免费开通大数据服务:https://www.aliyun.com/product/odps
介然(李金波),阿里云高级技术专家,现任阿里云大数据数仓解决方案总架构师。8年以上互联网数据仓库经历,对系统架构、数据架构拥有丰富的实战经验,曾经数据魔方、淘宝指数的数据架构设计专家。
与阿里云大数据数仓结缘
介然之前在一家软件公司给企业客户做软件开发和数仓开发实施,数仓开发和实施都是基于传统的基础架构。2008年加入阿里进入淘宝数据平台部后,他开始接触分布式计算平台Hadoop。
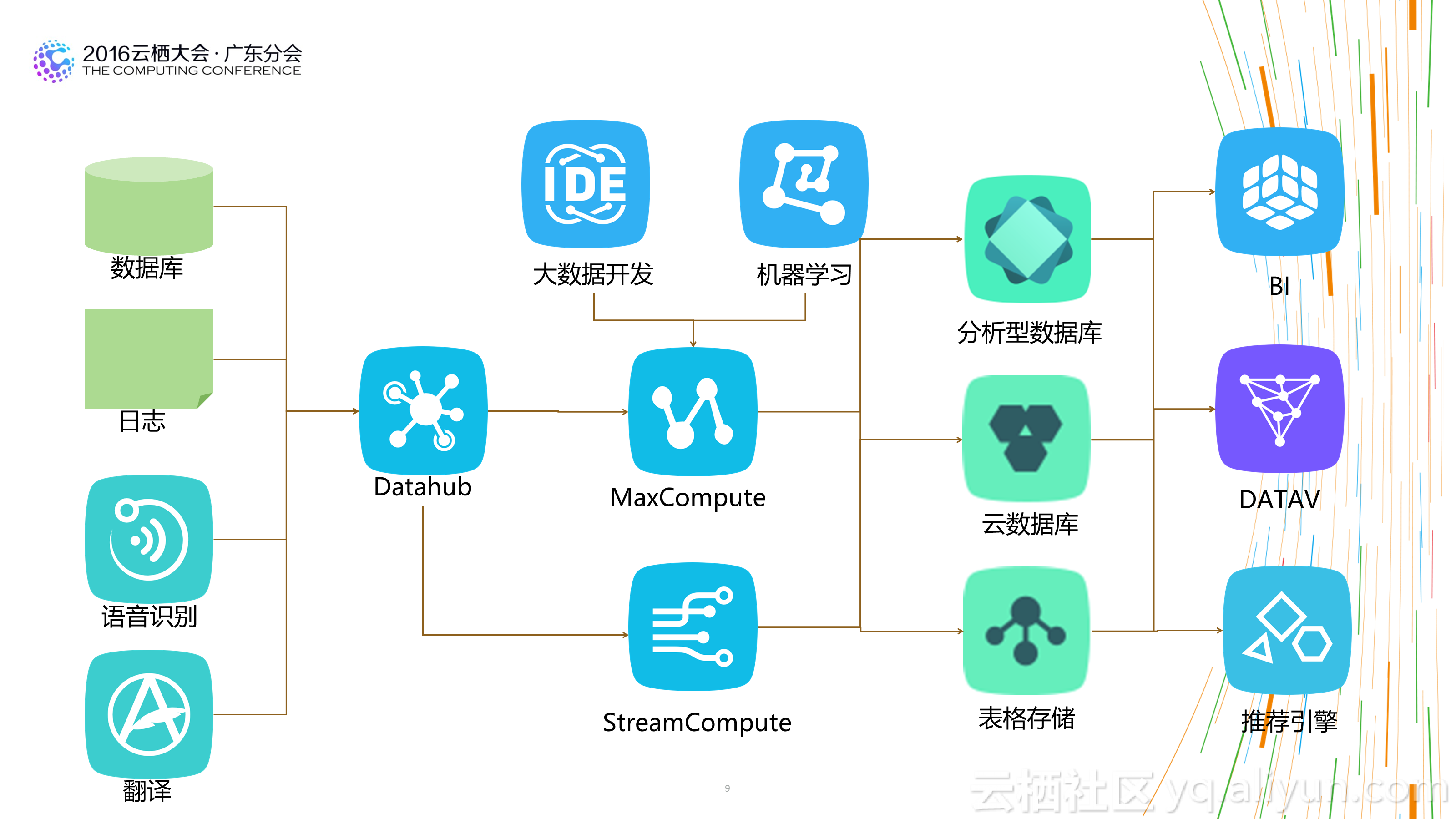
初始时在Hadoop平台上构建数仓主要解决企业内部数据分析的需求,在2010年公司决定对外开放数据后,开始于2011年利用自建的数仓体系支持对外数据产品数据魔方、淘宝指数。后续在平台和产品上不停的丰富数据内容,同时离线和流式两套数据体系支持数据产品。
