(本实验选用数据为真实电商脱敏数据,仅用于学习,请勿商用)
在上一期基于协同过滤的的推荐场景中,我们介绍了如何通过PAI快速搭建一个基于协同过滤方案的推荐系统,这一节会介绍一些如何基于推荐对象特征的推荐方法。
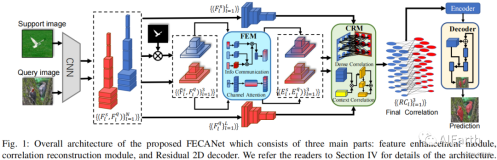
首先看下整个业务流程图,这是一个基于对象特征的推荐场景的通用流程:

- 首先把数据导入Maxcompute,有监督的结构化数据
- 接着做特征工程,在特征工程环节主要做一些数据的预处理以及特征的衍生,特征衍生的作用是扩充数据维度,使得数据能更大限度的表示业务特点
- 接着把数据通过拆分分成两份,一份通过分类算法生成二分类模型,另一份数据对模型效果进行测试
- 最后通过评估组件得到模型效果
一、业务场景描述
通过一份真实的电商数据的4、5月份做模型训练生成预测模型,通过6月份的购物数据对预测模型进行评估最终选择最优的模型部署为在线http服务供业务方调用。
本次实验选用的是PAI-Studio作为实验平台,仅通过拖拽组件就可以快速实现一套基于对象特征的推荐系统。本实验的数据和完整业务流程已经内置在了PAI首页模板,开箱即用:

二、数据集介绍
数据源:本数据源为天池大赛提供数据,数据按时间分为两份,分别是7月份之前的购买行为数据和7月份之后的。
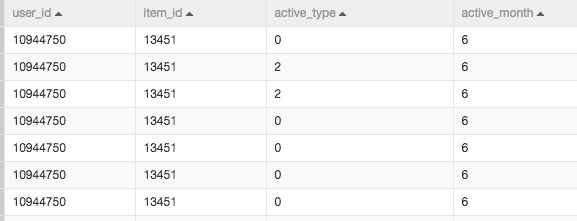
具体字段如下:
| 字段名 | 含义 | 类型 | 描述 |
|---|---|---|---|
| user_id | 用户编号 | string | 购物的用户ID |
| item_id | 物品编号 | string | 被购买物品的编号 |
| active_type | 购物行为 | string | 0表示点击,1表示购买,2表示收藏,3表示购物车 |
| active_date | 购物时间 | string | 购物发生的时间 |
数据截图: 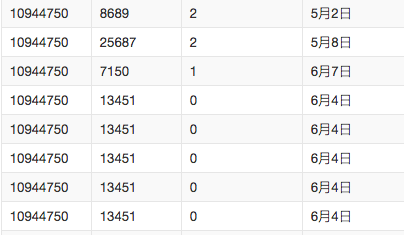
三、数据探索流程
