1.批处理Batch Processing
定义:将任务成批地提交给系统,由系统自动完成后再输出结果。
举个例子,住在UIC新小镇的人去旧小镇上课,学校没造诺亚方舟,没办法哗啦一下送过去,只能用几辆大巴,将我们一批批送过去。
批处理模式中使用的数据集通常符合下列特征:
- 有界:批处理数据集代表数据的有限集合(新小镇宿位有限,人数肯定也是有限的)
- 持久:数据通常始终存储在某种类型的持久存储位置中(只要不来14级台风,宿舍楼都一直完好无损的在那里)
- 大容量:批处理操作通常是处理极为海量数据集的唯一方法(对于学校可借调交通工具的容量来看,新小镇学生人数算是大容量的)
批处理非常适合需要访问全套记录才能完成的计算工作,比如:在计算总数和平均数时,必须将数据集作为一个整体加以处理,而不能将其视作多条记录的集合。这些操作要求在计算进行过程中数据维持自己的状态(静态)。显然,批处理不适合对处理时间要求较高的场合(实时性任务)。
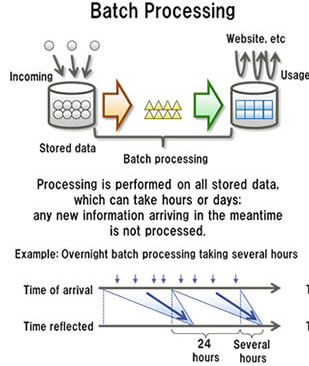
需要处理大量数据的任务通常最适合用批处理操作进行处理。无论直接从持久存储设备处理数据集,或首先将数据集载入内存,批处理系统在设计过程中就充分考虑了数据的量,可提供充足的处理资源。由于批处理在应对大量持久数据方面的表现极为出色,因此经常被用于对历史数据进行分析。
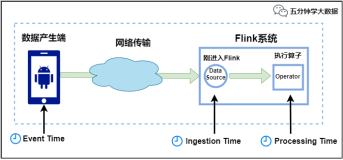
2.流处理Stream processing
定义:对随时进入系统的数据进行计算。流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作。
吃栗子了:在首页上显示该网站的注册用户数
流处理中的数据集是无边界的,这就产生了几个重要的影响:
- 完整数据集只能代表截至目前已经进入到系统中的数据总量。(截至当前的的注册用户)
- 工作数据集也许更相关,在特定时间只能代表某个单一数据项。(某一时刻的注册人数)
- 处理工作是基于事件的,除非明确停止否则没有“尽头”(有人死去,有人出生)
- 处理结果立刻可用,并会随着新数据的抵达继续更新。
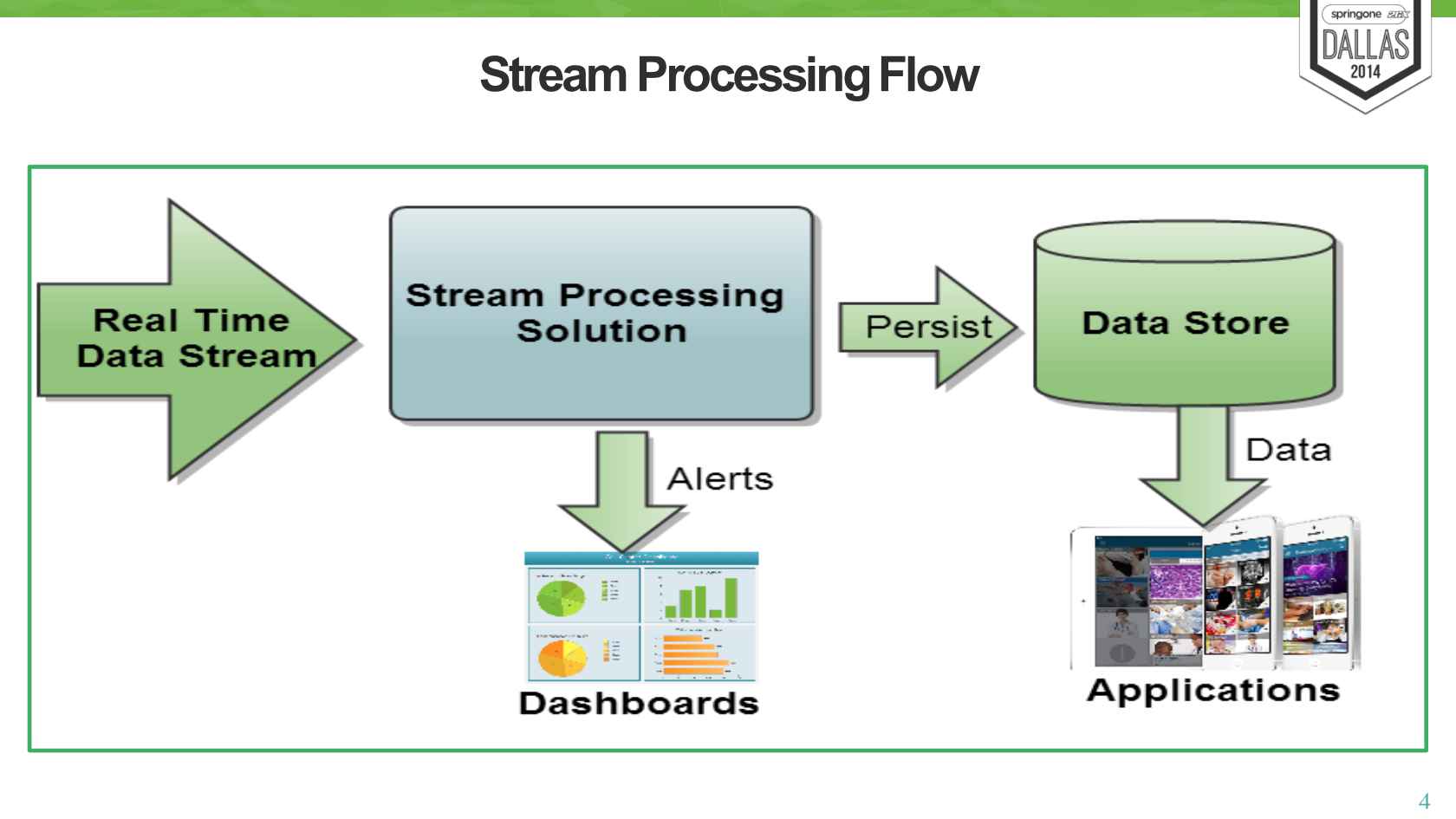
显然有近实时处理需求的任务很适合使用流处理模式。分析、服务器或应用程序错误日志,以及其他基于时间的衡量指标是最适合的类型,因为对这些领域的数据变化做出响应对于业务职能来说是极为关键的。流处理很适合用来处理必须对变动或峰值做出响应,并且关注一段时间内变化趋势的数据。
