

说明: 实时计算 Flink按照标准的阿里云产品规格提供账号信息支持,即一个项目隶属于一个项目所有者,多人协作模型必须使用主子账号完成。
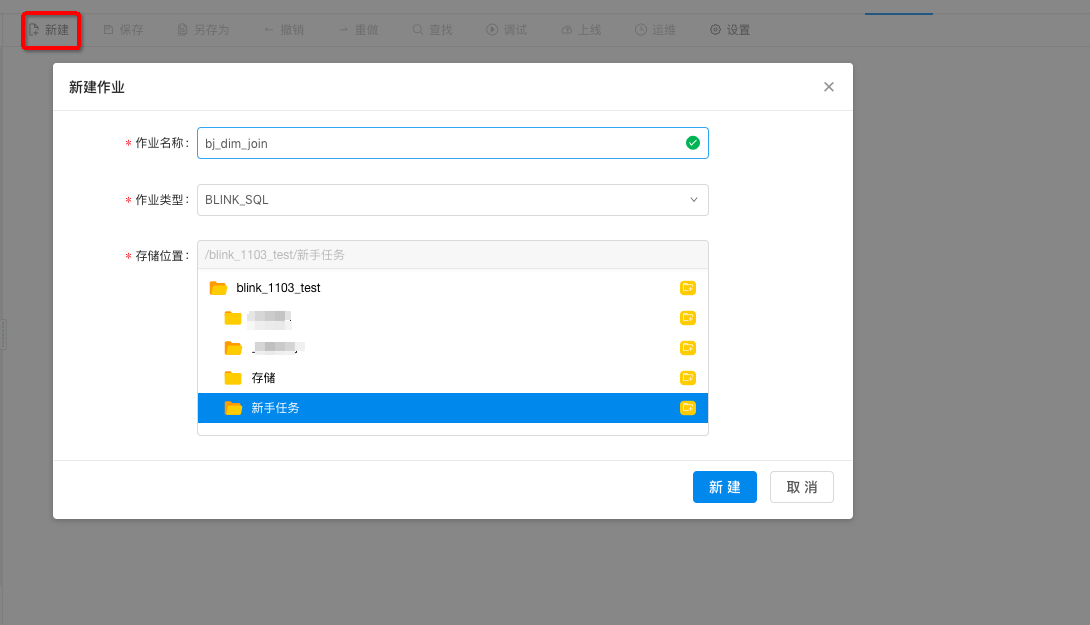
完成数据采集工作后,您可以专注于StreamSQL的编写工作。为方便您熟悉实时计算,我们在开发作业>新手作业中提供了教学作业bj_dim_join 。点击bj_dim_join,您可以查看StreamSQL的具体内容。