本次实验选用的是PAI-Studio作为实验平台,仅通过拖拽组件就可以快速实现一套基于协同过滤的推荐系统,并且支持自动调参以及模型一键部署的服务。
实验流程图:
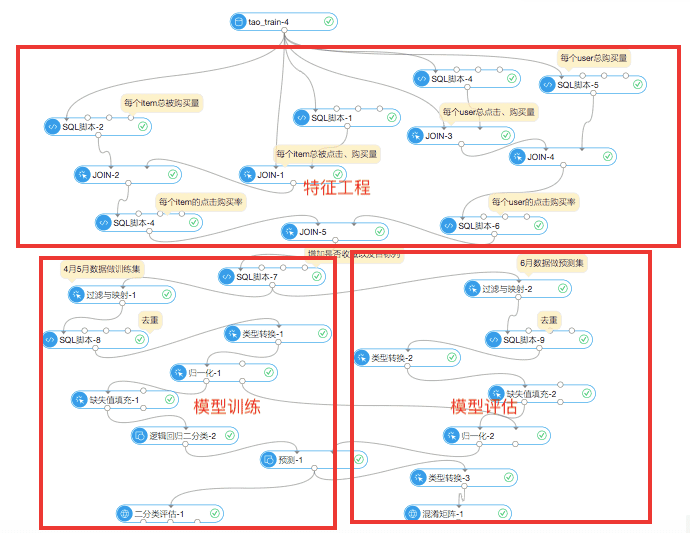
(1)特征工程
在特征工程的流程中是把最原始的只有4个字段的数据通过特种工程的方法进行数据维度的扩充。在推荐场景中有两个方面特征,一方面是所推荐的对象的特征,另一方面是被推荐对象的特征。
在商品推荐这个案例中:
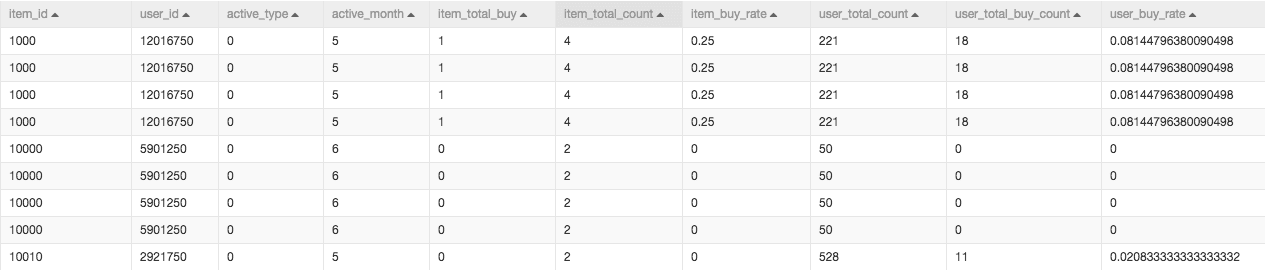
- 被推荐对象为商品(item),扩充的维度为每个item被购买量、每个item被点击量、每个item被点击购买率(购买量除以点击率)
- 推荐对象为用户(user),扩充的维度为每个user总的购买量、总的点击量、总的点击购买率(点击数除以购买率,可以得出每点击多少次购买一个产品,可以用来描述用户购物的果断性)
最终数据由原始的4个字段变成了10个字段:
(2)模型训练
