从游戏发展的角度来看,不管是端游、页游,还是现在发展迅猛的手游,其生命周期与盈利情况都与数据分析能力息息相关。同时数据分析对游戏的运维也起到了至关重要的作用。精确的数据分析有助于在做游戏运营时推出合理的新手引导,在及时的渠道推广和丰富的消费场景设计,这些将极大地影响游戏玩家对游戏的关注度,从而延长游戏的生命周期,并从中更好盈利。
游戏数据分析特点
分析是建立在数据上的,数据的特点决定了分析的方向和方法。游戏数据的特点主要表现在以下四个方面。
第一,数据量大。以手机游戏为例,一款中型规模手游的日均数据量增长在几十GB。在这种情景下,做常见的月活、季活等游戏指标分析所面对的就是TB级别的海量数据。
第二,数据类型丰富。从游戏数据的种类来看,分为结构化数据和非结构化数据。从数据存放的位置来看,可以分为文本数据、缓存数据库数据、关系型数据库数据等。
第三,分析维度多样。由于游戏指标不同,所以游戏分析的维度有很大差异。例如,游戏指标通常玩家指标、性能指标和过程指标三类。
- 玩家指标,一般用于计算与收入相关的指标,如用户平均消费指标(ARPU,average revenue per user )和每日活跃用户(DAU,daily active users ),也可以用于调查人们如何与游戏系统交互,如用户游戏时间和用户的游戏内好友平均数。
- 性能指标,针对游戏技术和软件框架性能,一般包含游戏在用户硬件平台上运行的帧速率,也被用来在观察打补丁或升级时对用户造成的操作影响。
- 过程指标,针对游戏开发实际过程中的数据指标。
第四,实时性强。数据分析分为四个层次,数据量少实时性低,数据量少实时性高,数据量大实时性低,数据量大实时性高。这四个数据分析的层次对技术难度的要求是逐渐提高的。而游戏数据分析的特点可以划定在最后一档即数据量大实时性高,所以海量游戏数据分析对技术能力和软件需求提出了极大的挑战。
游戏数据分析现状及瓶颈
我们曾拜访了近百家游戏客户,深入了解游戏开发商如何处理和分析数据,发现目前数据分析在不同游戏行业中使用程度不同,主要表现在游戏规模越大,使用的数据分析维度越广,程度越深;中小型游戏数据分析使用程度一般。总体来说,游戏数据分析的现状如下。
- 不做数据分析。这种类型的游戏客户在小型页游和大厅类游戏中比较常见,只是出于备份的需要将数据从生产环境中定时批量备份出来,用单独的硬盘或者服务器做数据存储。
- 数据库级别执行SQL查询。大多数的游戏客户将生产数据备份出来,导入到专有的数据库中做离线数据分析,采用的方法是使用SQL语言和第三方报表工具做基本的数据查询。但基于数据库对数据量的限制,当单表记录到千万甚至上亿级别后,这种分析方法就基本行不通了。
- 使用成熟的数据仓库产品。在中大型游戏客户中,数据规模已达到一定的数量级别,游戏运维离不开数据分析的支撑。这种情况下,用户会选用数据仓库产品,将数据库中的数据经过ETL后导入到数据仓库中做数据分析,或者用户利用物理机集群自建大数据分析平台,例如Hadoop,Spark等分布式大数据分析框架,结合具体应用场景做大数据分析。
在数据分析中,当数据量达到海量级别后,上述三种情况都会遇到相应的瓶颈:
- TB/PB级别的数据分析耗时太长;
- 时间跨度大的数据分析耗时太长;
- SQL无法满足所有数据分析需求;
- 海量数据的存储问题。
除了海量数据处理能力问题之外,用户在自建Hadoop等分布式大数据分析框架中也会遇见技术难度高、框架维护成本高等问题。
阿里云产品和服务选型
在协助游戏客户将数据分析上云之前,我们仔细分析了目前用户的数据分析方式。他们的数据目前主要以两种形式存在,文本日志数据和数据库关系型数据。