从2012年开始,之前在Hadoop上的数据体系搬迁到阿里云数加MaxCompute(原ODPS),并完成了数据体系的重构,此时介然负责平台基础数据的建设支持全集团的上层数据应用。在2014年之后,公司开始对外服务,开始研究数据服务化和帮助外部用户如何利用阿里的平台实现大数据应用。
数仓上遇到的挑战:数据质量保障、稳定和重复性
在数据魔方、淘宝指数和阿里大数据数仓解决方案设计中,介然遇到了不少有挑战性的技术问题,主要集中在以下三点:
1.数据质量保障:随着业务的复杂度增加,数据源头的类型和数据量也会越来越多,经常会碰到某些数据源因为一些偶发的原因同步过来的数据质量出现问题。比如日志出现乱码、数据库因为切库造成数据同步量变少等等。这就要求在整个数仓体系的搭建过程中不只要完成数据业务逻辑的处理,还需要增加数据质量的监控。“我们在核心的数据处理流程中,增加数据质量监控代码,如果碰到数据量的突变或者核心指标的突变,会将数据处理流程暂停并预警,让数据运维人员处理数据质量问题后再进行后续数据流程的运行,保障有质量问题的数据不流到下游应用中。”
2.数据产出稳定性保障:随着数据量的增加、计算资源的逐渐饱和,业务数据最终产出的时间开始延迟,并有可能不能按照业务要求的时间点产出。“这个时候我们会分析数据产出的关键路径,找出关键路径下消耗时间最多的运行JOB,通过数据模型优化、计算任务拆解或者计算任务代码优化的手段减少任务产出的时间,同时保障整体产出时间满足预期。”
3.重复的数据处理代码:由于业务的特殊性,会对某种类型的数据加工操作需求非常多。比如计算交易中,TOP N的商家、TOP N 的品牌、TOP N的商品,商家中TOP N的商品、品牌中TOP N的商家等等。 这类代码都是非常类似的,如果每个计算都独立任务,会造成计算资源的大量浪费。“我们通过特殊的代码框架,让一份基础数据中多种TOPN的数据可以在一次计算过程中产出,大大减少资源消耗,保障数据产出稳定。”
优秀数仓的三要素:清晰、保障和扩展性好
