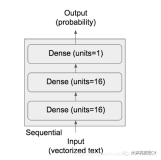
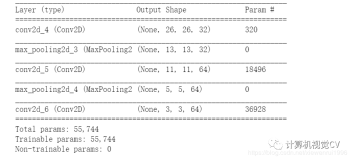
Backend 切换
编辑 .keras/keras.json 即可。可选后端有 theano 和 tensorflow.
theano 版本配置如下:
$ vim ~/.keras/keras.json
{
"image_dim_ordering": "th",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "theano"
}
tensorflow 版本配置如下:
$ vim ~/.keras/keras.json
{
"image_dim_ordering": "tf",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "tensorflow"
}
NVIDIA Cuda 8 安装
cuda 历史版本安装
https://developer.nvidia.com/cuda-toolkit-archive
cudnn 历史版本
https://developer.nvidia.com/rdp/cudnn-archive
当前是由于windows下的TensorFlow只支持 cuda8, 而当前官网直接下载到的是cuda9, 没办法只能找老版本的安装
最终效果如下所示:
Using TensorFlow backend.
2017-12-30 09:25:09.107257: I C:\tf_jenkins\home\workspace\rel-win\M\windows-gpu\PY\36\tensorflow\core\platform\cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
2017-12-30 09:25:09.763864: I C:\tf_jenkins\home\workspace\rel-win\M\windows-gpu\PY\36\tensorflow\core\common_runtime\gpu\gpu_device.cc:1030] Found device 0 with properties:
name: GeForce GTX 960M major: 5 minor: 0 memoryClockRate(GHz): 1.176
pciBusID: 0000:01:00.0
totalMemory: 2.00GiB freeMemory: 1.65GiB
2017-12-30 09:25:09.763992: I C:\tf_jenkins\home\workspace\rel-win\M\windows-gpu\PY\36\tensorflow\core\common_runtime\gpu\gpu_device.cc:1120] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: GeForce GTX 960M, pci bus id: 0000:01:00.0, compute capability: 5.0)
当前使用的笔记本是独立显卡, GeForce GTX 960M 显卡,安装 anaconda, keras, TensorFlow-gpu, 按照上述配置为 tensorflow 为 keras后端,并通过 cuda8 做 tensorflow 的执行引擎,从而进入最大化烧显卡时代咯;-)...
TensorBoard 使用
在调试过程中需要查看训练状态,直接从日志能看出一些内容,但我们需要更多信息来判定是否是过拟合,还是网络能力不够等,这时可以通过 tensorboard 查看 keras 训练过程。方法如下
from keras.callbacks import TensorBoard
from keras.models import Sequential
# model
model = Sequential()
callback = keras.callbacks.TensorBoard(log_dir='log', write_images=1, histogram_freq=1)
# ...
model.fit(x_train, x_train,
epochs=50,
batch_size=128,
shuffle=True,
validation_data=(x_test, x_test),
callbacks=[callback])
当然也可简单的进行如下操作
# model
model = Sequential()
# ...
model.fit(x_train, x_train,
epochs=50,
batch_size=128,
shuffle=True,
validation_data=(x_test, x_test),
callbacks=[TensorBoard(log_dir='log')])
这时候仅需要启动 anaconda 命令行模式,执行如下命令即可在浏览器中查看训练状态
$ tensorboard --logdir='<path>/log'
TensorBoard 0.4.0rc3 at http://localhost:6006 (Press CTRL+C to quit)
这时候就能在浏览器中查看到训练到当前epoch时loss等状态了
多 CPU, GPU运行 keras
通过如下命令查看 CPU 数量
# 总核数 = 物理CPU个数 X 每颗物理CPU的核数
# 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
# 查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
# 查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l
# 查看core信息描述
# sudo dmidecode -t 4 | egrep -i "Designation|Intel|core|thread"
# 查看GPU信息
# lspci | grep VGA
# 查看是否安装 NVidia显卡
# lspci | grep -i nvidia
使用 tensorflow 运行在多 CPU 和多 GPU 上设置, 此次的配置即是对GPU及CPU数量进行允许也是一种限制:
import tensorflow as tf
from keras import backend as K
# intra_op_parallelism_threads 控制运算符op内部的并行
# inter_op_parallelism_threads 控制多个运算符op之间的并行计算
# * device_count, 告诉tf Session使用CPU数量上限,如果你的CPU数量较多,可以适当加大这个值
# * inter_op_parallelism_threads和intra_op_parallelism_threads告诉session操作的线程并行程度,如果值越小,线程的复用就越少,越可能使用较多的CPU核数。如果值为0,TF会自动选择一个合适的值。
with tf.Session(config=tf.ConfigProto(device_count = {'GPU': 0 , 'CPU': 20}, inter_op_parallelism_threads=1, intra_op_parallelism_threads=20, log_device_placement=True)) as sess:
K.set_session(sess)
对于 ConfigProto 可配置项可参见其 proto 文件,
在 theano中使用如下方式来实现:
import os
os.environ['MKL_NUM_THREADS'] = '16'
os.environ['GOTO_NUM_THREADS'] = '16'
os.environ['OMP_NUM_THREADS'] = '16'
os.eviron['openmp'] = 'True'
参考:
multi-core-cpu
Tensorflow并行:多核(multicore),多线程(multi-thread)
指定GPU 运行 CUDA
指定 GPU 运行:
# CUDA_VISIBLE_DEVICES=1 Only device 1 will be seen
# CUDA_VISIBLE_DEVICES=0,1 Devices 0 and 1 will be visible
# CUDA_VISIBLE_DEVICES="0,1" Same as above, quotation marks are optional
# CUDA_VISIBLE_DEVICES=0,2,3 Devices 0, 2, 3 will be visible; device 1 is masked
# CUDA_VISIBLE_DEVICES="" No GPU will be visible
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
通过对环境变量的修改来控制当前session中可看到的gpu编号
tensorflow 中指定内存使用大小:
# 限定大小(按比例限定)
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.7)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
# 按需分配
gpu_options = tf.GPUOptions(allow_growth=True)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))