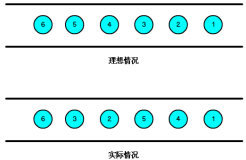
流处理系统可以处理几乎无限量的数据,但同一时间只能处理一条(真正的流处理)或很少量(微批处理,Micro-batch Processing)数据,不同记录间只维持最少量的状态。虽然大部分系统提供了用于维持某些状态的方法,但流处理主要针对副作用更少,更加功能性的处理(Functional processing)进行优化。
功能性操作主要侧重于状态或副作用有限的离散步骤。针对同一个数据执行同一个操作或忽略其他因素产生相同的结果,此类处理非常适合流处理,因为不同项的状态通常是某些困难、限制,以及某些情况下不需要的结果的结合体。因此虽然某些类型的状态管理通常是可行的,但这些框架通常在不具备状态管理机制时更简单也更高效。
大数据框架
| 大数据框架 | 支持批处理 | 支持流处理 |
|---|---|---|
| Apache Hadoop | √ | |
| Apache Storm | √ | |
| Apache Samza | √ | |
| Apache Spark | √ | √ |
| Apache Flink | √ | √ |
Lambda 架构
实时大数据处理框架Storm作者Nathan Marz认为,数据系统的本质是“查询+数据”,用公式表达: Query = Function(All Data)
那么问题来了,如何实时地在任意大数据集上进行查询?如果单纯地对全体数据集进行在线查询,那么计算代价会很大,延迟也会很高,比如Hadoop。
为了解决这个问题,他提出了一个实时大数据处理Lambda架构。
Lambada有两个假设:
- 不可变假设:Lambda架构要求data不可变,这个假设在大数据系统是普遍成立的:因为日志是不可变的,某个时刻某个用户的行为,一旦记录下来就不可变。
- Monoid假设: 理想情况下满足Monoid 的function可以转换为:
Query = Function(All Data/ 2) + Function(All Data/ 2)
Monoid的概念来源于范畴学(Category Theory)【是的没错,又多学了一个装逼的词】它有一个特别简单的重要特性:满足结合律。如整数的加法就满足Monoid特性:(a+b)+c=a+(b+c)