现在已经构建了一个大宽表,有了做完特征工程的结构化数据,现在就可以训练模型了。这个案例中选用了逻辑回归算法,在做模型训练过程中有一个痛点就是如何找到合适的参数,对于逻辑回归参数(如下图)而言,如何调整以下几个参数,使得模型训练能达到最好的效果是一个非常有挑战的任务。
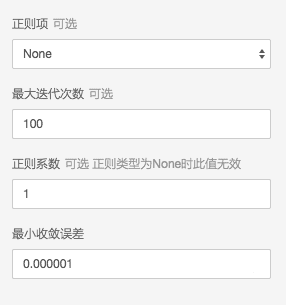
为了解决繁琐的调参工作带来的劳动量问题,PAI产品内置了AutoML引擎帮助调参,在页面上打开AutoML,只要设置下需要调参的算法的参数范围以及评估标准,后台引擎即可在最小的资源消耗下找到最合理的参数,详见:
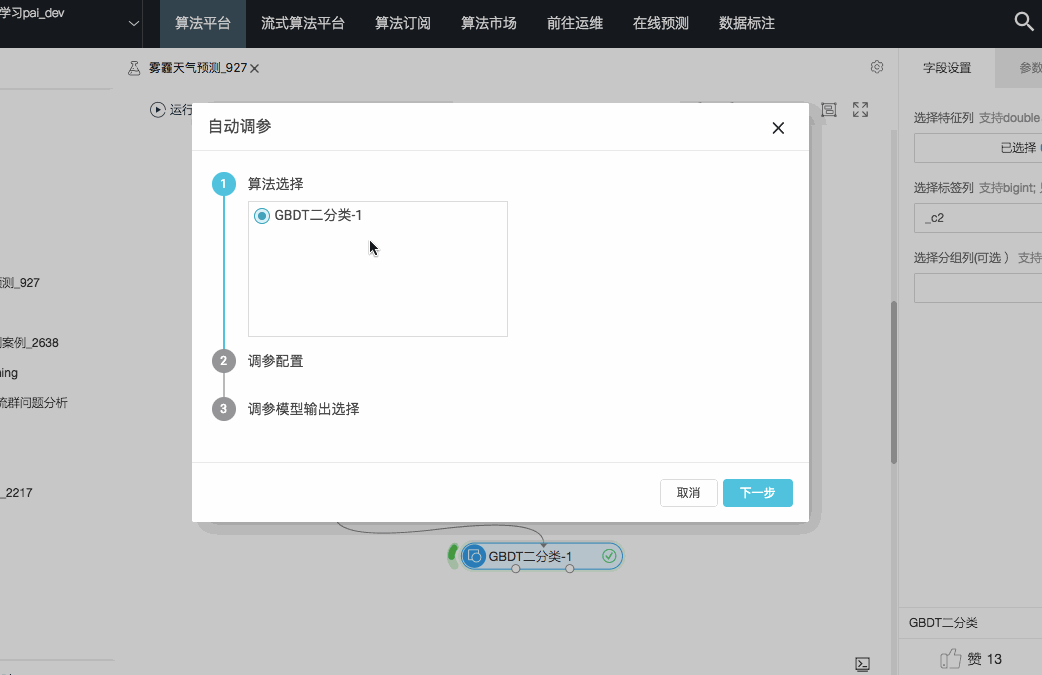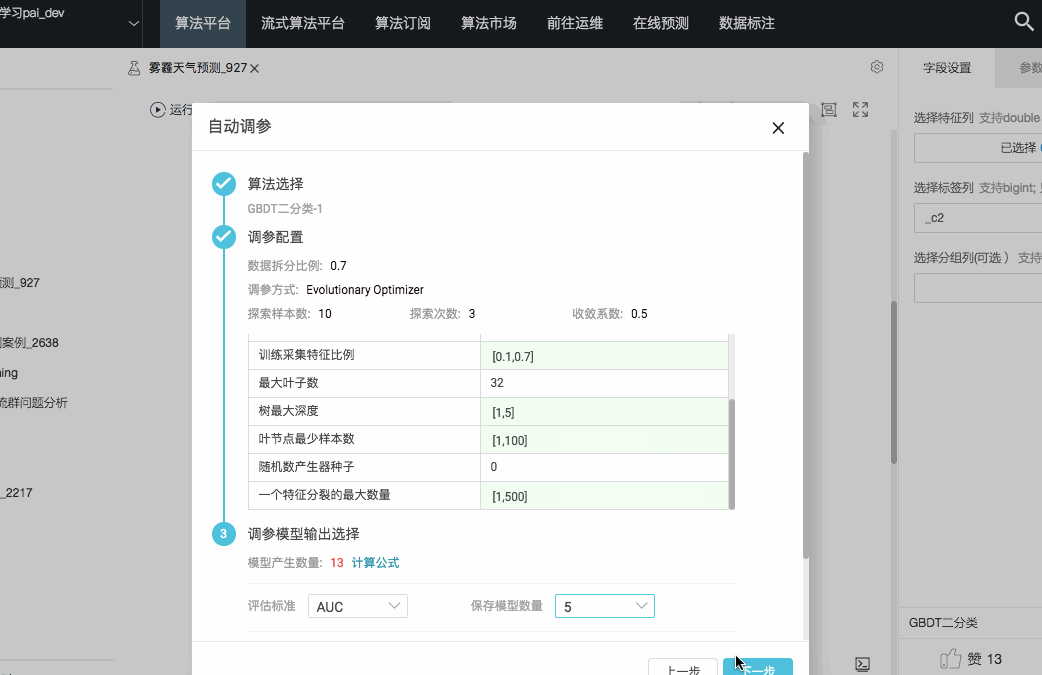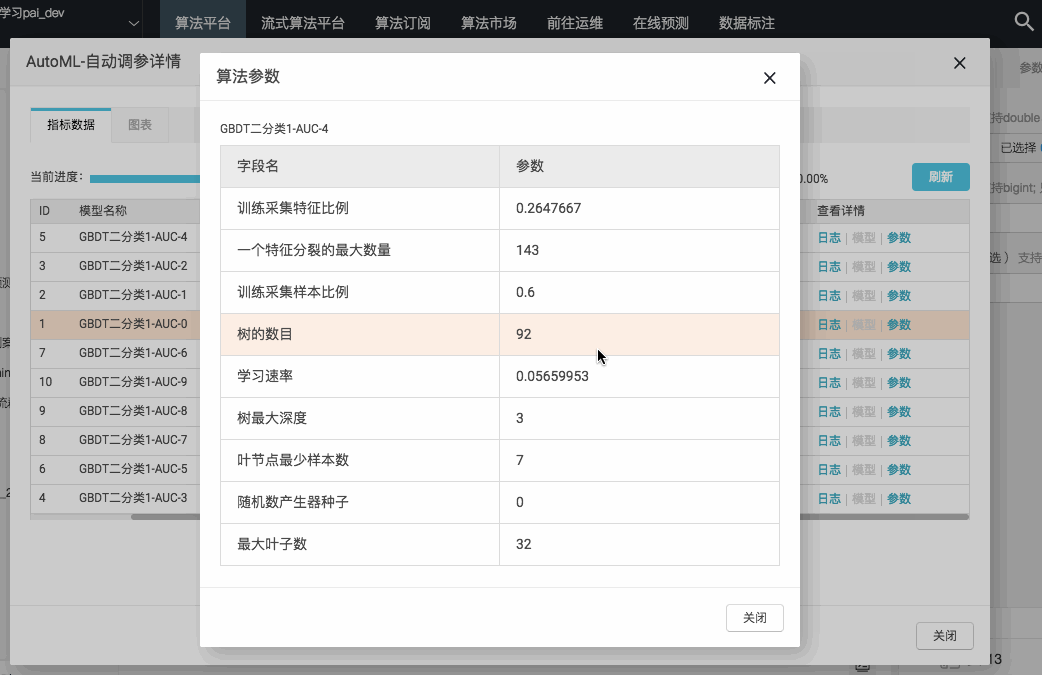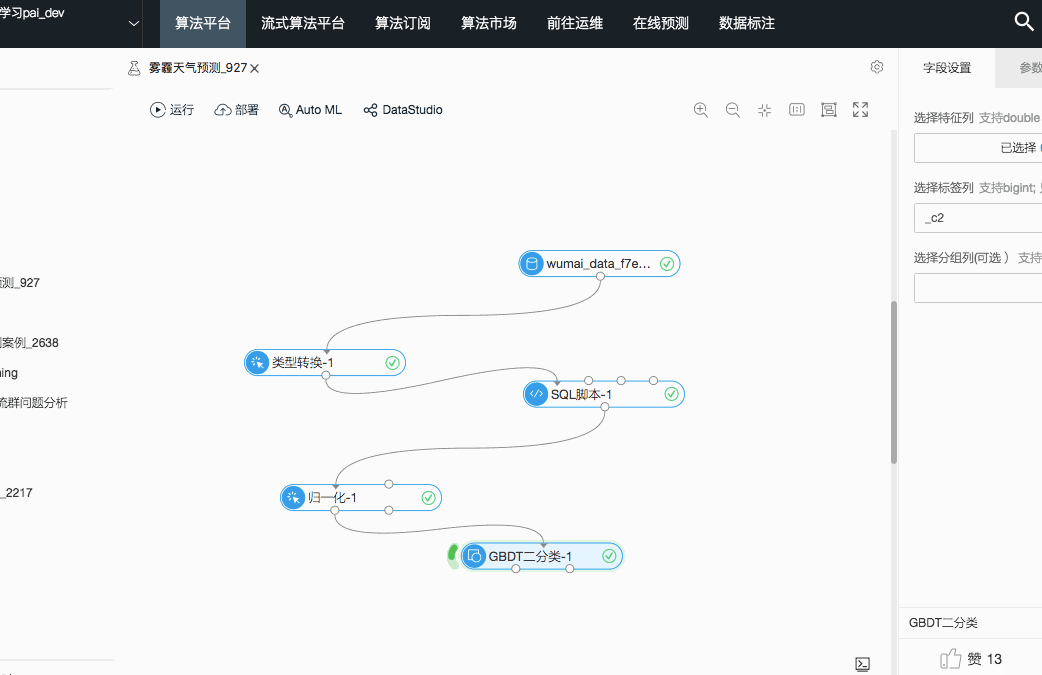
(3)模型评估
模型评估模块是用预留的一部分未参与模型训练的数据评估模型质量,通常推荐场景都是二分类实验,可以使用混淆矩阵和二分类评估组件去评估结果。