新建作业
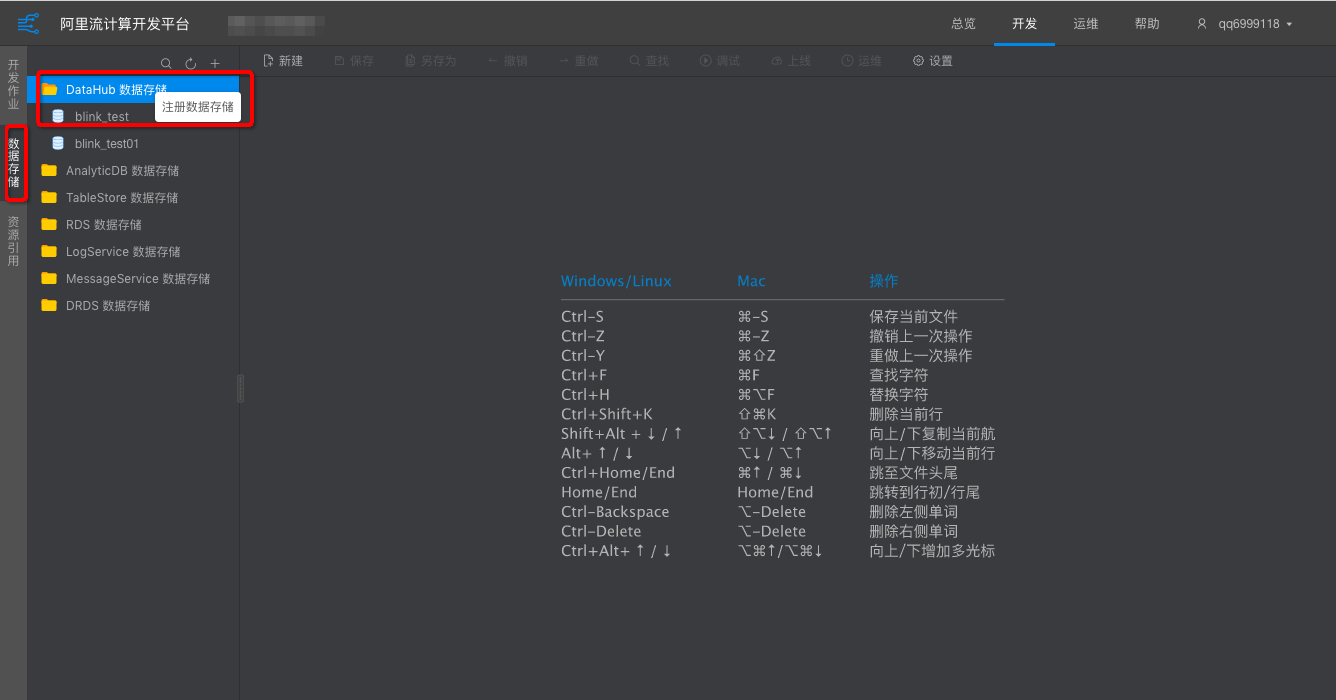
开发储存
为了让您使用更便利、更安全使用数据存储的功能,建议以DataHub作为数据源表。DataHub可以自动生成源表参数和您的schema信息。更多详情请您参阅数据存储。
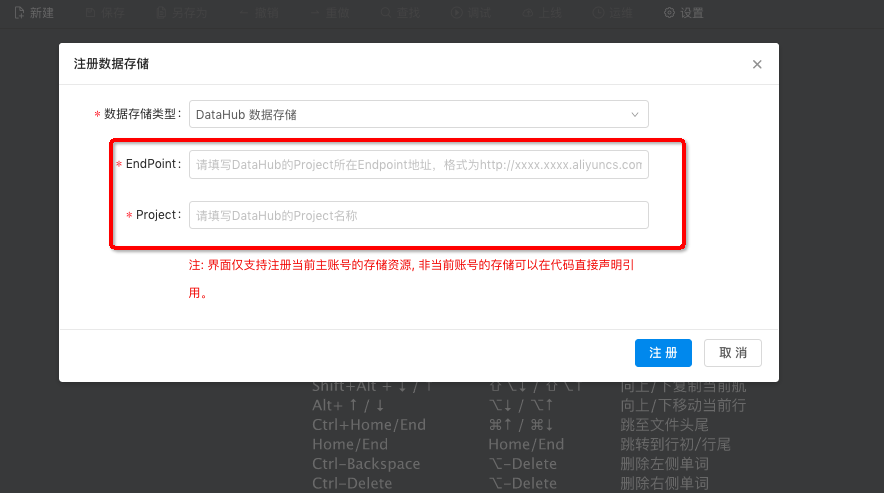
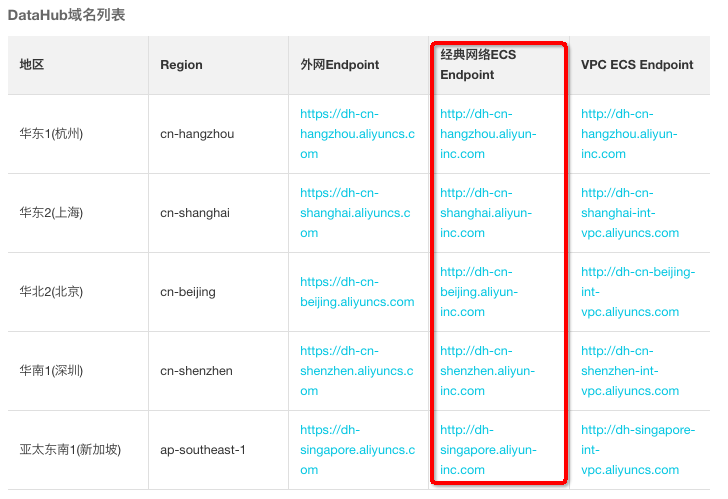
