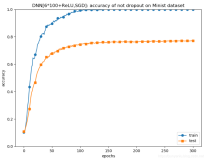
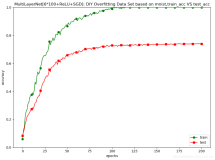
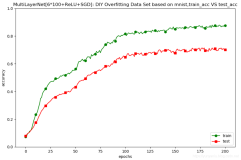
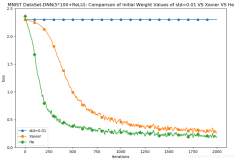
在 kaldi 训练过程中,DNN 的训练是依赖于 GMM-HMM 模型的,通过 GMM-HMM 模型得到 DNN 声学模型的输出结果(在 get_egs.sh 脚本中可以看到这一过程)。因此训练一个好的 GMM-HMM 模型是 kaldi 语音识别的关键。
为了理解 DNN 训练的过程,这里以 aishell 为例,从 run.sh 进行解析
#!/bin/bash
# Copyright 2017 Beijing Shell Shell Tech. Co. Ltd. (Authors: Hui Bu)
# 2017 Jiayu Du
# 2017 Xingyu Na
# 2017 Bengu Wu
# 2017 Hao Zheng
# Apache 2.0
# This is a shell script, but it's recommended that you run the commands one by
# one by copying and pasting into the shell.
# Caution: some of the graph creation steps use quite a bit of memory, so you
# should run this on a machine that has sufficient memory.
data=/export/a05/xna/data
data_url=www.openslr.org/resources/33
. ./cmd.sh
local/download_and_untar.sh $data $data_url data_aishell || exit 1;
local/download_and_untar.sh $data $data_url resource_aishell || exit 1;
# Lexicon Preparation,
local/aishell_prepare_dict.sh $data/resource_aishell || exit 1;
# Data Preparation,
local/aishell_data_prep.sh $data/data_aishell/wav $data/data_aishell/transcript || exit 1;
# Phone Sets, questions, L compilation
utils/prepare_lang.sh --position-dependent-phones false data/local/dict \
"<SPOKEN_NOISE>" data/local/lang data/lang || exit 1;
# LM training
local/aishell_train_lms.sh || exit 1;
# G compilation, check LG composition
utils/format_lm.sh data/lang data/local/lm/3gram-mincount/lm_unpruned.gz \
data/local/dict/lexicon.txt data/lang_test || exit 1;
# Now make MFCC plus pitch features.
# mfccdir should be some place with a largish disk where you
# want to store MFCC features.
mfccdir=mfcc
for x in train dev test; do
steps/make_mfcc_pitch.sh --cmd "$train_cmd" --nj 10 data/$x exp/make_mfcc/$x $mfccdir || exit 1;
steps/compute_cmvn_stats.sh data/$x exp/make_mfcc/$x $mfccdir || exit 1;
utils/fix_data_dir.sh data/$x || exit 1;
done
# 训练单音HMM模型
steps/train_mono.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/mono || exit 1;
# Monophone decoding
utils/mkgraph.sh data/lang_test exp/mono exp/mono/graph || exit 1;
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/mono/graph data/dev exp/mono/decode_dev
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/mono/graph data/test exp/mono/decode_test
# Get alignments from monophone system.
steps/align_si.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/mono exp/mono_ali || exit 1;
# 训练与上下文相关的三音 HMM 模型
# train tri1 [first triphone pass]
steps/train_deltas.sh --cmd "$train_cmd" \
2500 20000 data/train data/lang exp/mono_ali exp/tri1 || exit 1;
# decode tri1
utils/mkgraph.sh data/lang_test exp/tri1 exp/tri1/graph || exit 1;
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/tri1/graph data/dev exp/tri1/decode_dev
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/tri1/graph data/test exp/tri1/decode_test
# align tri1
steps/align_si.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/tri1 exp/tri1_ali || exit 1;
# train tri2 [delta+delta-deltas]
steps/train_deltas.sh --cmd "$train_cmd" \
2500 20000 data/train data/lang exp/tri1_ali exp/tri2 || exit 1;
# decode tri2
utils/mkgraph.sh data/lang_test exp/tri2 exp/tri2/graph
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/tri2/graph data/dev exp/tri2/decode_dev
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/tri2/graph data/test exp/tri2/decode_test
# train and decode tri2b [LDA+MLLT]
steps/align_si.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/tri2 exp/tri2_ali || exit 1;
# 进行线性判别分析(LDA)和最大似然线性转换(MLLT)
# Train tri3a, which is LDA+MLLT,
steps/train_lda_mllt.sh --cmd "$train_cmd" \
2500 20000 data/train data/lang exp/tri2_ali exp/tri3a || exit 1;
utils/mkgraph.sh data/lang_test exp/tri3a exp/tri3a/graph || exit 1;
steps/decode.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri3a/graph data/dev exp/tri3a/decode_dev
steps/decode.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri3a/graph data/test exp/tri3a/decode_test
