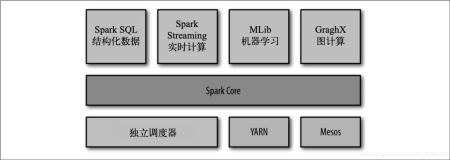
什么是Spark?
Spark是一个分布式计算引擎,2009年诞生于UC伯克利的AMPLab,2010年开源并于2013年成为Apache顶级项目。
| 名称 | 地址 |
|---|---|
| 官方网站 | https://spark.apache.org/ |
| git地址 | https://github.com/apache/spark |
Spark具有如下特点:
1.快速
- DAG框架
Spark采用的是DAG框架,DAG是在MapReduce框架基础上演化而来。
对于一些复杂的数据处理,比如有多个Reduce Stage,MapReduce框架中一个Reduce前面必须要有一个Map(Map-Reduce-Map-Reduce...),不能多个Reduce级联处理,这样会导致处理过程中会增加很多冗余的Map阶段,即使Map不做任何数据处理(读取HDFS数据直接输出),但是这个过程耗费了很多时间和资源。
DAG框架可以任意的组合Map/Reduce的算子(如Map-Reduce-Reduce),更加灵活更快速。
如Tez(Tez也是DAG)文档里面有例子说明,详见https://cwiki.apache.org/confluence/display/Hive/Hive+on+Tez, 其中以一个TPC-DS的例子进行了说明。
- MapReduce是多进程模型,虽然可以更细粒度控制task占用的资源,但是JVM启动会消耗更多的时间,Spark则采用的是多线程模型,task启动快,不同的task可以共享内存;
- Spark可以对RDD数据集进行cache,对迭代计算很友好更快速
- Spark的性能优化项目Tungsten Project(https://www.slideshare.net/databricks/spark-performance-whats-next) ,对计算过程中的内存管理/CPU缓存友好等方面进行了很多优化。如WholeStageCodeGen,对火山模型(Volcano Model)进行了优化,减少了函数调用等。
2.易用
支持SQL/Scala/Java/Python/R语言
- 算子丰富
用户可以将算子进行组合完成数据处理,如wordcount ,只需要写几行代码,相对于MapReduce实现Map和Reduce要简单很多。
val rdd = spark.sparkContext.textFile("/README.md")
val counts = rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
counts.saveAsTextFile("/results")- 交互式
可以通过SQL/Scala/Python/R的shell进行交互式的使用
如:
[root@emr-header-1 ~]# spark-shell
scala>spark.sql("create table t(a string)")
[root@emr-header-1 ~]# pyspark
>>> textFile = spark.read.text("README.md")
[root@emr-header-1 ~]# spark-sql
> select * from t;
- 接口更统一
Spark 2.0中StructStreaming/MLlib等接口基本统一到DataSet/DataFrame,API简单,使得编程更容易,而SparkSQL/SparkCore模块的优化,可以立即体现到上层模块(Streaming/MLlib等)。
3.通用
Spark包含SparkSQL/StructStreaming/MLlib/GraphX,能够处理各种大数据处理需求,如ETL离线处理、流式计算、机器学习、图计算等,只需要Spark就能应对大数据处理中的大部分场景。
4.融合
- 多种部署方式
不仅可以独立部署standalone模式,也可以运行在Yarn/Mesos等资源调度框架之上 -
多数据源接入
可以读写HBase/HDFS/Cassandra/OSS/S3/Hive/Alluxio等DataSource,如:// 初始化SparkSession val spark = SparkSession.builder .master("local[2]") //local模式 .appName("test") .enableHiveSupport() //使用Hive的元数据管理 .getOrCreate() val df1 = spark.read.parquet(basePath) val df2 = spark.read.text("oss://bucket/path/xxx") val df3 = spark.sql("select * from t")
Spark技术栈

1. 数据源
Spark支持对接各种数据源,如HDFS/OSS/HBase/MySQL/Kafka等。
DataFrame封装了一些数据源接入,比如json/csv/mysql等,用户可以直接通过调用相关api去读写这些数据源文件;
DataFrame还提供了DataSource接入的扩展api,用户可以根据api将自己的DataSource接入Spark;
用户也可以将数据源封装成RDD来使用;网站 https://spark-packages.org/ 上有很多第三方实现的数据源可以直接拿来使用。
EMR团队也实现了很多对接阿里云产品的SDK供大家使用(https://github.com/aliyun/aliyun-emapreduce-sdk)
社区目前在做DataSourceV2的重构(https://docs.google.com/document/d/1uUmKCpWLdh9vHxP7AWJ9EgbwB_U6T3EJYNjhISGmiQg/edit?ts=5be4868a#)
2. 资源调度
Spark可以通过YARN/Mesos进行资源管理。如将Spark作业提交到YARN的某个队列中,通过控制队列的分配达到对Spark作业的资源限制管理等。
3.Spark引擎
Spark是一个大数据处理的工具包,一套引擎里面可以做ETL/流计算/图计算等。
SparkCore是Spark引擎的最底层,它的任何改动/优化都会影响到上层模块。它以RDD为核心,将外层数据源抽象成RDD数据集,然后通过一些算子(transformation)对RDD进行转换操作(如map/filter等)生成新的RDD,最终通过算子(action)真正的提交执行获取所需数据结果。


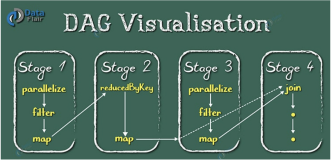
如上图所示,将HDFS文件抽象成RDD1数据集,然后通过map/filter算子对RDD1进行转换处理,分别得到了新的RDD2/RDD3,最后通过saveAsTextFile这个action类型的算子真正触发作业的提交运行,将结果写到HDFS中。
上图只是一个简单的SparkCore中以RDD为核心的数据处理流程。RDD提供了很多操作算子,用户可以利用这些算子进行组合来处理更复杂的数据处理逻辑,如groupBy/reduce等等。
SparkCore对RDD数据处理过程,包含很多模块,比如Stage/Task的调度, Shuffle, 内存管理, 排序等等,以后再详细介绍。
下面是一张大概的内部执行流程图,图中相关概念可以去Spark官网查看(如RDD/transformation和action两种类型的算子/宽依赖/窄依赖等)。

后续
1.对SparkCore中的调度/shuffle/内存管理等详细介绍
2.上层组件SparkSQL/StructStreaming/MLlib/GraphX/SparkR的介绍
欢迎指正交流