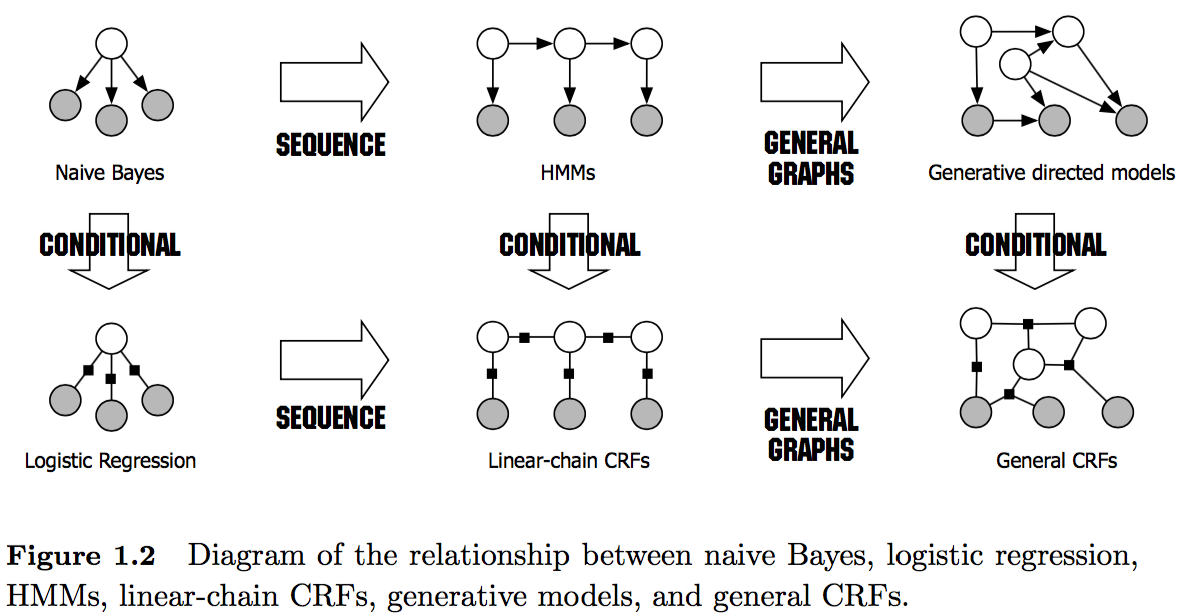
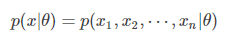条件随机场就像HMM一样,最开始让我难以理解,但其实认真看了,也不是太难。本文总结自这边博客,它的引用的资料值得一看。
一、马尔可夫随机场
概率图模型(Probabilistic gaphical model,PGM)是由图表示的概率分布。概率图模型(Probabilistic gaphical model,PGM)又称马尔可夫随机场(Markov random field),表示一个联合概率分布,其标准定义为:
设有联合概率分布P(V)由无向图G = (V, E)表示,图G中的结点表示随机变量,边表示随机变量间的依赖关系。如果联合概率分布P(V)满足成对、局部或全局马尔可夫性,就称此联合概率分布为概率无向图模型或马尔可夫随机场。
设有一组随机变量Y,其联合分布P(Y)由无向图G = (V, E)表示。图G的一个结点表示一个随机变量
,一条边
表示两个随机变量间的依赖关系。
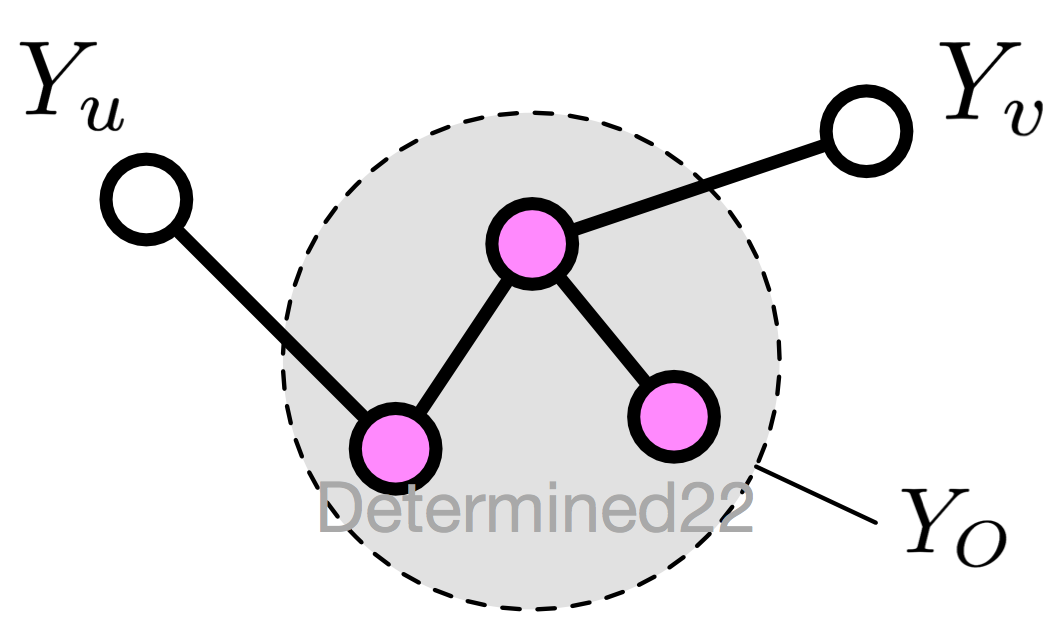