# From now, we start building a more serious system (with SAT), and we'll
# do the alignment with fMLLR.
steps/align_fmllr.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/tri3a exp/tri3a_ali || exit 1;
# 训练发音人自适应,基于特征空间最大似然线性回归
steps/train_sat.sh --cmd "$train_cmd" \
2500 20000 data/train data/lang exp/tri3a_ali exp/tri4a || exit 1;
utils/mkgraph.sh data/lang_test exp/tri4a exp/tri4a/graph
steps/decode_fmllr.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri4a/graph data/dev exp/tri4a/decode_dev
steps/decode_fmllr.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri4a/graph data/test exp/tri4a/decode_test
steps/align_fmllr.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/tri4a exp/tri4a_ali
# Building a larger SAT system.
steps/train_sat.sh --cmd "$train_cmd" \
3500 100000 data/train data/lang exp/tri4a_ali exp/tri5a || exit 1;
utils/mkgraph.sh data/lang_test exp/tri5a exp/tri5a/graph || exit 1;
steps/decode_fmllr.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri5a/graph data/dev exp/tri5a/decode_dev || exit 1;
steps/decode_fmllr.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri5a/graph data/test exp/tri5a/decode_test || exit 1;
# 将特征向量进行gmm-est-fmllr并gmm-align-compiled对齐操作
steps/align_fmllr.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/tri5a exp/tri5a_ali || exit 1;
# nnet3
local/nnet3/run_tdnn.sh
# chain
local/chain/run_tdnn.sh
# getting results (see RESULTS file)
for x in exp/*/decode_test; do [ -d $x ] && grep WER $x/cer_* | utils/best_wer.sh; done 2>/dev/null
exit 0;
从上述的注释来看, GMM-HMM 训练了 5 次,得到一个相对比较不错的模型,然后训练 nnet3 模型以及 chain 模型,最后测试精度。
在 local/nnet3/run_tdnn.sh 脚本中
#!/bin/bash
# This script is based on swbd/s5c/local/nnet3/run_tdnn.sh
# this is the standard "tdnn" system, built in nnet3; it's what we use to
# call multi-splice.
# At this script level we don't support not running on GPU, as it would be painfully slow.
# If you want to run without GPU you'd have to call train_tdnn.sh with --gpu false,
# --num-threads 16 and --minibatch-size 128.
set -e
stage=0
train_stage=-10
affix=
common_egs_dir=
# training options
initial_effective_lrate=0.0015
final_effective_lrate=0.00015
num_epochs=4
num_jobs_initial=2
num_jobs_final=12
remove_egs=true
# feature options
use_ivectors=true
# End configuration section.
. ./cmd.sh
. ./path.sh
. ./utils/parse_options.sh
if ! cuda-compiled; then
cat <<EOF && exit 1
This script is intended to be used with GPUs but you have not compiled Kaldi with CUDA
If you want to use GPUs (and have them), go to src/, and configure and make on a machine
where "nvcc" is installed.