不满足Monoid特性的函数很多时候可以转化成多个满足Monoid特性的函数的运算。求多个数的平均值avg函数,多个平均值没法直接通过结合来得到最终的平均值,但是可以拆成分母除以分子,分母和分子都是整数的加法,从而满足Monoid特性。
Monoid的结合律特性在分布式计算中极其重要,满足Monoid特性意味着我们可以将计算分解到多台机器并行运算,然后再结合各自的部分运算结果得到最终结果。同时也意味着部分运算结果可以储存下来被别的运算共享利用(如果该运算也包含相同的部分子运算),从而减少重复运算的工作量。
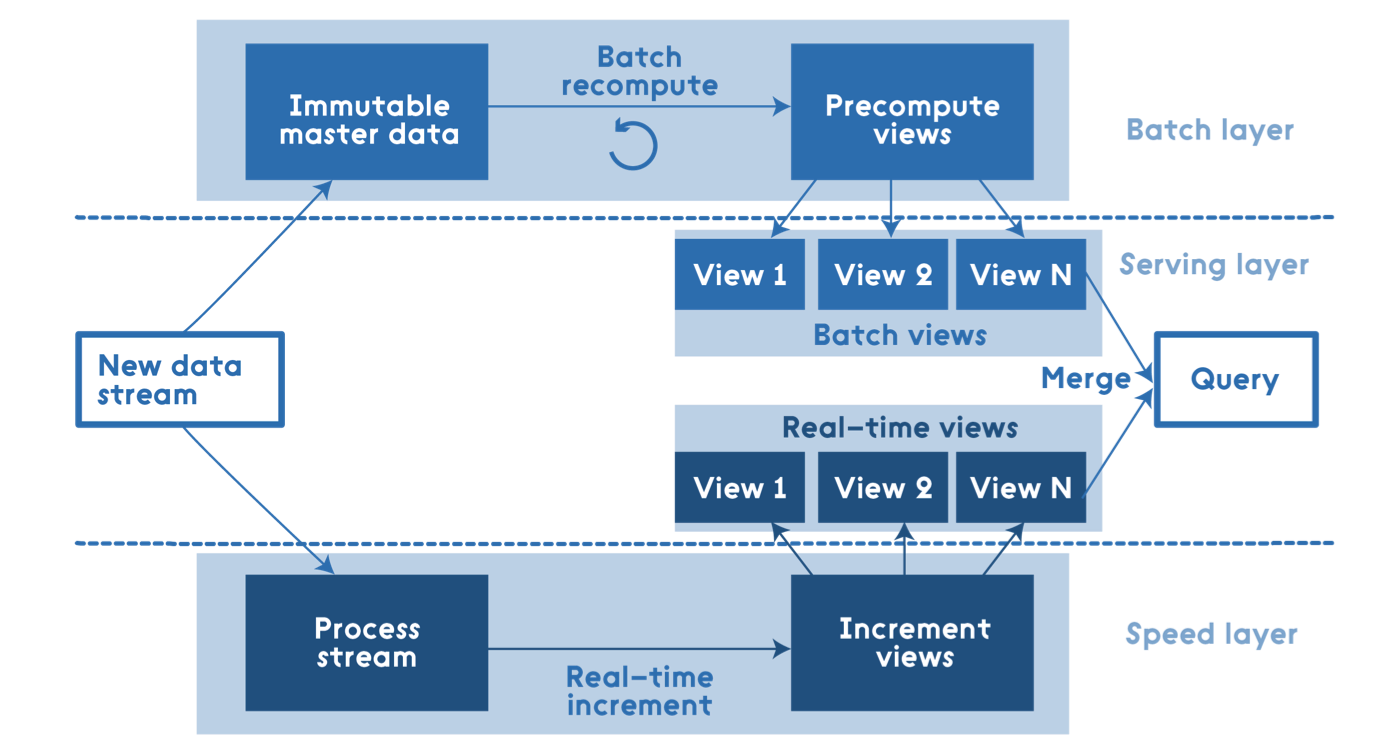
Lambda的做法是将大数据系统架构拆分成了三层:Batch Layer,Speed Layer和Serving Layer。
I. Batch Layer
既然对全体数据集进行在线查询,计算代价会很高,那么如果对查询事先进行预计算,生成对应的Views,并且对Views建立索引,这样,查询的速度会提高很多,这就是Batch Layer所做的事。
Batch Layer层采用不可变模型对所有数据进行了存储,并且根据不同的业务需求(这里体现了Batch的概念),对数据进行了不同的预查询,生成对应的Batch Views,这些Batch Views提供给上层的Serving Layer进行进一步的查询。另外,每隔一段时间都会进行一次预查询,对Batch Views进行更新,Batch Views更新完成后,会立即更新到Serving Layer中去。
II. Speed Layer
如上一节中提到,预查询的过程是一个批处理的过程,该过程花费的时间会比较长,在该过程中,Serving Layer使用的仍然是旧版本的Batch Views,那么仅仅依靠Batch Layer这一层,新进入系统的数据将无法参与最后结果的计算,因此,Marz为Lambda设计了Speed Layer层来处理增量的实时数据。
Speed Layer和Batch Layer比较类似,对数据计算生成Realtime Views,其主要的区别是:
- Speed Layer处理的数据是最近的增量数据流,Batch Layer处理的是全体数据集。
- Speed Layer为了效率,接收到新数据时,就更新Realtime Views,并且采用的是Incremental Updates(增量计算模型),而Batch Layer则是根据全体离线数据集得到Batch Views,采用的是Recomputation Updates(重新计算模型)。