- 文本日志数据记录的是玩家实时战斗信息、晶钻消费信息和登录状态信息。这些数据在每个游戏服务器上都会产生,遵循用户自定义的数据格式。用户有一组专门的日志服务器和自定义程序在游戏服务器上定时批量抽取这些文本数据存放到日志服务器上。
- 存放在数据库中的关系型数据增长速度通常会比较快。
上述两种类型的数据都会被批量导入到数据仓库中,进行数据分析。在技术选型上,客户给我们提出了两点要求。
- 要保证上云后数据分析的效率,因为基于目前使用数据仓库分析的方式,分析日活、月活等信息时平均耗时在几十分钟级别。
- 要提高数据分析的实时性,上云之前,对类似晶钻消费等数据做分析存在至少1个小时的延时,用户希望上云后能得到更加实时的分析结果。
面对客户的需求,我们在选择阿里云服务时,首先想到了阿里云数加-大数据计算服务MaxCompute,产品地址:https://www.aliyun.com/product/odps。然后我们选择了对文本日志数据支持较好的SLS(Simple Log Service,简单日志服务)。SLS为大量服务器日志文件的收集提取提供了一种监听实时抽取的服务,此外SLS和MaxCompute底层是打通的,所有存放在SLS服务器上的日志数据会被自动离线备份到MaxCompute中,方便用户做进一步的数据分析。除了MaxCompute和SLS服务,我们的方案中还使用了RDS(Relational Database Service,关系型数据库服务)以及DPC(Data Process Center,采云间)控制台工具。
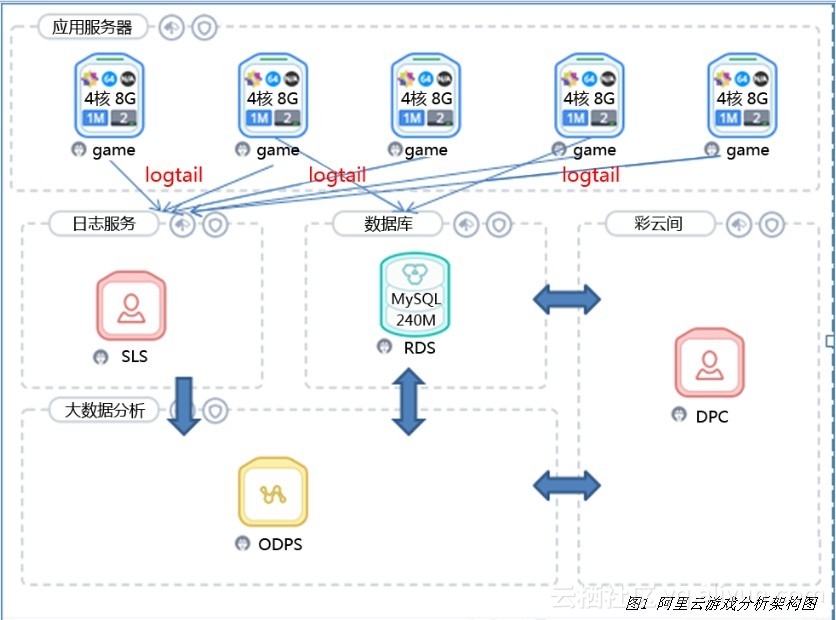
利用上述提到的阿里云服务,游戏数据分析方案中的架构如图1所示。SLS通过安装在游戏服务器ECS上的Logtail客户端,建立一种类似心跳的方式监听文本日志文件,并按照用户指定的格式将数据抽取后以键值对的形式存放到SLS服务器。每条记录包含了时间、来源ECS IP地址和抽取的键值对信息。MaxCompute在游戏数据分析中可以被当成是一个大数据分析平台,可以将SLS和RDS数据导入到MaxCompute中,利用MaxCompute强大的数据分析能力分析游戏数据。DPC在游戏数据分析中充当IDE角色,除了应用在数据的导入导出,MaxCompute任务管理,还可以用来做最后的数据分析结果展示。
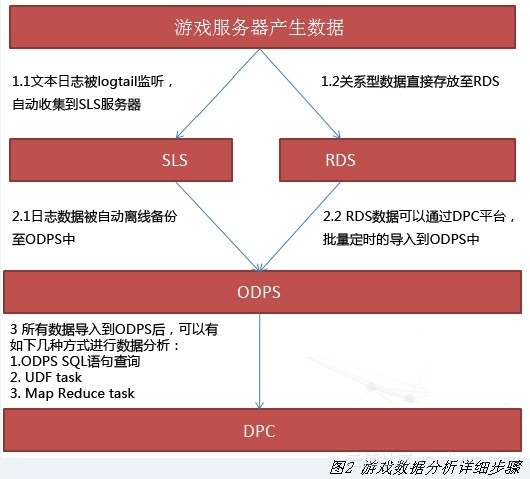
接下来详细介绍上述场景中,游戏数据分析的具体步骤,参见图2。我们可以看到,游戏应用服务器在运行期间产生了大量的数据,接下来分别介绍文本数据和关系型数据导入至MaxCompute的实现步骤,然后结合数据分析的具体场景介绍在MaxCompute中做数据分析的实现方式。
第一,SLS处理文本日志详细步骤。在游戏服务器运行过程中,按照业务逻辑规划,一部分数据将直接写入到文本日志里进行保存。文本日志数据生成在本地指定目录文件中,且文件名按照时间命名,路径格式/var/log/game/$ {serverid}/${YYYYMM}/{DD}/{YYYYMMDD.HH24}.log,产生的一条日志记录如下所示:
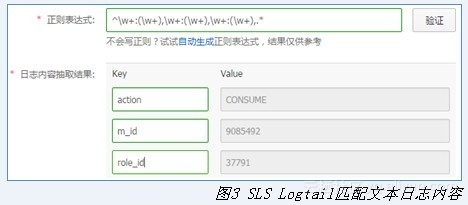
action:CONSUME,m_uid:9085492,role_id:……,channel:20016,plat:ANDROID,udid:7ca94b77-fa76-……-2ad2ffe54ab3,server:……,role_name:monkey,ip:……,consume_time:2014-08-20 00:02:03,role_lv:22,item_id:0,amount:25,remain_amount:89,orderid:0,blue_amount:25,red_amount:0,blue_remain:89,red_remain:0。Logtail是ECS上的监听程序,可以配置监听目录和提取的日志内容,例如对上文的文本内容用自定义正则表达式提取出来,内容如图3所示。