EOF
fi
dir=exp/nnet3/tdnn_sp${affix:+_$affix}
# 这里设置GMM输入参数目录
gmm_dir=exp/tri5a
train_set=train_sp
# 对齐后的特征集合目录
ali_dir=${gmm_dir}_sp_ali
graph_dir=$gmm_dir/graph
local/nnet3/run_ivector_common.sh --stage $stage || exit 1;
if [ $stage -le 7 ]; then
echo "$0: creating neural net configs";
num_targets=$(tree-info $ali_dir/tree |grep num-pdfs|awk '{print $2}')
# kaldi DNN 网络配置
mkdir -p $dir/configs
cat <<EOF > $dir/configs/network.xconfig
input dim=100 name=ivector
input dim=43 name=input
# please note that it is important to have input layer with the name=input
# as the layer immediately preceding the fixed-affine-layer to enable
# the use of short notation for the descriptor
fixed-affine-layer name=lda input=Append(-2,-1,0,1,2,ReplaceIndex(ivector, t, 0)) affine-transform-file=$dir/configs/lda.mat
# the first splicing is moved before the lda layer, so no splicing here
relu-batchnorm-layer name=tdnn1 dim=850
relu-batchnorm-layer name=tdnn2 dim=850 input=Append(-1,0,2)
relu-batchnorm-layer name=tdnn3 dim=850 input=Append(-3,0,3)
relu-batchnorm-layer name=tdnn4 dim=850 input=Append(-7,0,2)
relu-batchnorm-layer name=tdnn5 dim=850 input=Append(-3,0,3)
relu-batchnorm-layer name=tdnn6 dim=850
output-layer name=output input=tdnn6 dim=$num_targets max-change=1.5
EOF
# 将 网络配置转换为 nnet3 网络配置文件
steps/nnet3/xconfig_to_configs.py --xconfig-file $dir/configs/network.xconfig --config-dir $dir/configs/
fi
if [ $stage -le 8 ]; then
if [[ $(hostname -f) == *.clsp.jhu.edu ]] && [ ! -d $dir/egs/storage ]; then
utils/create_split_dir.pl \
/export/b0{5,6,7,8}/$USER/kaldi-data/egs/aishell-$(date +'%m_%d_%H_%M')/s5/$dir/egs/storage $dir/egs/storage
fi
# 执行 train_dnn.py 来对 feats 内容进行训练
steps/nnet3/train_dnn.py --stage=$train_stage \
--cmd="$decode_cmd" \
--feat.online-ivector-dir exp/nnet3/ivectors_${train_set} \
--feat.cmvn-opts="--norm-means=false --norm-vars=false" \
--trainer.num-epochs $num_epochs \
--trainer.optimization.num-jobs-initial $num_jobs_initial \
--trainer.optimization.num-jobs-final $num_jobs_final \
--trainer.optimization.initial-effective-lrate $initial_effective_lrate \
--trainer.optimization.final-effective-lrate $final_effective_lrate \
--egs.dir "$common_egs_dir" \
--cleanup.remove-egs $remove_egs \
--cleanup.preserve-model-interval 500 \
--use-gpu true \
--feat-dir=data/${train_set}_hires \
--ali-dir $ali_dir \
--lang data/lang \
--reporting.email="$reporting_email" \
--dir=$dir || exit 1;
fi
if [ $stage -le 9 ]; then
# this version of the decoding treats each utterance separately
# without carrying forward speaker information.
for decode_set in dev test; do
num_jobs=`cat data/${decode_set}_hires/utt2spk|cut -d' ' -f2|sort -u|wc -l`
decode_dir=${dir}/decode_$decode_set
steps/nnet3/decode.sh --nj $num_jobs --cmd "$decode_cmd" \
--online-ivector-dir exp/nnet3/ivectors_${decode_set} \
$graph_dir data/${decode_set}_hires $decode_dir || exit 1;
done
fi
wait;
exit 0;
这里进入到 train_tdnn.py 中可以看到如下内容:
# 训练主函数
def train(args, run_opts):
""" The main function for training.
Args:
args: a Namespace object with the required parameters
obtained from the function process_args()
run_opts: RunOpts object obtained from the process_args()
"""
arg_string = pprint.pformat(vars(args))
logger.info("Arguments for the experiment\n{0}".format(arg_string))
# Copy phones.txt from ali-dir to dir. Later, steps/nnet3/decode.sh will
# use it to check compatibility between training and decoding phone-sets.
shutil.copy('{0}/phones.txt'.format(args.ali_dir), args.dir)