介然认为,优秀的数据仓库应该包含以下要素:
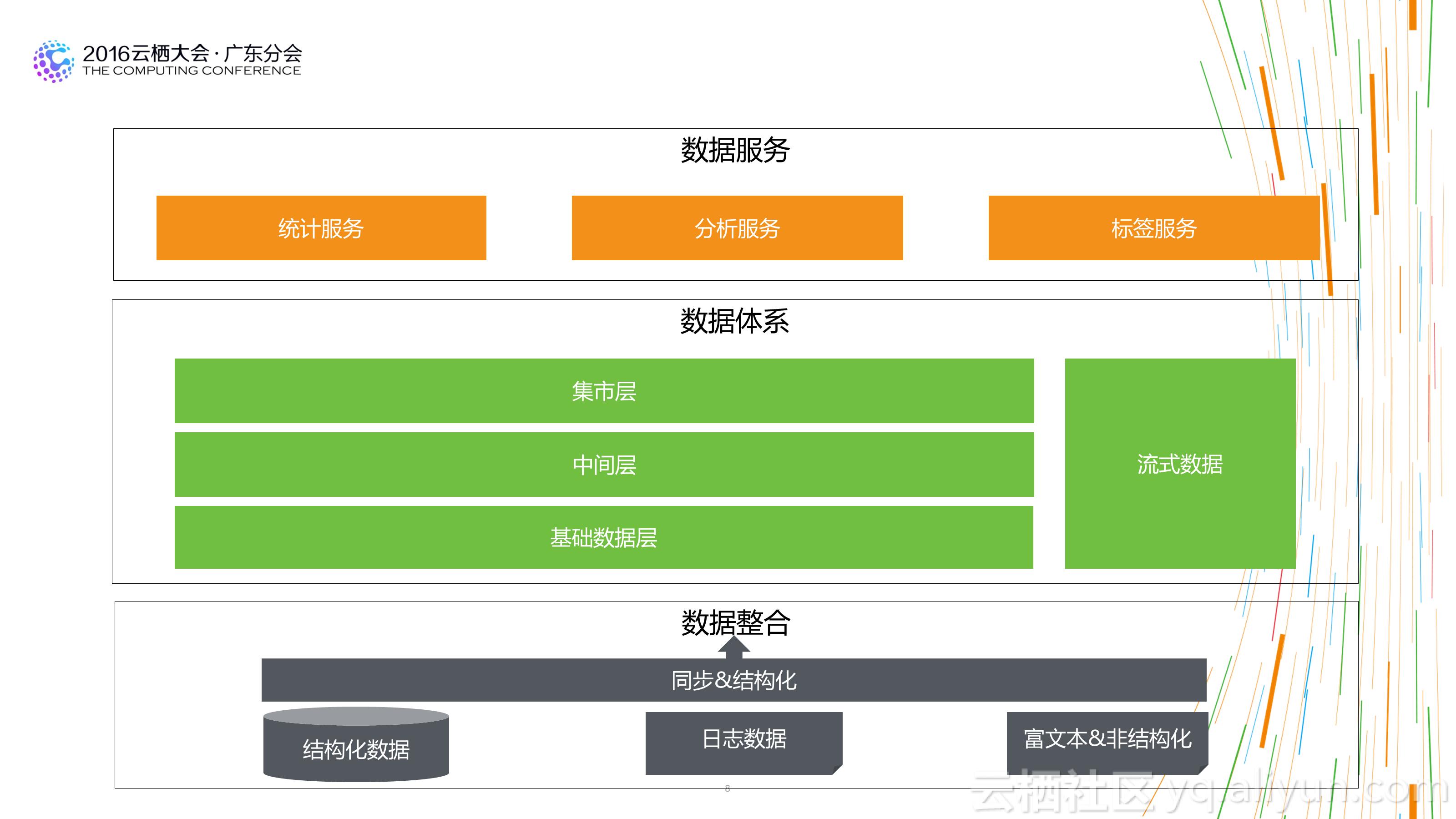
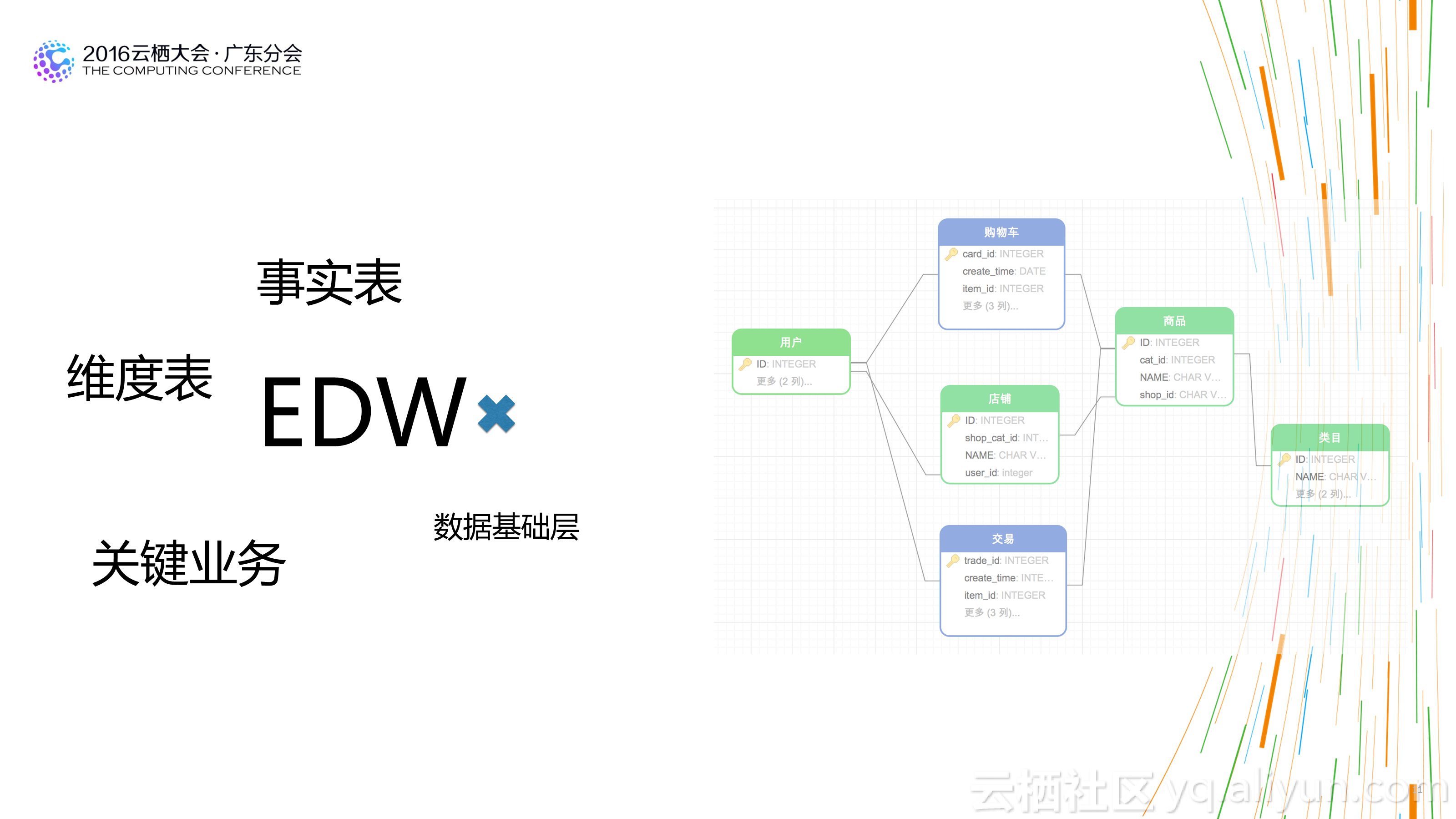
1.结构、分层清晰:不一定需要多少个分层和主题,但是一定要清晰。用数据的人能够很快找到需要数据的位置。
2.数据质量和产出时间有保障;
3.扩展性好:不会因为业务的些许变化造成模型的大面积重构。
而从系统架构、数据架构两个纬度来看,要想设计好大数据应用下的数据仓库,还应做到以下两点。
1.系统架构上:足够的容错性,减少不必要的系统间的强耦合。因为你会碰到各种问题,不要因为一个不必要的依赖造成数据无法产出。
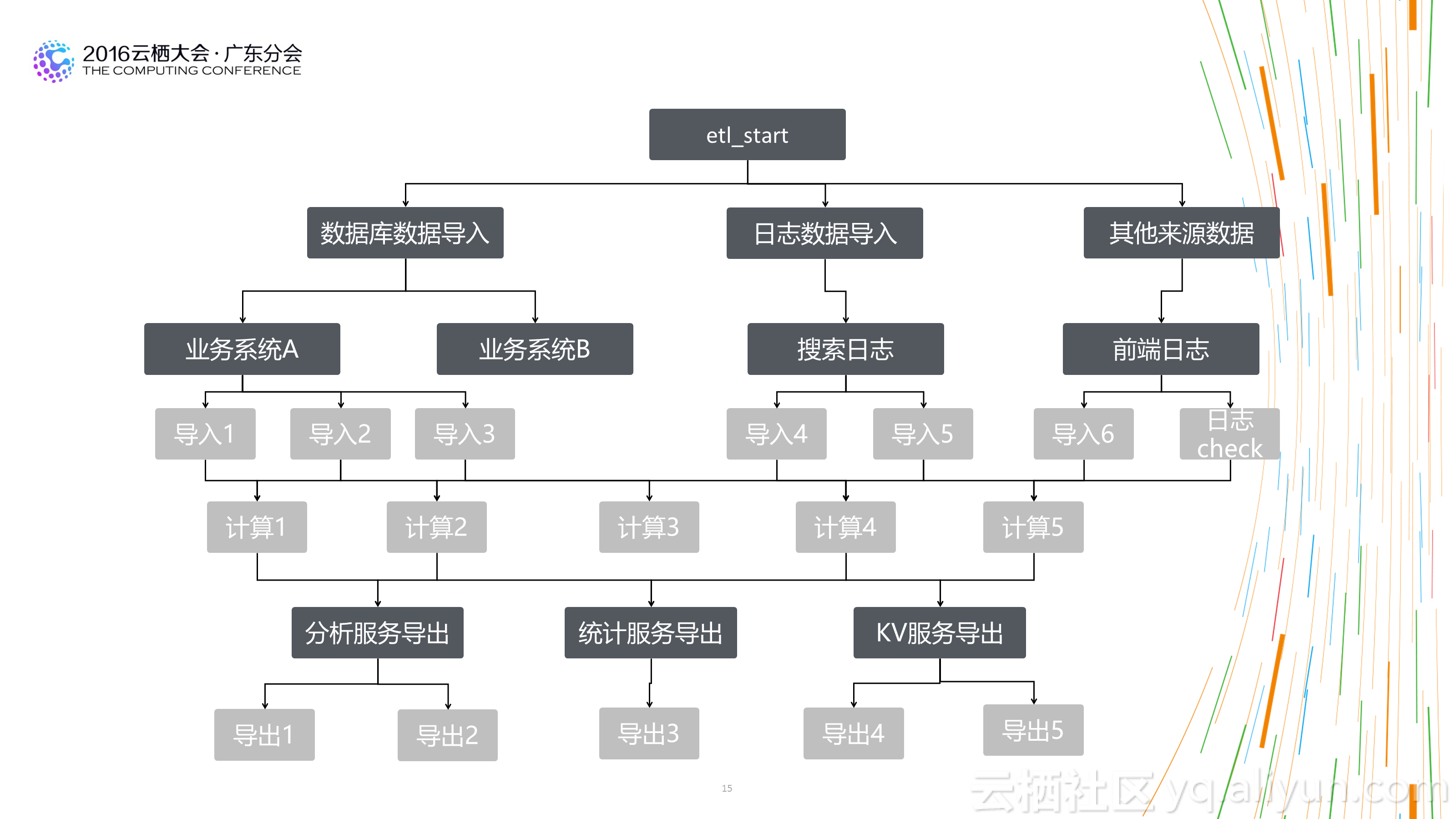
2.数据架构上:简单、清晰、强质量控制。数据架构上扁平化的数据处理流程会对数据质量的控制和数据产出的稳定性提供非常好的基础。
互联网人转型做大数据数仓需要注意哪几个点?