1、成对马尔可夫性(pairwise)
设无向图G中的任意两个没有边连接的结点u、v,其他所有结点为O,称为马尔可夫性指:给定的条件下,
和
条件独立
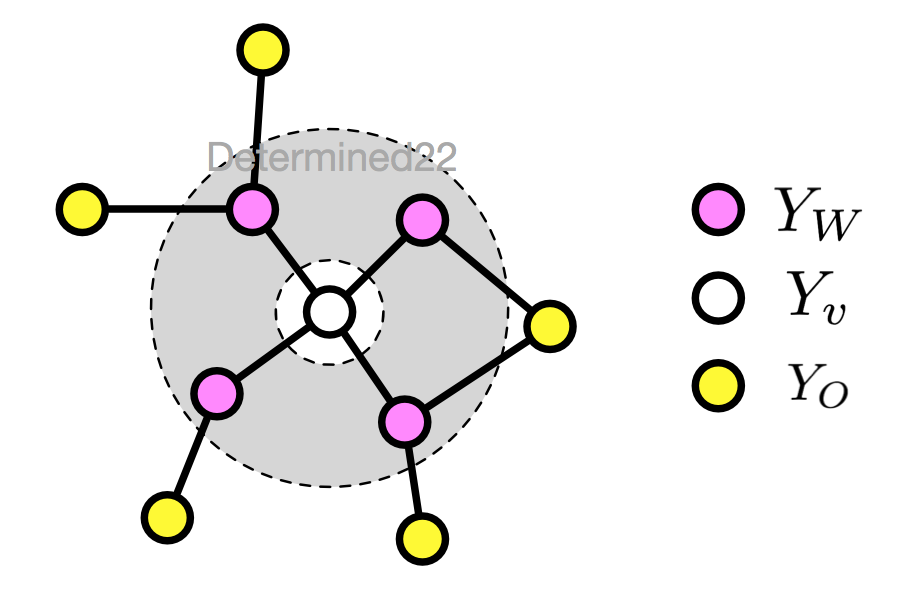
2、局部马尔可夫性(local)
设无向图G的任意结点v,W是与v有边相连的所有结点,O是v,W外的其他所有结点,局部马尔可夫性指:给定的条件下,
和
条件独立
当时,等价于
如果把等式两边的条件的遮住,
这个式子表示
和
独立,进而可以理解这个等式为给定条件
下的独立。
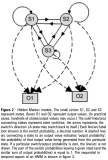
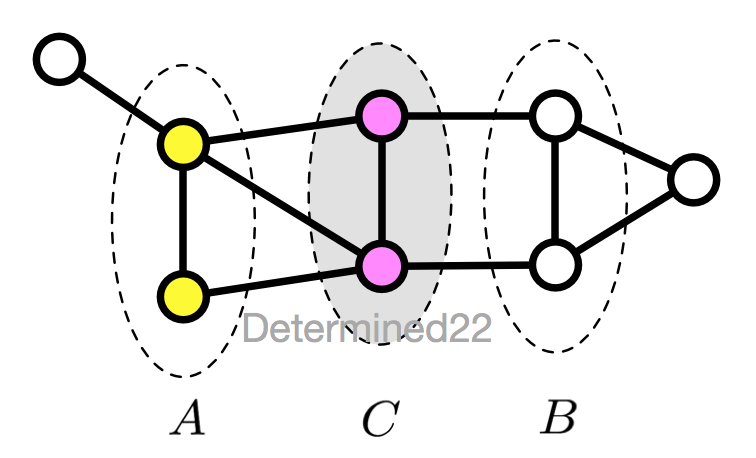
3、全局马尔可夫性(global)
设结点集合A、B是在无向图G中被结点集合C分开的任意结点集合,全局马尔可夫性指:给定的条件下,
和
条件独立。
这几个定义是等级的。
4、概率无向图模型
无向图模型的有点在于其没有隐马尔可夫模型那样严格的独立性假设,同时克服了最大熵马尔可夫模型等判别式模型的标记偏置问题。
(1)有向图的联合概率分布