# 参数数据准备
# Set some variables.
# num_leaves = common_lib.get_number_of_leaves_from_tree(args.ali_dir)
num_jobs = common_lib.get_number_of_jobs(args.ali_dir)
feat_dim = common_lib.get_feat_dim(args.feat_dir)
ivector_dim = common_lib.get_ivector_dim(args.online_ivector_dir)
ivector_id = common_lib.get_ivector_extractor_id(args.online_ivector_dir)
# split the training data into parts for individual jobs
# we will use the same number of jobs as that used for alignment
common_lib.execute_command("utils/split_data.sh {0} {1}".format(
args.feat_dir, num_jobs))
shutil.copy('{0}/tree'.format(args.ali_dir), args.dir)
with open('{0}/num_jobs'.format(args.dir), 'w') as f:
f.write(str(num_jobs))
if args.input_model is None:
config_dir = '{0}/configs'.format(args.dir)
var_file = '{0}/vars'.format(config_dir)
variables = common_train_lib.parse_generic_config_vars_file(var_file)
else:
# If args.input_model is specified, the model left and right contexts
# are computed using input_model.
variables = common_train_lib.get_input_model_info(args.input_model)
# Set some variables.
try:
model_left_context = variables['model_left_context']
model_right_context = variables['model_right_context']
except KeyError as e:
raise Exception("KeyError {0}: Variables need to be defined in "
"{1}".format(str(e), '{0}/configs'.format(args.dir)))
left_context = model_left_context
right_context = model_right_context
# Initialize as "raw" nnet, prior to training the LDA-like preconditioning
# matrix. This first config just does any initial splicing that we do;
# we do this as it's a convenient way to get the stats for the 'lda-like'
# transform.
# 网络初始化
if (args.stage <= -5) and os.path.exists(args.dir+"/configs/init.config") and \
(args.input_model is None):
logger.info("Initializing a basic network for estimating "
"preconditioning matrix")
common_lib.execute_command(
"""{command} {dir}/log/nnet_init.log \
nnet3-init --srand=-2 {dir}/configs/init.config \
{dir}/init.raw""".format(command=run_opts.command,
dir=args.dir))
default_egs_dir = '{0}/egs'.format(args.dir)
if (args.stage <= -4) and args.egs_dir is None:
logger.info("Generating egs")
if args.feat_dir is None:
raise Exception("--feat-dir option is required if you don't supply --egs-dir")
# 调用 get_egs.sh 进行构建样本数据
train_lib.acoustic_model.generate_egs(
data=args.feat_dir, alidir=args.ali_dir, egs_dir=default_egs_dir,
left_context=left_context, right_context=right_context,
run_opts=run_opts,
frames_per_eg_str=str(args.frames_per_eg),
srand=args.srand,
egs_opts=args.egs_opts,
cmvn_opts=args.cmvn_opts,
online_ivector_dir=args.online_ivector_dir,
samples_per_iter=args.samples_per_iter,
stage=args.egs_stage)
if args.egs_dir is None:
egs_dir = default_egs_dir
else:
egs_dir = args.egs_dir
# 构建验证样本集合
[egs_left_context, egs_right_context,
frames_per_eg_str, num_archives] = (
common_train_lib.verify_egs_dir(egs_dir, feat_dim,
ivector_dim, ivector_id,
left_context, right_context))
assert str(args.frames_per_eg) == frames_per_eg_str
if args.num_jobs_final > num_archives:
raise Exception('num_jobs_final cannot exceed the number of archives '
'in the egs directory')
# copy the properties of the egs to dir for
# use during decoding
common_train_lib.copy_egs_properties_to_exp_dir(egs_dir, args.dir)
if args.stage <= -3 and os.path.exists(args.dir+"/configs/init.config") and (args.input_model is None):
logger.info('Computing the preconditioning matrix for input features')
train_lib.common.compute_preconditioning_matrix(
args.dir, egs_dir, num_archives, run_opts,
max_lda_jobs=args.max_lda_jobs,
rand_prune=args.rand_prune)
if args.stage <= -2 and (args.input_model is None):
logger.info("Computing initial vector for FixedScaleComponent before"
" softmax, using priors^{prior_scale} and rescaling to"
" average 1".format(
prior_scale=args.presoftmax_prior_scale_power))
common_train_lib.compute_presoftmax_prior_scale(
args.dir, args.ali_dir, num_jobs, run_opts,
presoftmax_prior_scale_power=args.presoftmax_prior_scale_power)
if args.stage <= -1:
logger.info("Preparing the initial acoustic model.")
