.run(predicted_labels,
feed_dict={images_ph: test_images32})
# Calculate how many matches we got.
match_count = sum([int(y == y_)
for y, y_ in zip(test_labels, predicted)])
accuracy = match_count / len(test_labels)
print("Accuracy: {:.3f}".format(accuracy))我计算出来的准确率从40到70不等。这取决于模型达到了局部最优还是全局最优。对于简单模型,这个结果和预期的一样,而在以后的帖子中,我会介绍模型的调优。
关闭Session
恭喜你,我们已经拥有了一个简单的神经网络。这个神经网络很小,用我的笔记本训练也就是1分钟的时间,因此存储这个模型并不麻烦。在下一部分,我会增加保存和载入模型的代码,然后扩展使用多层神经网络、卷积神经网络以及数据增维等技术。敬请关注!
# Close the session. This will destroy the trained model.
session.close()文章原标题《Traffic Sign Recognition with TensorFlow》,作者:Waleed Abdulla,译者:爱小乖
#文章为简译,更为详细的内容,请查看原文