对于之前做互联网数据仓库,现在想转型做大数据仓库的人,介然也提了一些建议,主要是四点:
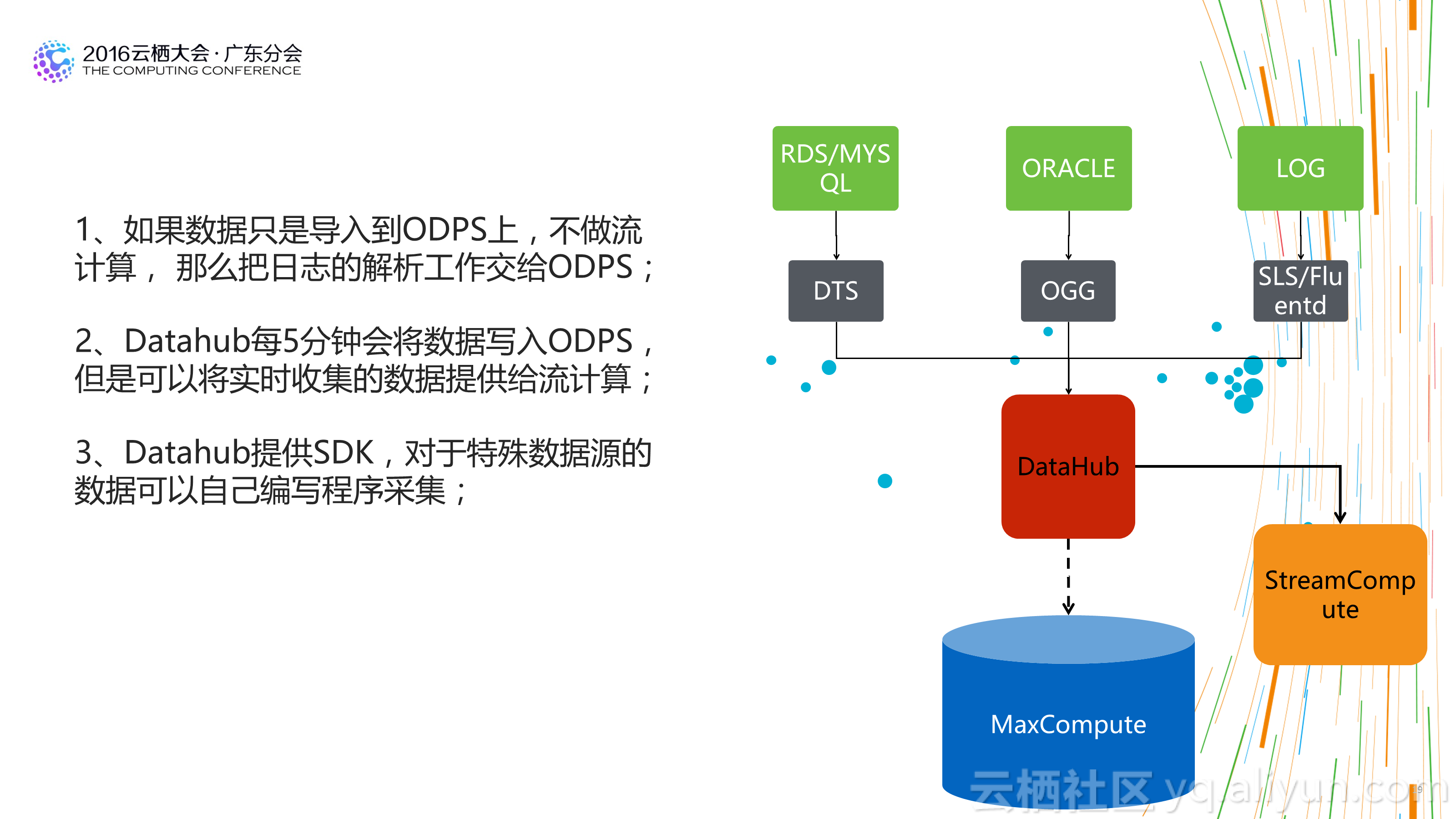
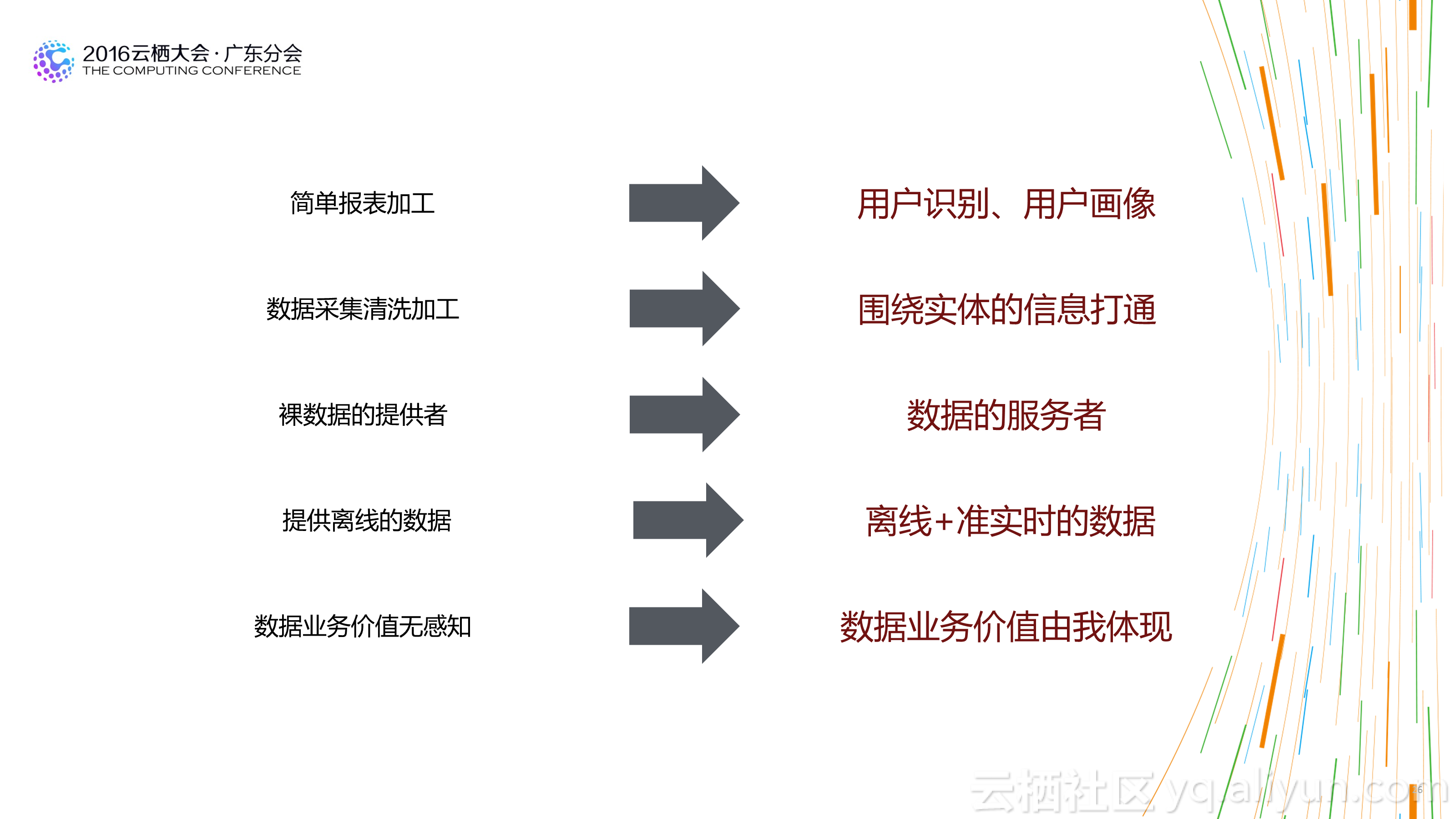
1.不必再苛刻的精打细算:基于传统平台构建数仓时,为了照顾平台的处理能力,我们经常会构建多层数据结构,预先对不同粒度的数据做预先汇总,以方便使用者在使用数据时能够已最小的计算代价获得计算结果。这也造成了整个数据处理流程较长,步骤很多,问题追溯困难。 新的大数据仓库基于分布式计算平台,平台的计算能力通常都比传统的平台强大很多。 