train_lib.acoustic_model.prepare_initial_acoustic_model(
args.dir, args.ali_dir, run_opts,
input_model=args.input_model)
# set num_iters so that as close as possible, we process the data
# $num_epochs times, i.e. $num_iters*$avg_num_jobs) ==
# $num_epochs*$num_archives, where
# avg_num_jobs=(num_jobs_initial+num_jobs_final)/2.
num_archives_expanded = num_archives * args.frames_per_eg
num_archives_to_process = int(args.num_epochs * num_archives_expanded)
num_archives_processed = 0
num_iters = ((num_archives_to_process * 2)
/ (args.num_jobs_initial + args.num_jobs_final))
# If do_final_combination is True, compute the set of models_to_combine.
# Otherwise, models_to_combine will be none.
if args.do_final_combination:
models_to_combine = common_train_lib.get_model_combine_iters(
num_iters, args.num_epochs,
num_archives_expanded, args.max_models_combine,
args.num_jobs_final)
else:
models_to_combine = None
logger.info("Training will run for {0} epochs = "
"{1} iterations".format(args.num_epochs, num_iters))
for iter in range(num_iters):
if (args.exit_stage is not None) and (iter == args.exit_stage):
logger.info("Exiting early due to --exit-stage {0}".format(iter))
return
current_num_jobs = int(0.5 + args.num_jobs_initial
+ (args.num_jobs_final - args.num_jobs_initial)
* float(iter) / num_iters)
if args.stage <= iter:
# 获取 learning_rate
lrate = common_train_lib.get_learning_rate(iter, current_num_jobs,
num_iters,
num_archives_processed,
num_archives_to_process,
args.initial_effective_lrate,
args.final_effective_lrate)
shrinkage_value = 1.0 - (args.proportional_shrink * lrate)
if shrinkage_value <= 0.5:
raise Exception("proportional-shrink={0} is too large, it gives "
"shrink-value={1}".format(args.proportional_shrink,
shrinkage_value))
percent = num_archives_processed * 100.0 / num_archives_to_process
epoch = (num_archives_processed * args.num_epochs
/ num_archives_to_process)
shrink_info_str = ''
if shrinkage_value != 1.0:
shrink_info_str = 'shrink: {0:0.5f}'.format(shrinkage_value)
logger.info("Iter: {0}/{1} "
"Epoch: {2:0.2f}/{3:0.1f} ({4:0.1f}% complete) "
"lr: {5:0.6f} {6}".format(iter, num_iters - 1,
epoch, args.num_epochs,
percent,
lrate, shrink_info_str))
# 开始一次训练
train_lib.common.train_one_iteration(
dir=args.dir,
iter=iter,
srand=args.srand,
egs_dir=egs_dir,
num_jobs=current_num_jobs,
num_archives_processed=num_archives_processed,
num_archives=num_archives,
learning_rate=lrate,
dropout_edit_string=common_train_lib.get_dropout_edit_string(
args.dropout_schedule,
float(num_archives_processed) / num_archives_to_process,
iter),
train_opts=' '.join(args.train_opts),
minibatch_size_str=args.minibatch_size,
frames_per_eg=args.frames_per_eg,
momentum=args.momentum,
max_param_change=args.max_param_change,
shrinkage_value=shrinkage_value,
shuffle_buffer_size=args.shuffle_buffer_size,
run_opts=run_opts)
if args.cleanup:
# do a clean up everythin but the last 2 models, under certain
# conditions
common_train_lib.remove_model(
args.dir, iter-2, num_iters, models_to_combine,
args.preserve_model_interval)
if args.email is not None:
reporting_iter_interval = num_iters * args.reporting_interval
if iter % reporting_iter_interval == 0:
# lets do some reporting
[report, times, data] = (
nnet3_log_parse.generate_acc_logprob_report(args.dir))
message = report
subject = ("Update : Expt {dir} : "
"Iter {iter}".format(dir=args.dir, iter=iter))
common_lib.send_mail(message, subject, args.email)
num_archives_processed = num_archives_processed + current_num_jobs
if args.stage <= num_iters:
if args.do_final_combination:
logger.info("Doing final combination to produce final.mdl")
train_lib.common.combine_models(
dir=args.dir, num_iters=num_iters,
models_to_combine=models_to_combine,
egs_dir=egs_dir,
minibatch_size_str=args.minibatch_size, run_opts=run_opts,
max_objective_evaluations=args.max_objective_evaluations)
if args.stage <= num_iters + 1:
logger.info("Getting average posterior for purposes of "
"adjusting the priors.")