III. Serving Layer
Serving Layer用于响应用户的查询请求,它将Batch Views和Realtime Views的结果进行了合并,得到最后的结果,返回给用户。
前面我们讨论了查询函数的Monoid性质,如果查询函数满足Monoid性质,即满足结合率,只需要简单的合并Batch View和Realtime View中的结果数据集即可。否则的话,可以把查询函数转换成多个满足Monoid性质的查询函数的运算,单独对每个满足Monoid性质的查询函数进行Batch View和Realtime View中的结果数据集合并,然后再计算得到最终的结果数据集。另外也可以根据业务自身的特性,运用业务自身的规则来对Batch View和Realtime View中的结果数据集合并。
Lambda架构组件选型
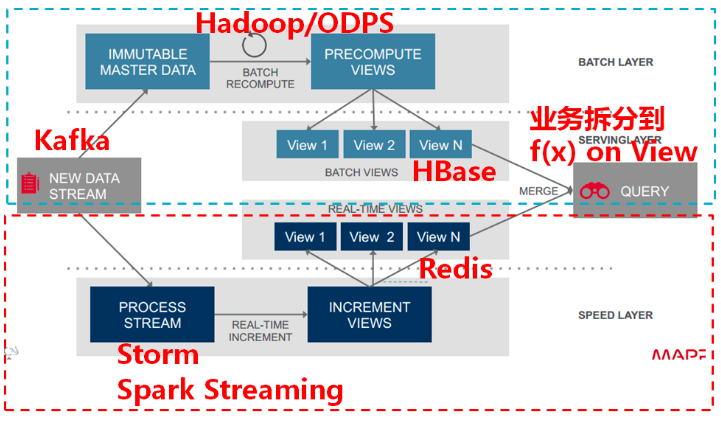
下图给出了Lambda架构中各个层常用的组件。
- 数据流存储:可选用基于不可变日志的分布式消息系统Kafka;
- Batch Layer数据集的存储:可选用Hadoop的HDFS,或者是阿里云的ODPS;
- Batch View的预计算:可以选用MapReduce或Spark;
- Batch View自身结果数据的存储:可使用MySQL(查询少量的最近结果数据),或HBase(查询大量的历史结果数据)
- Speed Layer增量数据的处理:可选用Storm或Spark Streaming;
-
Realtime View增量结果数据集:为了满足实时更新的效率,可选用Redis等内存NoSQL。
举个例子
本案例为某省的智慧交通系统。
系统各层组件的选型
根据上面的介绍,Lambda架构包括三层,其中Batch Layer负责数据集的存储和批处理的执行,数据存储我们选择Hyperbase。Hyperbase支持快速高并发的查询,可以方便用户做一些精确类查询(如根据车牌号检索等)。由于此项目还有一些统计类的业务需求,我们选择将部分数据在HDFS上保留一份用作后期的分析之用,Inceptor的强大的数据分析能力可以帮助用户在任意维度上做复杂的数据分析工作。
