上一篇博文中提到用正则表达式来匹配数据项,但是写起来容易出错,如果有过DOM开发经验或者使用过jQuery的朋友看到BeautifulSoup就像是见到了老朋友一样。
安装BeautifulSoup
Mac安装BeautifulSoup很简单,打开终端,执行以下语句,然后输入密码即可安装
sudo easy_install beautifulsoup4
改代码
#coding=utf-8
import urllib
from bs4 import BeautifulSoup
# 定义个函数 抓取网页内容
def getHtml(url):
webPage = urllib.urlopen(url)
html = webPage.read()
return html
# 定义一个函数 抓取网页中的图片
def getNewsImgs(html):
# 创建BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
# 查找所有的img标签
urlList = soup.find_all("img")
length = len(urlList)
# 遍历标签 下载图片
for i in range(length):
imgUrl = urlList[i].attrs["src"]
urllib.urlretrieve("http://www.abc.edu.cn/news/"+imgUrl,'news-%s.jpg' % i)
# 获取网页
html = getHtml("http://www.abc.edu.cn/news/show.aspx?id=21430&cid=5")
# 抓取图片
getNewsImgs(html)
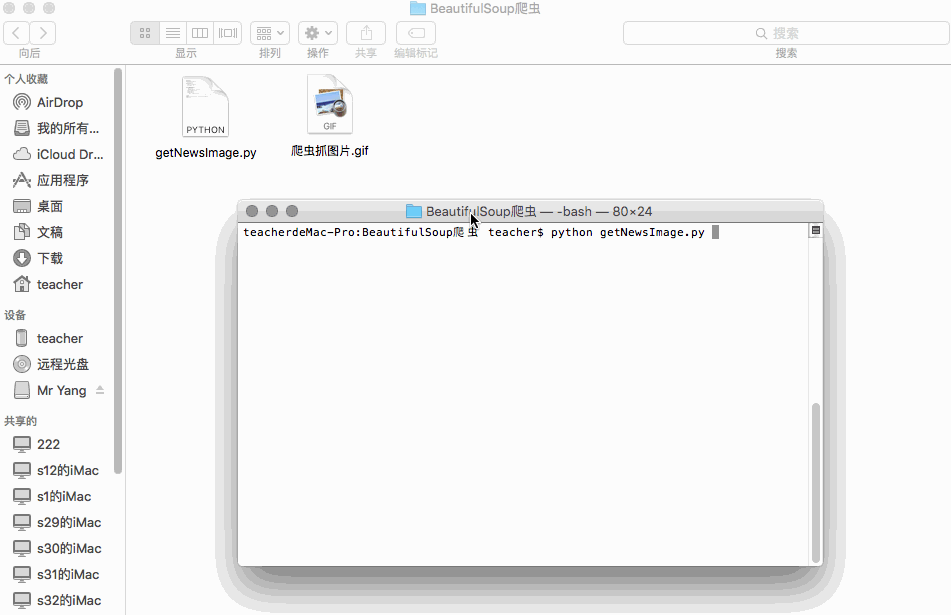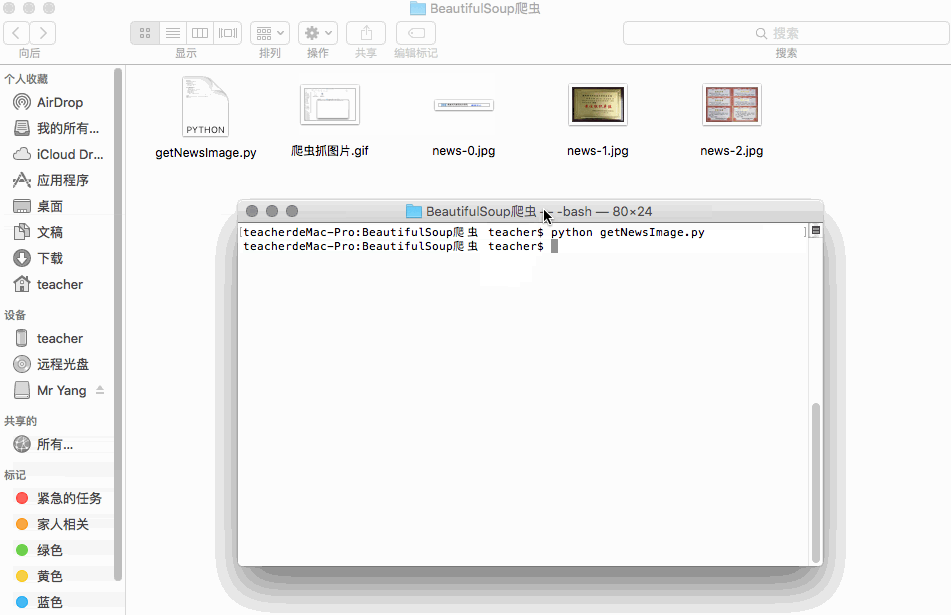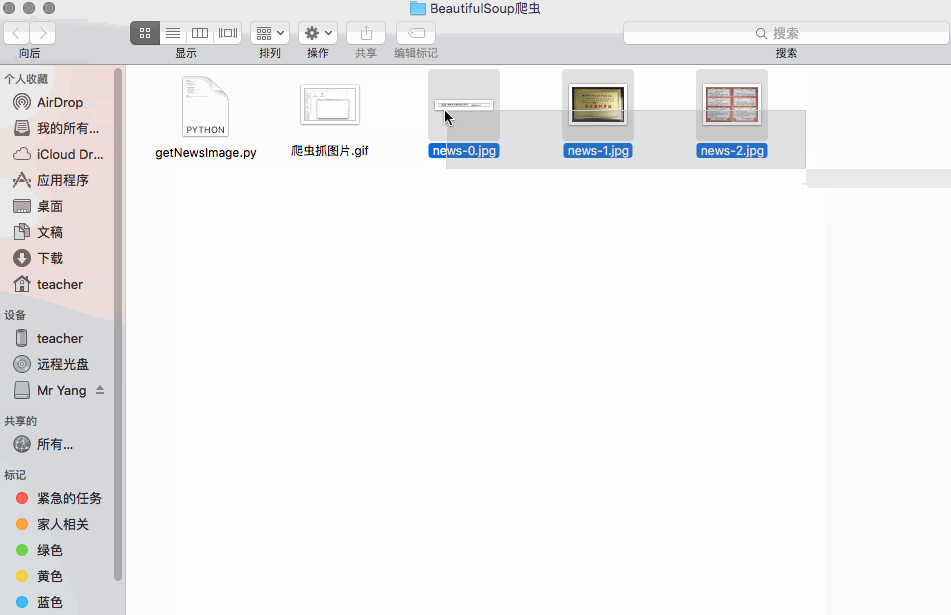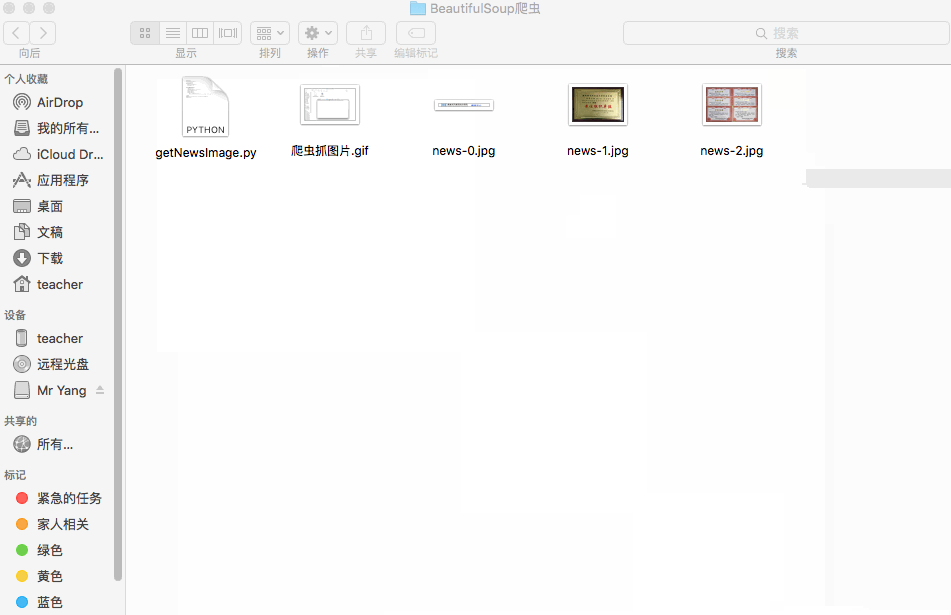
效果:换了一个新闻,抓取了新闻中的三张图片O(∩_∩)O~
爬虫抓图片.gif