# If args.do_final_combination is true, we will use the combined model.
# Otherwise, we will use the last_numbered model.
real_iter = 'combined' if args.do_final_combination else num_iters
avg_post_vec_file = train_lib.common.compute_average_posterior(
dir=args.dir, iter=real_iter,
egs_dir=egs_dir, num_archives=num_archives,
prior_subset_size=args.prior_subset_size, run_opts=run_opts)
logger.info("Re-adjusting priors based on computed posteriors")
combined_or_last_numbered_model = "{dir}/{iter}.mdl".format(dir=args.dir,
iter=real_iter)
final_model = "{dir}/final.mdl".format(dir=args.dir)
train_lib.common.adjust_am_priors(args.dir, combined_or_last_numbered_model,
avg_post_vec_file, final_model, run_opts)
if args.cleanup:
logger.info("Cleaning up the experiment directory "
"{0}".format(args.dir))
remove_egs = args.remove_egs
if args.egs_dir is not None:
# this egs_dir was not created by this experiment so we will not
# delete it
remove_egs = False
# 清除网络数据
common_train_lib.clean_nnet_dir(
nnet_dir=args.dir, num_iters=num_iters, egs_dir=egs_dir,
preserve_model_interval=args.preserve_model_interval,
remove_egs=remove_egs)
# do some reporting
[report, times, data] = nnet3_log_parse.generate_acc_logprob_report(args.dir)
if args.email is not None:
common_lib.send_mail(report, "Update : Expt {0} : "
"complete".format(args.dir), args.email)
with open("{dir}/accuracy.report".format(dir=args.dir), "w") as f:
f.write(report)
common_lib.execute_command("steps/info/nnet3_dir_info.pl "
"{0}".format(args.dir))
在 get_egs.sh 脚本中,主要的内容如下所示:
# 获取 pdfs 数量
num_pdfs=$(tree-info --print-args=false $alidir/tree | grep num-pdfs | awk '{print $2}')
if [ $stage -le 3 ]; then
echo "$0: Getting validation and training subset examples."
rm $dir/.error 2>/dev/null
echo "$0: ... extracting validation and training-subset alignments."
# 分割样本数据
# do the filtering just once, as ali.scp may be long.
utils/filter_scp.pl <(cat $dir/valid_uttlist $dir/train_subset_uttlist) \
<$dir/ali.scp >$dir/ali_special.scp
# 通过 ali-to-pdf 以 GMM-HMM 输出模型为方法,将 alignments 特征转换为 pdf 并将其输入到 nnet3-get-egs 中与与特征进行合并为 NnetExample 对象并存放在文件中
$cmd $dir/log/create_valid_subset.log \
utils/filter_scp.pl $dir/valid_uttlist $dir/ali_special.scp \| \
ali-to-pdf $alidir/final.mdl scp:- ark:- \| \
ali-to-post ark:- ark:- \| \
nnet3-get-egs --num-pdfs=$num_pdfs --frame-subsampling-factor=$frame_subsampling_factor \
$ivector_opts $egs_opts "$valid_feats" \
ark,s,cs:- "ark:$dir/valid_all.egs" || touch $dir/.error &
$cmd $dir/log/create_train_subset.log \
utils/filter_scp.pl $dir/train_subset_uttlist $dir/ali_special.scp \| \
ali-to-pdf $alidir/final.mdl scp:- ark:- \| \
ali-to-post ark:- ark:- \| \
nnet3-get-egs --num-pdfs=$num_pdfs --frame-subsampling-factor=$frame_subsampling_factor \
$ivector_opts $egs_opts "$train_subset_feats" \
ark,s,cs:- "ark:$dir/train_subset_all.egs" || touch $dir/.error &
wait;
[ -f $dir/.error ] && echo "Error detected while creating train/valid egs" && exit 1
echo "... Getting subsets of validation examples for diagnostics and combination."