DataHub的参数的配置可以参阅DataHub的源表,EndPoint信息如下图。
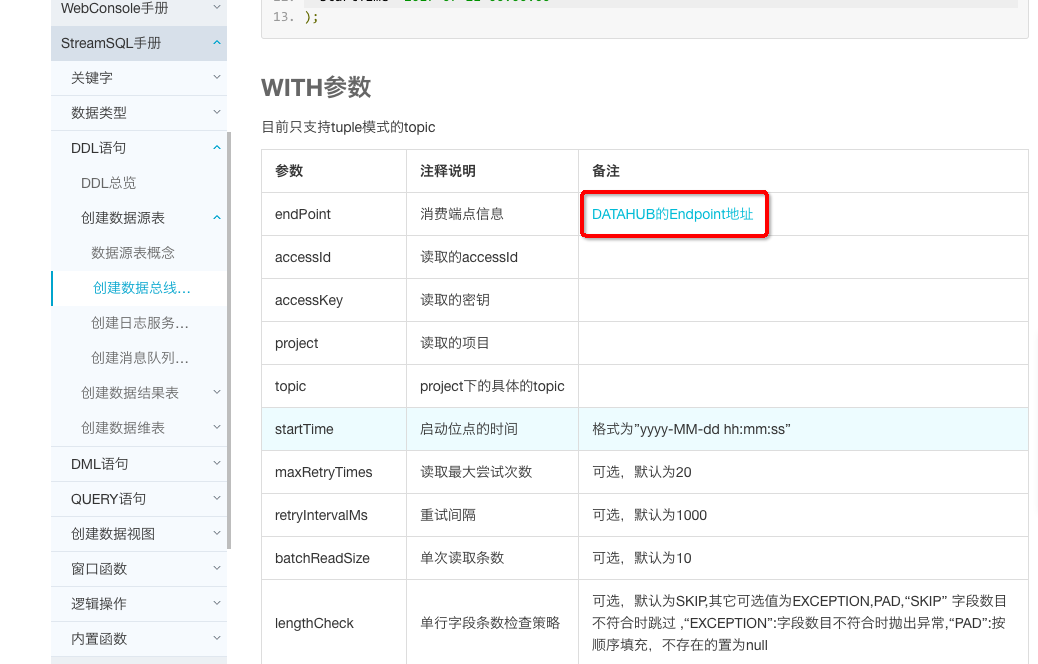
进入DataHub的EndPoint地址,根据地区选择不同的地址。
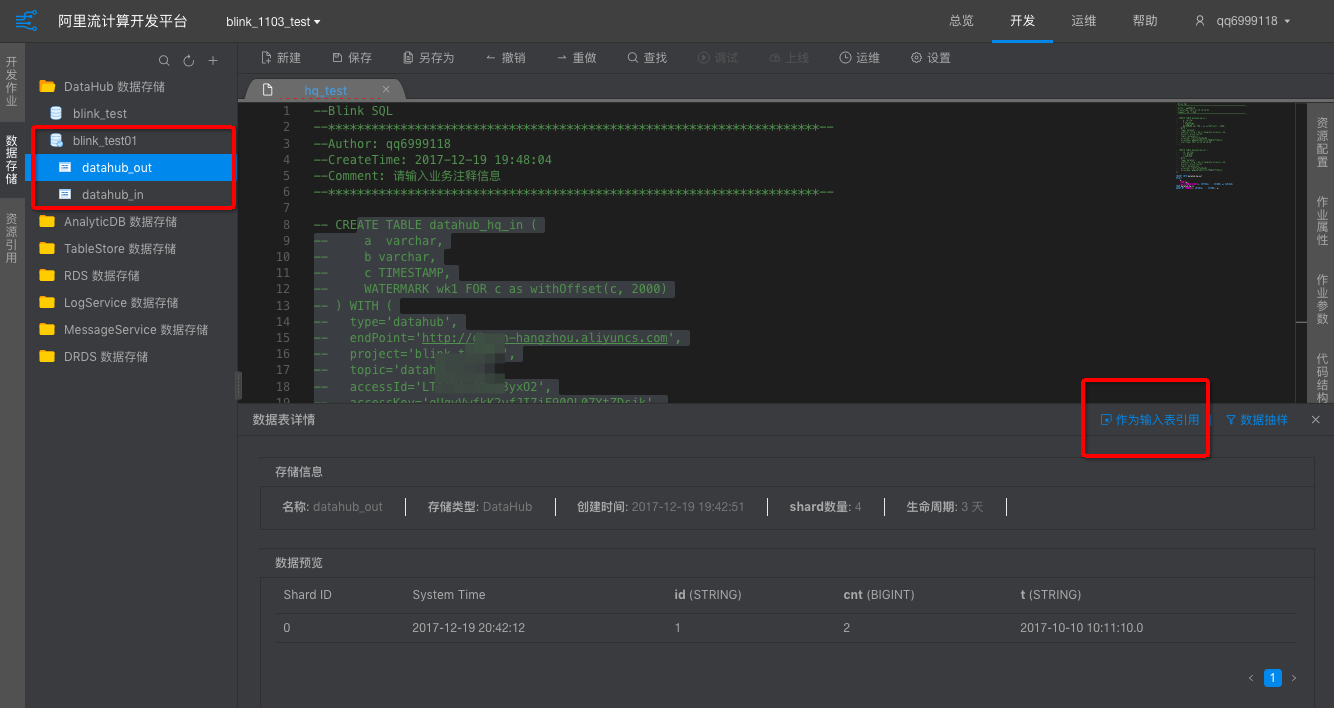
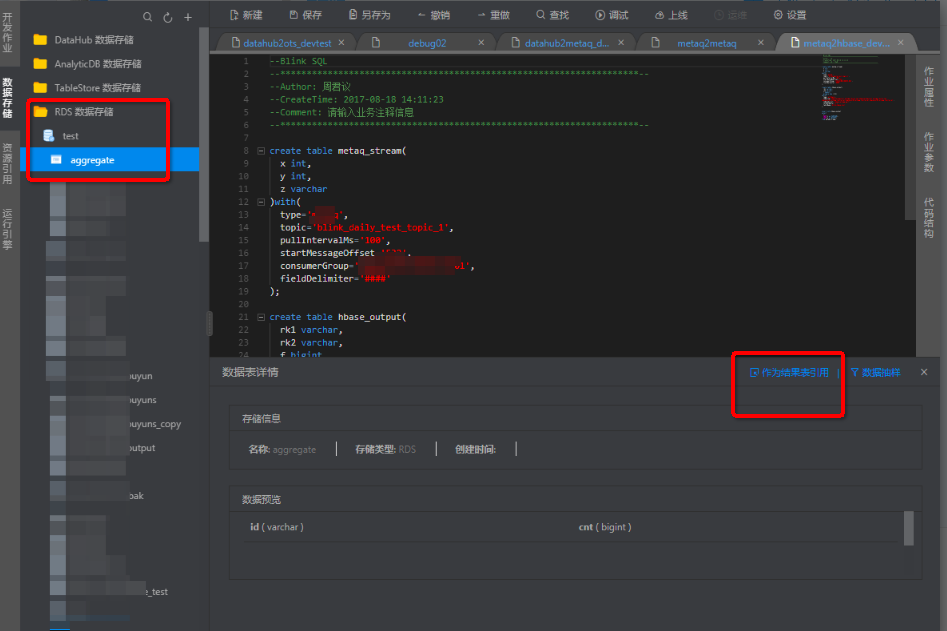