考虑一个有向图,随机变量间的联合概率分布可以利用条件概率来表示为:
表示结点
的父节点的集合。
(2)无向图的因子分解(Factorization)
不同于有向图模型,无向图模型的无向性很难确保每个结点在给定它的邻接点的条件下的条件概率和以图中其他结点为条件的条件概率一致。由于这个原因,无向图模型的联合概率并不是用条件概率参数化表示的,而是定义为由一组条件独立的局部函数的乘积形式。因子分解就是说将无向图所描述的联合概率分布表达为若干个子联合概率的乘积,从而便于模型的学习和计算。
实现这个分解要求的方法就是使得每个局部函数所作用的那部分结点可以在G中形成一个最大团(maximal clique)。这就确保了没有一个局部函数是作用在任何一对没有边直接连接的结点上的;反过来说,如果两个结点同时出现在一个团中,则在这两个结点所在的团上定义一个局部函数来建立这样的依赖。
无向图模型最大的特点就是易于因子分解,标准定义为:
将无向图模型的联合概率分布表示为其最大团(maximal clique,可能不唯一)上的随机变量的函数的乘积形式。
给定无向图G,其最大团为C,那么联合概率分布P(Y)可以写作图中所有最大团C上的势函数(potential function)的乘积形式:
其中Z为规范化因子,对Y的所有可能取值求和,从而保证了P(Y)是一个概率分布。要求势函数严格正,通常定义为指数函数:
上面的因子分解过程就是Hammersley-Clifford定理。
二、条件随机场
条件随机场(Conditional random field,CRF)是条件概率分布模型P(Y|X),表示的是给定一组输入变量X的条件下另一组输出随机变量Y的马尔可夫随机场,也就是说CRF的特点是假设输出随机变量构成马尔可夫随机场。
条件随机场科看着是最大熵马尔可夫模型在标注问题上的推广。
这里介绍的是用于序列标注问题的线性链条件随机场(linear chain conditional,CRF),是由输入序列来预测输出序列的判别式模型。
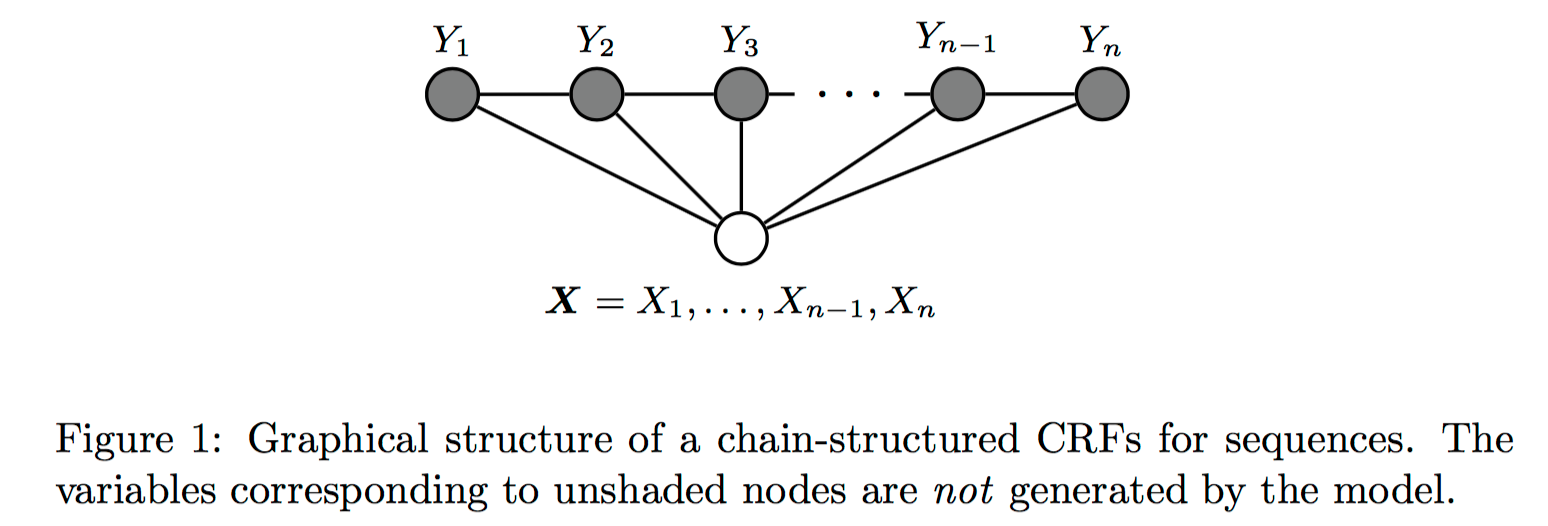
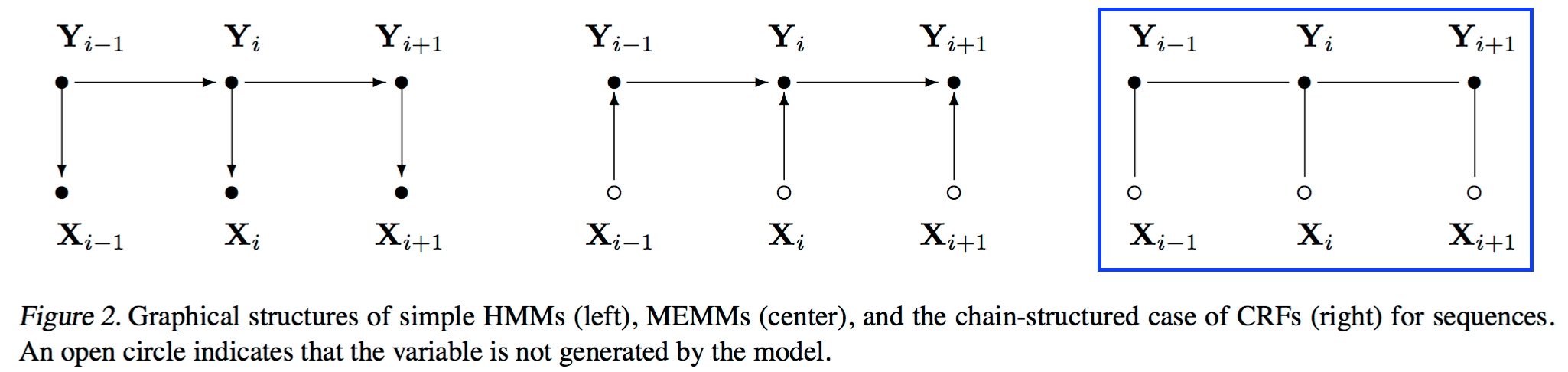
从问题描述上看,对于序列标注问题,X是需要标注的观测序列,Y是标记序列(状态序列)。在学习过程中, 通过极大似然估计或带正则的极大似然估计来训练出模型参数;在测试过程,对于给定的观测序列,模型需要求出条件概率最大的输出序列。