所以有时候需要时再计算数据,或者基于明细进行各粒度的数据汇总已经能够满足需求,并能够大大减少整体数据处理流程步骤,用计算的代价减少人工的成本,更划算,数据体系也更健壮。
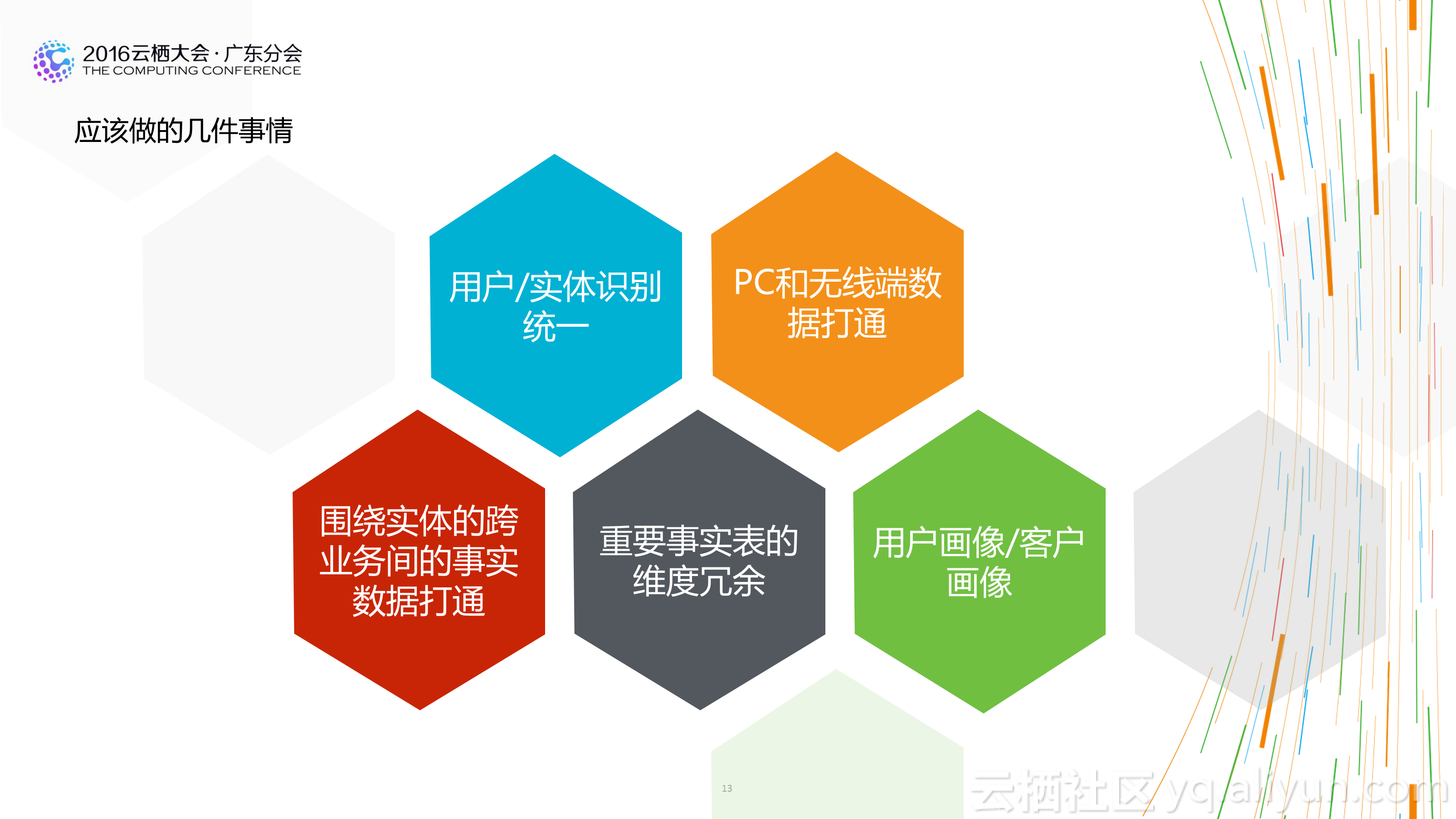
2.不是模型层次越多越好:在传统的数仓架构中,大家都喜欢多数据模型进行分层设计,不同的模型层次拥有不同的数据域和作用域。这样设计固然看起来更清晰,但实际情况时多层之间可能存在重复数据,或者数据使用者在上层找不到完全切合的数据时,更愿意从底层的明细数据上自己去加工。一方面造成了数据使用上的混乱,一方面也会让数据整个处理流程长度增加,对于数据的运维带来较大的成本消耗。合理的层次设计,及在计算成本和人力成本间的平衡,是一个好的数仓架构的表现。