用RDS为数据的维表或结果表
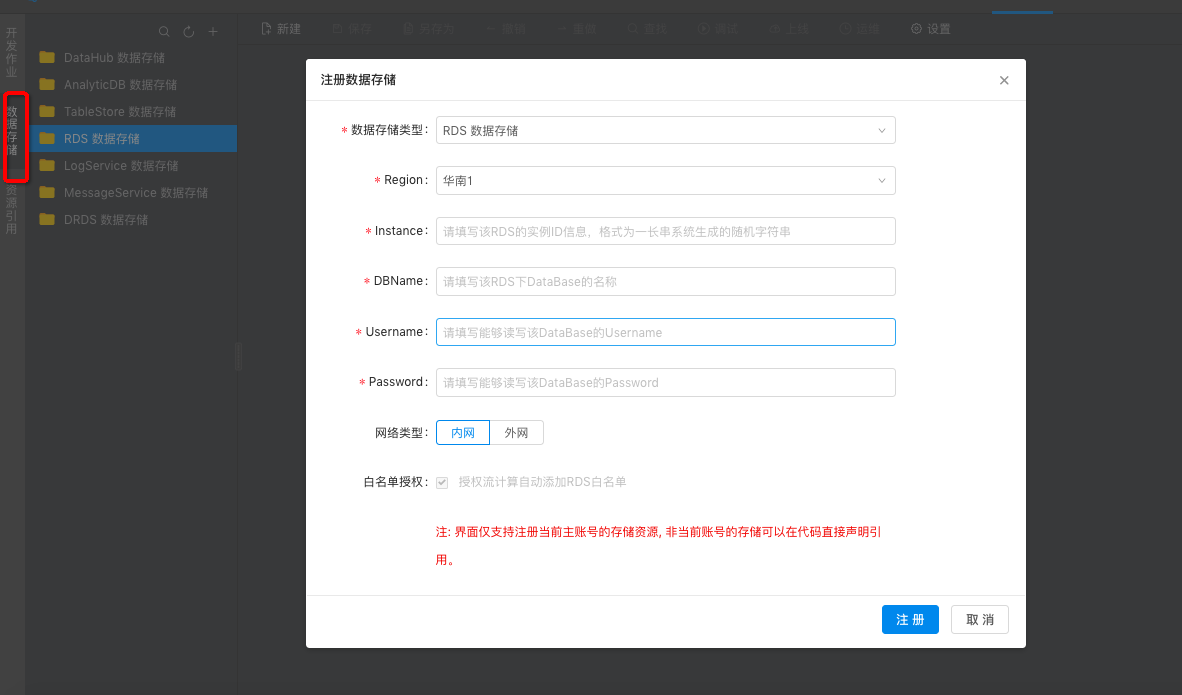
手动填写RDS维表的参数和您的schema信息,RDS的参数的配置可以参阅RDS的维表。
注意:维表暂不支持数据存储的功能。
CREATE TABLE rds_dim (`name` VARCHAR,Place VARCHAR,PERIOD FOR SYSTEM_TIME,--维表的声明语法必须填写!PRIMARY