Speed Layer主要负责对数据的实时处理,可以使用Transwarp Stream。此外,Kafka选择使用Transwarp Kafka 0.9版本,由于增加了Kafka队列内的kerberos安全认证功能,消息队列中的数据更安全。
HDFS和Hyperbase的数据通过SQL以及JDBC接口开放给用户,企业可以开发Serving Layer中自身需要的业务。由于这些应用程序是具体的企业内部业务,此处不做讨论。
系统各层机器规划
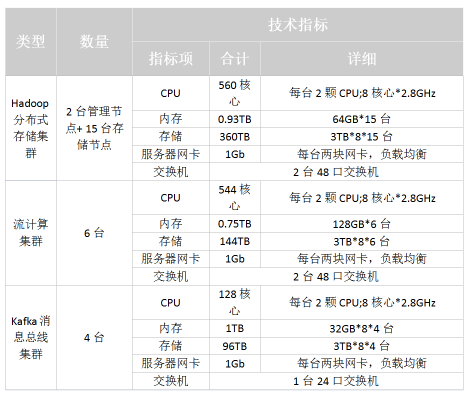
有了上面的组件选型,下面我们可以进行机器规划。主要考虑的是以下几个方面:
存储能力
就某地市而言,每天约有1000w的过车记录产生,高峰时期每秒能约有1w条过车记录产生,每条过车记录对应的结构化数据约有30个字段,大小为200Byte;每天还有50w张左右大小约为500KB的图片数据,按照规划数据需要存储的周期为2年,因此对集群容量要求如下:
结构化数据存储三份、图片数据存储两份,2年的数据总量约为:
(1000w * 200B 3 + 50 w * 500KB * 2) * 365 * 2 = 344TB
每台机器有8个硬盘,每个硬盘容量为3TB,则需要数据节点数为:
344TB / (3TB8) = 15台
另外,Hadoop分布式存储集群需要2台管理节点。实时计算的需求
目前需要进行实时处理的业务包括:
a. 实时检测业务:逾期未年检、黑名单、逾期未报废、凌晨2点到5点上路行驶的客运车辆、车主驾驶证无效车辆等。
b. 实时分析业务:包括流量统计、旅行时间分析、套牌车检测、区间测速等。
其中实时检测业务以及套牌车检测等要求在秒级别反馈结果以对违法行为进行实时拦截;分析业务要求在分钟级别更新结果。
按照每秒1w条过车记录计算,总共有20+个流处理业务(比对和复杂分析)同时运行,预估需要实时处理集群机器6台。
另外,所有的过车记录都会预先被接入Kafka分布式消息处理集群,每条记录写入3份,保存7天,预估需要Kafka集群机器4台。
- 批处理分析要求
除了实时处理业务之外,还需要对历史数据进行统计分析,对于时间跨度在一个月内的统计分析需要在秒级返回结果;对于时间跨度在三个月以上的复杂统计分析需要在分钟级别返回结果。
依据上述的要求分析,给出机器数目和配置参考图如下:
- 系统架构
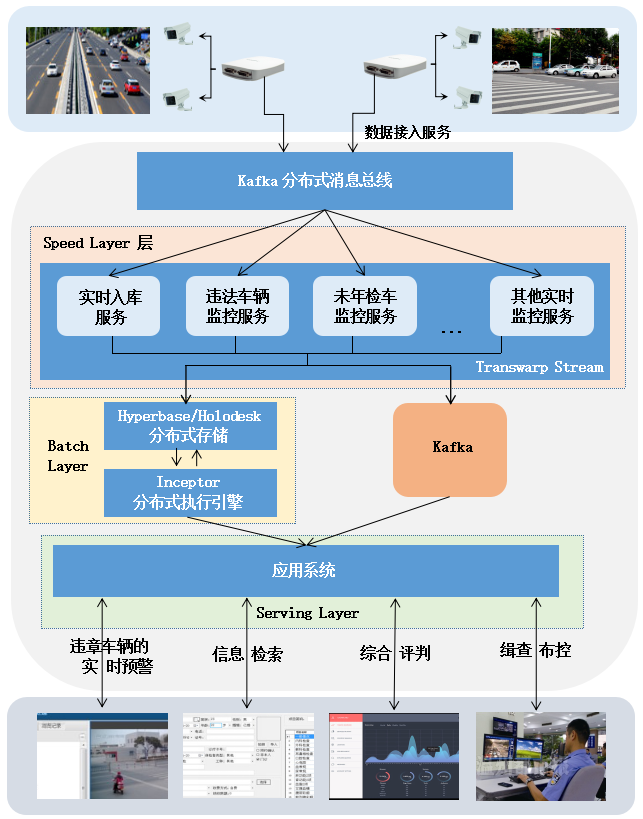 智能交通的整体架构图
智能交通的整体架构图