if $generate_egs_scp; then
valid_diagnostic_output="ark,scp:$dir/valid_diagnostic.egs,$dir/valid_diagnostic.scp"
train_diagnostic_output="ark,scp:$dir/train_diagnostic.egs,$dir/train_diagnostic.scp"
else
valid_diagnostic_output="ark:$dir/valid_diagnostic.egs"
train_diagnostic_output="ark:$dir/train_diagnostic.egs"
fi
$cmd $dir/log/create_valid_subset_combine.log \
nnet3-subset-egs --n=$[$num_valid_frames_combine/$frames_per_eg_principal] ark:$dir/valid_all.egs \
ark:$dir/valid_combine.egs || touch $dir/.error &
$cmd $dir/log/create_valid_subset_diagnostic.log \
nnet3-subset-egs --n=$[$num_frames_diagnostic/$frames_per_eg_principal] ark:$dir/valid_all.egs \
$valid_diagnostic_output || touch $dir/.error &
# 分割样本类型
$cmd $dir/log/create_train_subset_combine.log \
nnet3-subset-egs --n=$[$num_train_frames_combine/$frames_per_eg_principal] ark:$dir/train_subset_all.egs \
ark:$dir/train_combine.egs || touch $dir/.error &
$cmd $dir/log/create_train_subset_diagnostic.log \
nnet3-subset-egs --n=$[$num_frames_diagnostic/$frames_per_eg_principal] ark:$dir/train_subset_all.egs \
$train_diagnostic_output || touch $dir/.error &
wait
sleep 5 # wait for file system to sync.
cat $dir/valid_combine.egs $dir/train_combine.egs > $dir/combine.egs
if $generate_egs_scp; then
cat $dir/valid_combine.egs $dir/train_combine.egs | \
nnet3-copy-egs ark:- ark,scp:$dir/combine.egs,$dir/combine.scp
rm $dir/{train,valid}_combine.scp
else
cat $dir/valid_combine.egs $dir/train_combine.egs > $dir/combine.egs
fi
for f in $dir/{combine,train_diagnostic,valid_diagnostic}.egs; do
[ ! -s $f ] && echo "No examples in file $f" && exit 1;
done
rm $dir/valid_all.egs $dir/train_subset_all.egs $dir/{train,valid}_combine.egs
fi
通过查看 nnet3-get-egs.cc 文件, 其内容如下:
// 'input_frames' now stores the relevant rows (maybe with padding) from the
// original Matrix or (more likely) CompressedMatrix. If a CompressedMatrix,
// it does this without un-compressing and re-compressing, so there is no loss
// of accuracy.
NnetExample eg;
# 加入 input 输入内容
// call the regular input "input".
eg.io.push_back(NnetIo("input", -chunk.left_context, input_frames));
if (ivector_feats != NULL) {
// if applicable, add the iVector feature.
// choose iVector from a random frame in the chunk
int32 ivector_frame = RandInt(start_frame,
start_frame + num_input_frames - 1),
ivector_frame_subsampled = ivector_frame / ivector_period;
if (ivector_frame_subsampled < 0)
ivector_frame_subsampled = 0;
if (ivector_frame_subsampled >= ivector_feats->NumRows())
ivector_frame_subsampled = ivector_feats->NumRows() - 1;
Matrix<BaseFloat> ivector(1, ivector_feats->NumCols());
ivector.Row(0).CopyFromVec(ivector_feats->Row(ivector_frame_subsampled));
# 添加 ivector 声学特征向量
eg.io.push_back(NnetIo("ivector", 0, ivector));
}
// Note: chunk.first_frame and chunk.num_frames will both be
// multiples of frame_subsampling_factor.
int32 start_frame_subsampled = chunk.first_frame / frame_subsampling_factor,
num_frames_subsampled = chunk.num_frames / frame_subsampling_factor;
Posterior labels(num_frames_subsampled);
// TODO: it may be that using these weights is not actually helpful (with
// chain training, it was not), and that setting them all to 1 is better.
// We could add a boolean option to this program to control that; but I
// don't want to add such an option if experiments show that it is not
// helpful.
for (int32 i = 0; i < num_frames_subsampled; i++) {
int32 t = i + start_frame_subsampled;
if (t < pdf_post.size())
labels[i] = pdf_post[t];
for (std::vector<std::pair<int32, BaseFloat> >::iterator
iter = labels[i].begin(); iter != labels[i].end(); ++iter)
iter->second *= chunk.output_weights[i];
}
# 添加 output 输出结果
eg.io.push_back(NnetIo("output", num_pdfs, 0, labels, frame_subsampling_factor));
if (compress)
eg.Compress();