KEY (Place)) WITH (--可以复用SINK表里的参数type= 'rds',url = '填写URL',userName = '账号',password = '密码',tableName = '表名');
用RDS为数据的结果表,使用数据存储自动生成RDS的参数和您的schema信息,RDS的参数的配置可以参阅RDS的结果表。
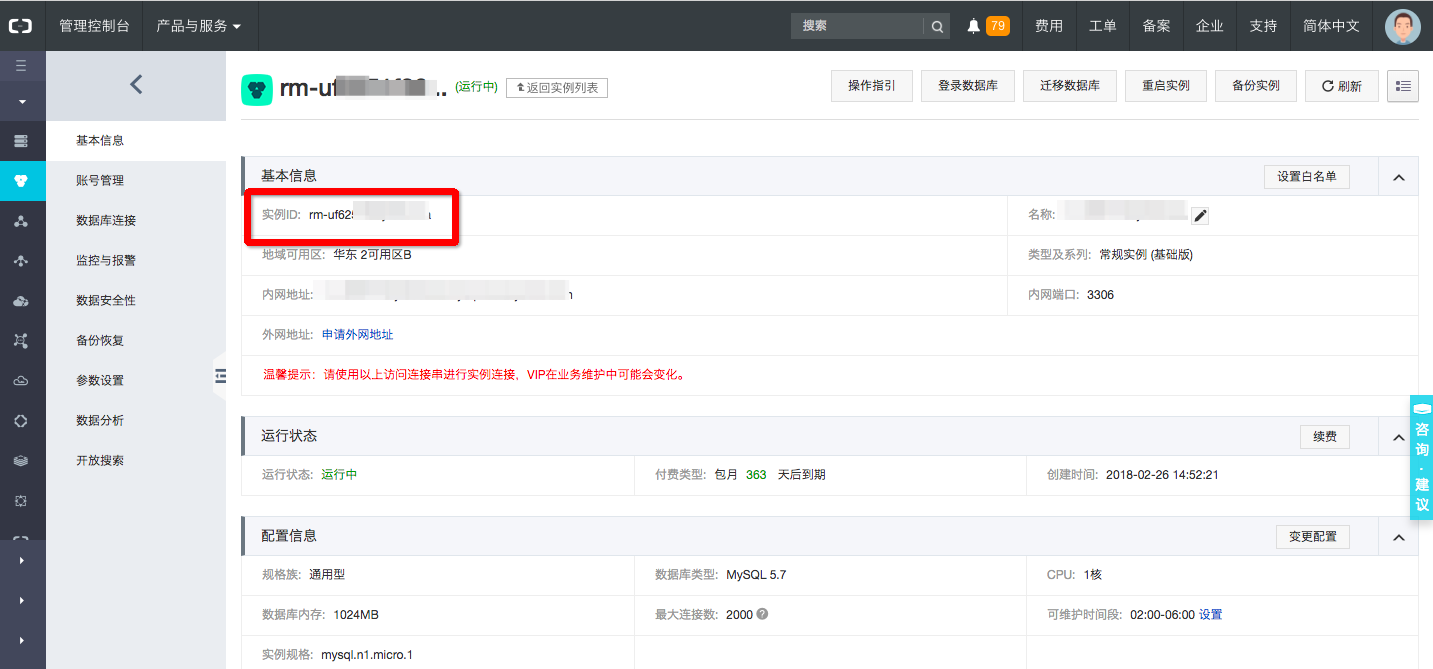