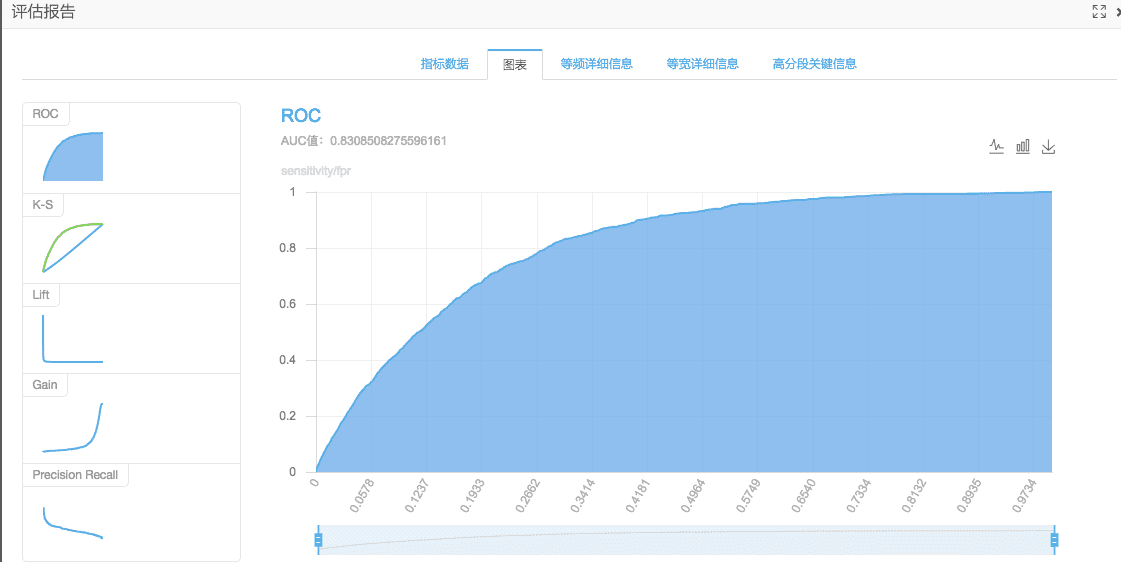
- 二分类评估:打开组件选择“图表”,会展示下图ROC曲线,其中蓝色区域的面积为AUC值,面积越大表示模型质量越高
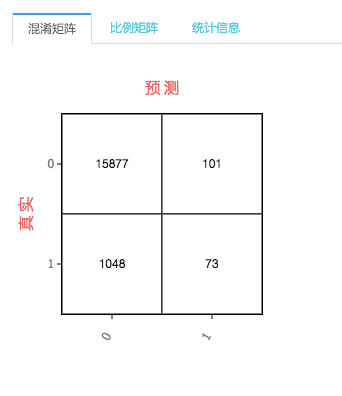
- 混淆矩阵:通过混淆矩阵可以确定具体的预测准确率、召回率、F1-Score等指标
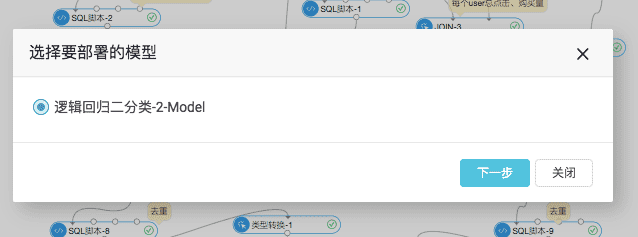
(4)模型在线部署
模型生成后,如果效果也达到预期,可以使用PAI-EAS将模型一键部署为在线服务,通过http访问。点击画布上的“部署”按钮,选择“模型在线部署”功能,选择需要部署的模型。
后续流程可以参考在线预测文档:https://help.aliyun.com/document_detail/92917.html
部署成在线服务之后,模型服务可以通过http请求访问,这样就可以做到模型跟用户自身的业务结合,完成PAI模型训练和业务应用的打通。