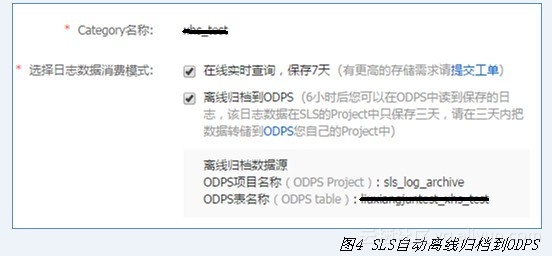
日志被提取出来后,会按照(key:value)键值对的方式保存至SLS指定Category。日志被提取到SLS服务器后,除了每条SLS日志记录被提取的文本内容,还会记录一个时间和IP,这里时间是指数据写入文本日志的时间,IP记录了文本日志来源的游戏服务器IP地址。同时,已经保存在SLS服务器的数据会自动离线保存到MaxCompute用户指定的Project里面,如图4所示。
SLS Category存放的所有记录会自动离线保存到MaxCompute中,首次数据备份在6个小时内完成,以后每小时SLS的数据会被增量备份至MaxCompute。
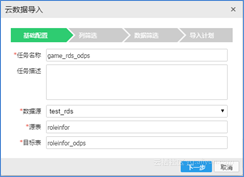
第二,RDS处理关系型数据详细步骤。关系型数据是游戏服务器在运行过程中,对用户角色创建和用户消费行为数据的记录,直接通过业务逻辑写到RDS数据库中保存。RDS里面的数据,可以通过阿里云DPC工具,将数据批量定时地导入到MaxCompute指定Project里,如图5所示。
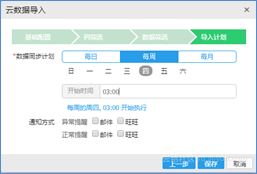
RDS数据导入经过基础配置、列筛选、数据筛选三个步骤后,就可以发布导入计划时间,可以分为每日、每周、每月进行数据导入。关于导入的数据筛选和导入时间的设置,完全取决于用户的使用场景。例如,用于游戏消费数据信息这种实时分析要求较高的数据建议选择每日非活跃时间段定时导入。任务发布后,可以继续通过DPC控制台对任务的执行情况进行查看。
第三, MaxCompute数据分析详细步骤。在游戏服务器产生的文本数据和关系型数据都集中导入到MaxCompute之后,接下来可以利用MaxCompute平台本身的产品特性,开始做用户自定义的数据分析。MaxCompute中常用的数据分析有以下几种方法。
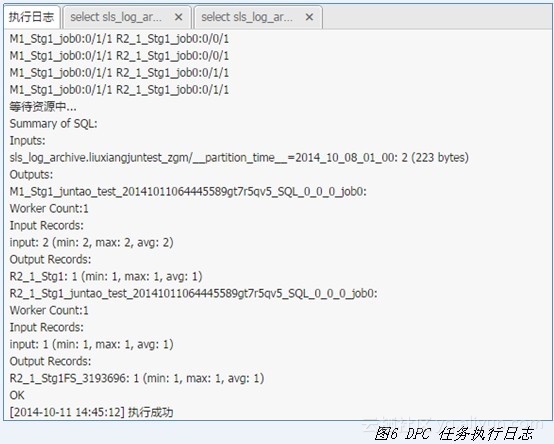
- MaxComputeSQL语句查询,能查询满足用户绝大多数的数据分析需求,如图6所示。
- 发布自定义UDF任务。UDF是指用户自定义函数处理,例如做一个游戏描述的大小写转换函数,用Java代码编写好函数后,打包成Jar文件发布到MaxCompute中,然后SQL语句里面就可以直接调用函数功能。
- 发布MapReduce任务。阿里云MaxComputeMapReduce和UDF功能在Eclipse开发工具中有相应的开发插件,在插件完成安装后,创建MapReduce功能。
在创建MapReduce文件后,根据实际游戏数据分析任务,分别完成Map函数和Reduce函数的编码,然后通过Driver类设置运行资源和格式。在Eclipse中完成的MapReudce任务可以打包成为一个Jar文件发布到MaxCompute指定Project。
第四,DPC数据展示。目前DPC的图形化数据展示功能还没有开放,本节将使用表格化数据举例说明DPC数据处理结果。发布任务后,DPC控制台提供查看操作日志的功能,如图6所示。
目前,所有子任务执行成功后,数据分析的结果会以表格的形式展现,同时这些数据分析结果也可以通过DPC工具保存至RDS。在RDS中数据的交互性更强,可以利用第三方报表工具做多维度的数据展示。
总结
阿里云发展到现在已经提供了20多种云产品和服务。这些服务功能选择性多,稳定性好,性能优异,节省了用户使用成本。希望阿里云能推出更多稳定可靠的产品和服务给技术人员更多的选择。