前端卡口会实时采集过往车辆信息,采集到的车辆信息首先被接入Kafka分布式消息总线。Kafka分布式消息总线,会对这些数据进行归类分拣,分发给不同的服务集群,比如实时入库服务集群、未年检车监控服务集群等。
假设有部分数据被送入到了未年检车监控服务集群中,该集群需要将待检查车辆与车辆数据库进行数据比对。为了减少数据比对时间,该系统预先根据历史数据生成了未年检车辆数据库,由Batch Layer层的批处理引擎完成。待检查车辆只需与未年检车辆数据库进行在线比对即可,如果发现违章车辆,则进行标记显示,并进行预警。
- 系统支持链接文字的业务
a. 实时监控预警业务
实时监控预警业务主要由Speed Layer层的Transwarp Stream负责,按照技术可以分为以下三类:
1) ETL功能
将实时采集的过车数据,按照一定的清洗转化规则进行处理,转化成规范的记录后写入后端存储Hyperbase和 Holodesk。其中Hyperbase为持久化的列式存储,保存所有的历史过车数据;Holodesk为临时存储,提供高速的分析能力,可以保存一周以内的短期数据。
2) 实时检测业务
最简单的检测规则可以直接根据过车记录判断,例如凌晨2点到5点行驶的车辆;其次是和一些基础表进行比对的业务,例如黑名单车辆/未年检车辆检测,需要事先进行预查询,生成并保存相应的黑名单车辆表/未年检车辆表。
3) 实时分析业务
实时统计业务如流量统计,通常基于窗口技术实现。例如需要统计分钟流量、小时流量,可以设定一个长度为1分钟的滚动窗口,统计每分钟的流量,并基于分钟流量对小时流量进行更新。
b. 数据统计分析业务
1) 基于全量历史数据的统计分析
通过Inceptor组件能够对存储在Hyperbase中的数据使用SQL语句进行统计分析,比如统计一天的车流量,一个月的碰撞次数等。Hyperbase的Rowkey具有去重的功能,可以帮助用户得到精准的统计结果。
2) 基于临时数据的交互式分析
除了一些固定的统计报表之外,还需要处理一些突发的临时性统计业务。例如伴随车分析,就是统计出一段时间内和某个车一同行驶的车辆,这在犯罪分析中有很大的作用。TDH中的Holodesk组件能够很好处理这部分业务需求,创建Holodesk上的一张有窗口限制的表(例如窗口长度为1周,超过1周的数据将被删除),通过Transwarp Stream将数据实时写入Holodesk,前端通过Inceptor的SQL实现交互式分析。