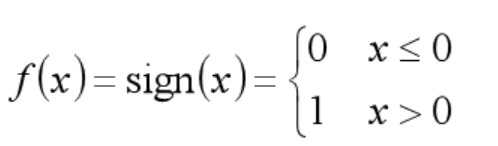1 sigmoid 函数的损失函数与参数更新
逻辑回归对应线性回归,但旨在解决分类问题,即将模型的输出转换为 [0,1] 的概率值。逻辑回归直接对分类的可能性进行建模,无需事先假设数据的分布。最理想的转换函数为单位阶跃函数(也称 Heaviside 函数),但单位阶跃函数是不连续的,没法在实际计算中使用。故而,在分类过程中更常使用对数几率函数(即 sigmoid 函数):
σ(x)=11+e−x
易推知,σ(x)′=σ(x)(1−σ(x)).
假设我们有 m 个样本 D={(xi,yi)}mi, 令 X=(x1,x2,⋯,xm)T,y=(y1,y2,⋯,ym)T, 其中 xi∈Rn,yi∈{0,1}, 关于参数 w∈Rn,b∈R, (b 需要广播操作),我们定义正例的概率为
P(yj=1|xj;w,b)=σ(xTjw+b)=σ(zj)
这样属于类别 y 的概率可改写为
P(yj|xj;w,b)=σ(zj)yj(1−σ(zj))1−yj
令 z=(z1,⋯,zm)T, 则记 h(z)=(σ(z1),⋯,σ(zm))T, 且 Logistic Regression 的损失函数为
L(w,b)=−1mm∑i=1(yilog(σ(zi))+(1−yi)log(1−σ(zi)))=−1m(yTlog(h(z))+(1−y)Tlog(1−h(z))), 此时做了广播操作
这样,我们有
{∇wL(w,b)=dzdwdLdz=−1mXT(y−h(z))∇bL(w,b)=dzdbdLdz=−1m1T(y−h(z))
其中,1 表示全一列向量。这样便有参数更新公式 (η 为学习率):
{w←w−η∇wL(w,b)b←b−η∇bL(w,b)
更多机器学习中的数见:机器学习中的数学