如果随机变量Y构成一个由无向图G = (V, E)表示的马尔可夫随机场,对任意结点
对任意结点v都成立,则称P(Y|X)是条件随机场。式中
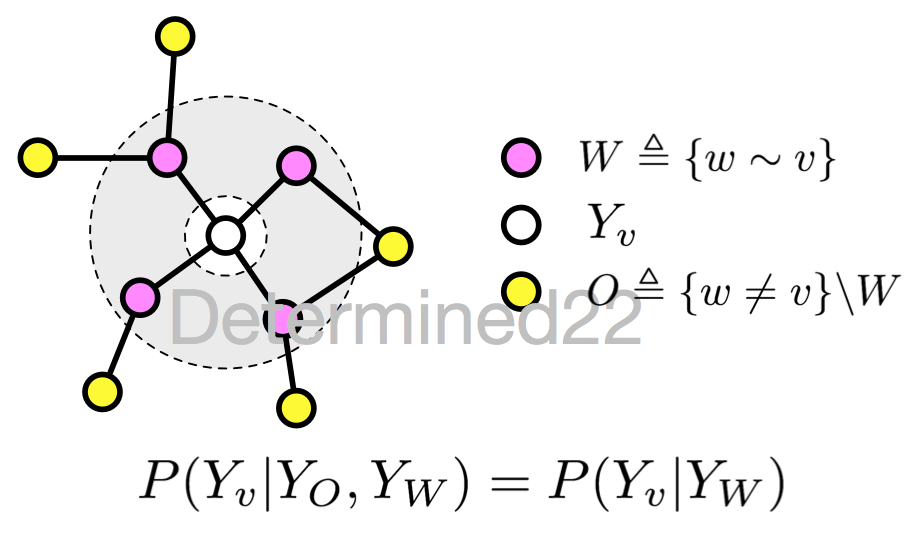
这就是马尔可夫随机场的定义。
线性链条件随机场
在定义中并没有要求X和Y具有相同的结构,而在现实中,一般假设X和Y有相同的图结构。对于线性链条件随机场来说,图G的每条边都存在于状态序列Y的相邻两个结点,最大团C是相邻两个结点的集合,X和Y有相同的图结构意味着每个都与
一一对应。
设两组随机变量X = (X_1, ..., X_n),Y = (Y_1, ..., Y_n),那么线性链条件随机场的定义为:
其中当i取1或者n时,只考虑单边。
1、线性链条件随机场的数学表达式
(1)、线性链条件随机场的参数化形式:特征函数及例子
此前我们知道,马尔可夫随机场可以利用最大团的函数做因子分解。给定一个线性条件随机场P(Y|X),当观测序列为时,状态序列为
的概率可写为(实际上应该些微
,参数被省略了)
作为规范化因子,是对y 的所有可能取值求和。
序列标准 VS 分类
未完待续,真长。。。。。