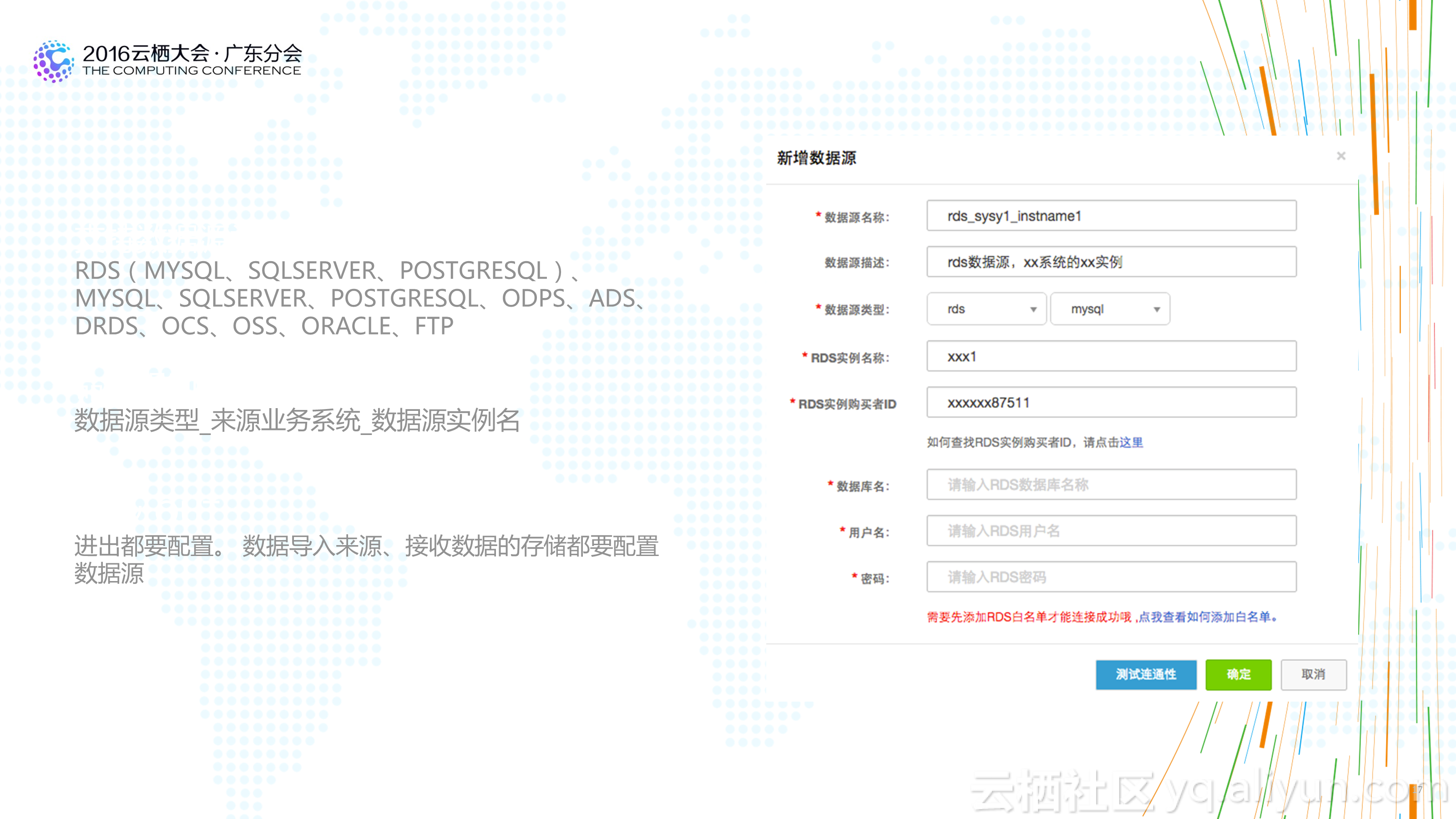
3.质量是生命线:不再是你拿到的数据都是正确的,新的环境下的数据什么情况都会发生,而好的数仓架构需要有足够的容错性和质量保障。不要因为一条日志的乱码造成整个数据流程无法走通,也不要说一份日志50%的乱码你的程序还发现不了。在数据质量上投入再多的资源都不是浪费。
4.数据变成生产资料:传统的数据应用绝大部分都是以报表和BI分析的形式支持业务。也许你的报表晚出来会被老板骂一通,但是对业务的影响并不大。 但是在新的数据应用场景下,数据已经变成生产资料,数据会服务化直接应用到业务系统中,也许一份数据的质量出现问题或者产出延迟,都可能对你的业务系统产生致命的影响。所以数仓开始承担新的使命。
如果你依然迷惑,欢迎来听听阿里是如何搭建一个好的数据仓库
介然称,本次分享会讲:在大数据的应用场景下,基于新的分布式计算平台的特征如何设计数据仓库。“会从应用需求、平台的特征、模型的设计、产品的应用几个角度来说明如何在阿里大数据平台下搭建一个好的数据仓库。”对于细节,他介绍到。
这位阿里云大数据数仓解决方案总架构师,非常希望大家来听本次分享:“不管你在什么平台上做过数据开发,或者公司开始做大数据应用,只要利用平台支持这个应用,都欢迎来一起讨论。”
精彩分享