Instance填写刚刚注册的实例ID。
编写业务逻辑的SQL
INSERT INTO rds_ipplaceSELECTt.`name`,w.PlaceFROM datahub_ipplace as tJOIN rds_dim FOR SYSTEM_TIME AS OF PROCTIME() as wON t.place = w.Place;
作业调试StreamSQL
详情操作请参阅作业调试。
作业上线
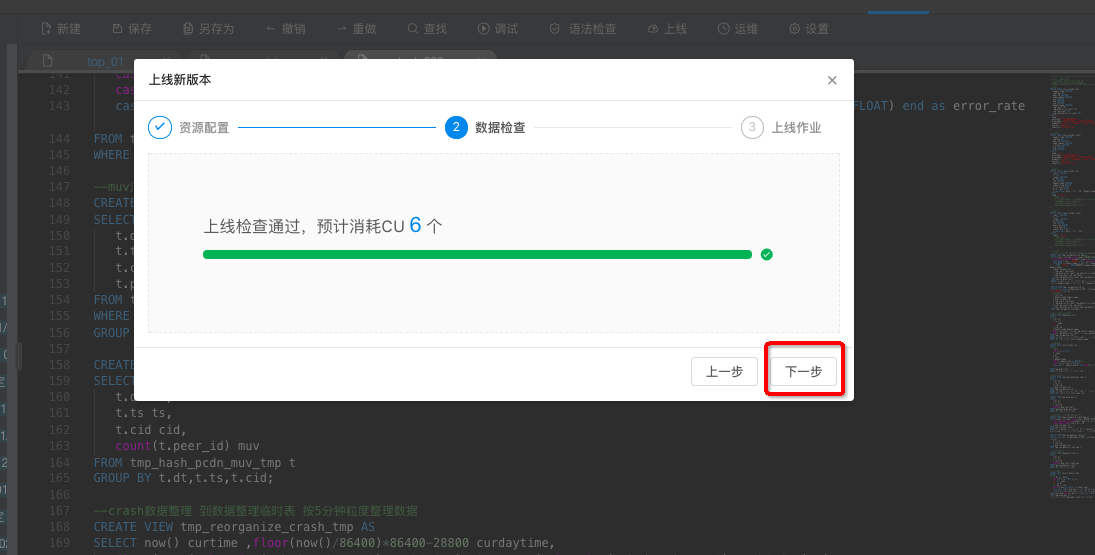
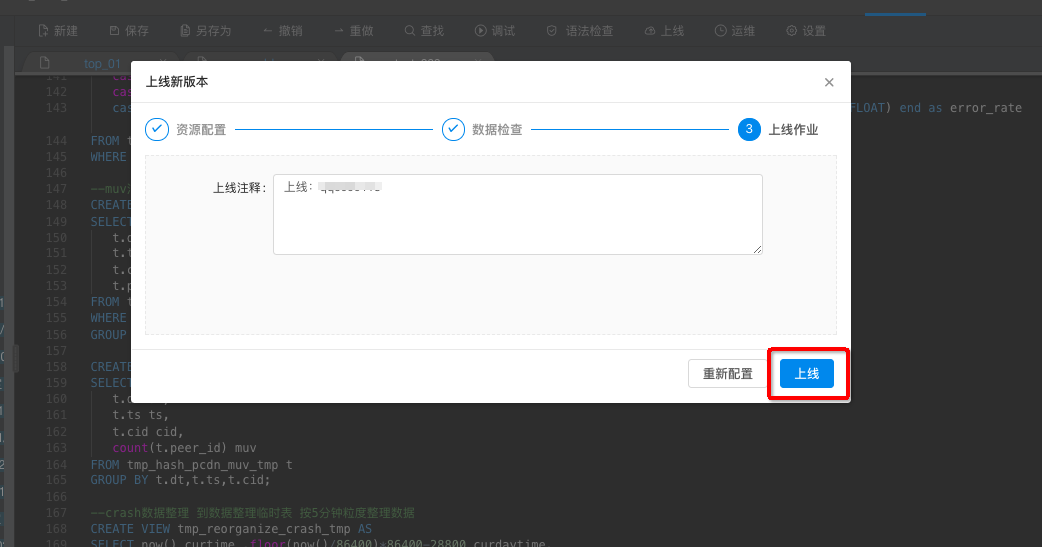
调试完成后,经验证逻辑无误后,在数据开发中点击上线作业,您即可完成作业上线工作。上线作业操作将您的改动提交到数据运维中,您即可在生产环境下进行作业启动等生产运维工作。步骤如下图。
资源配置

数据检查
上线作业
本文转自实时计算——步骤三:数据开发,作业上线




