什么是Flink Batch功能
实时计算 Flink是阿里巴巴在开源Flink基础上做了大量优化的Flink版本,其中增加了大量的批处理相关功能,使Flink成为统一了批流计算模型的大数据处理引擎。
如何试用Flink Batch功能
与流处理功能相同,Flink Batch功能对SQL有完善的支持,并且做到了批流SQL统一。与流相比,批的SQL暂不支持window相关函数,其他语法都支持。所以SQL文档请参考公共云流计算SQL文档。
如何创建批处理作业
准备工作
创建批处理作业
-
进入流计算控制台。
-
创建batch作业。
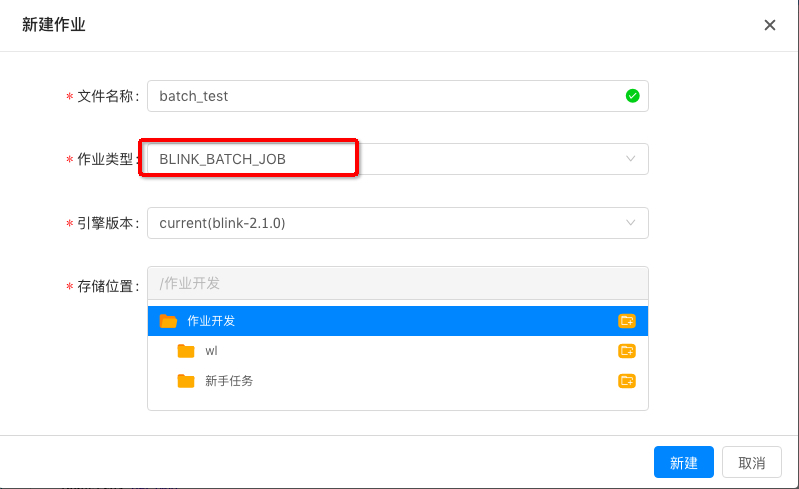
-
编写作业,示例:读取HDFS数据进行计算,并写回HDFS。
-
-- 源表DDL,类型orc,存放路径,用户HDFS的 hdfs://roothdfs/table/ds=20180816/ 目录create table hdfs_orc_source(name varchar,age BIGINT,birthday BIGINT) with (type='orc',path='hdfs://hdfshome/user/hive/warehouse/xxx/table1/dt=20180814',enumerateNestedFiles='true');-- 结果表ddlcreate table test_sink(name varchar,age bigint,birthday bigint) with (type='orc',filePath='hdfs://hdfshome/orcpath/test')-- DML语句insert into test_sinkselectname,age,birthdayfrom hdfs_source
说明:
- connector相关配置,请参考阿里云官网Batch(试用)。
- SQL相关文档,请参考FlinkSQL手册。
本文转自实时计算——
Batch功能介绍
