本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
以下为译文
本篇文章是"Python股市数据分析"两部曲中的第一部分(第二部分的文章在这里),内容基于我在犹他州立大学MATH 3900 (Data Mining)课程上的一次讲座。在这些文章中,我将介绍一些关于金融数据分析的基础知识,例如,使用pandas获取雅虎财经上的数据,股票数据可视化,移动均线,开发一种均线交叉策略,回溯检验以及基准测试。第二篇文章会介绍一些实践中可能出现的问题,而本篇文章着重讨论移动平均线。
注意:本篇文章所涉及的看法、意见等一般性信息仅为作者个人观点。本文的任何内容都不应被视为金融投资方面的建议。此外,在此提供的所有代码均无法提供任何保证。选择使用这些代码的个人需自行承担风险。
引言
高等数学与统计学已在金融领域应用了一段时间。 在20世纪80年代以前,银行业和金融界以"枯燥乏味"而闻名;投资银行与商业银行不同,银行的主要职责在于处理"简单的"(至少与今天相比)金融商品,如贷款。里根政府的放松管制,再加上一大批数学天才,将整个行业从"枯燥的"银行业务转变成了今天这个样子,而且,从那时起,金融便融入了其他自然学科,激励着数学领域的研究与发展。比如,近期数学领域最大的成就之一,便是Black-Scholes公式的推导,这一成果可用于股票期权(一种赋予持有人以特定价格向期权发行商购买或出售股票权利的合约)的定价。可以说,在一定程度上,包括 Black-Scholes公式在内的糟糕的统计学模型导致了2008年金融危机的爆发。
近几年来,为了在买卖金融资产的过程中赚取利润,计算机科学也同高等数学一起,参与到了金融与贸易领域的变革当中。最近几年,计算机主导着贸易的进行;算法相比人类能够更快速地做出交易决策(如此之迅速,以至于在设计系统时,光的传导速度成为了约束)。此外,机器学习与数据挖掘技术在金融领域越来越受欢迎,而且以后也可能会继续这样下去。实际上,大部分的算法交易都属于高频交易(HFT)。尽管算法的表现可能超过人类,但是这项技术并不成熟,应用的领域又充满着高风险与动荡。高频交易导致了2010年与2013年市场的闪电崩盘,其中,2013年的崩盘是由一条美联社被黑客伪造的关于白宫受到攻击的推文所引发的。
然而,本篇文章并不会讨论如何使用糟糕的数学模型和交易算法使股市崩盘。相反,我打算向大家介绍一些用于处理和分析股市数据的Python工具。我还将讨论移动均线、如何使用移动均线来构建交易策略、如何在进入仓位时制定退出策略以及如何使用回溯检验评估交易策略等方面的内容。
声明:这不是关于金融投资的建议!!!而且,我从未从事过交易员等工作(许多这方面的知识我都是在盐湖城社区学院中一门为期一学期的股市交易课程中接触到的)!这些只是单纯的入门级知识,并不足以读者在股市中进行实际的交易操作。股市有风险,入市需谨慎!
获取并可视化股票数据
使用pandas从雅虎财经中获取数据
在我们处理股票数据之前,我们首先需要通过一些可行的途径获取它们。股票数据可以从雅虎财经、谷歌财经或者其他数据源中获得,而pandas可以轻松访问雅虎财经、谷歌财经以及其他来源中的数据。在本篇文章中,我们从雅虎财经获取股票数据。
以下代码演示了直接创建一个包含股票信息的DataFrame对象的过程。(你可以在这里了解更多关于远程数据访问的信息。)
import pandas as pd
import pandas.io.data as web
import datetime
start = datetime.datetime(2016,1,1)
end = datetime.date.today()
apple = web.DataReader("AAPL", "yahoo", start, end)
type(apple)C:\Anaconda3\lib\site-packages\pandas\io\data.py:35: FutureWarning:
The pandas.io.data module is moved to a separate package (pandas-datareader) and will be removed from pandas in a future version.
After installing the pandas-datareader package (https://github.com/pydata/pandas-datareader), you can change the import ``from pandas.io import data, wb`` to ``from pandas_datareader import data, wb``.
FutureWarning)
pandas.core.frame.DataFrameapple.head()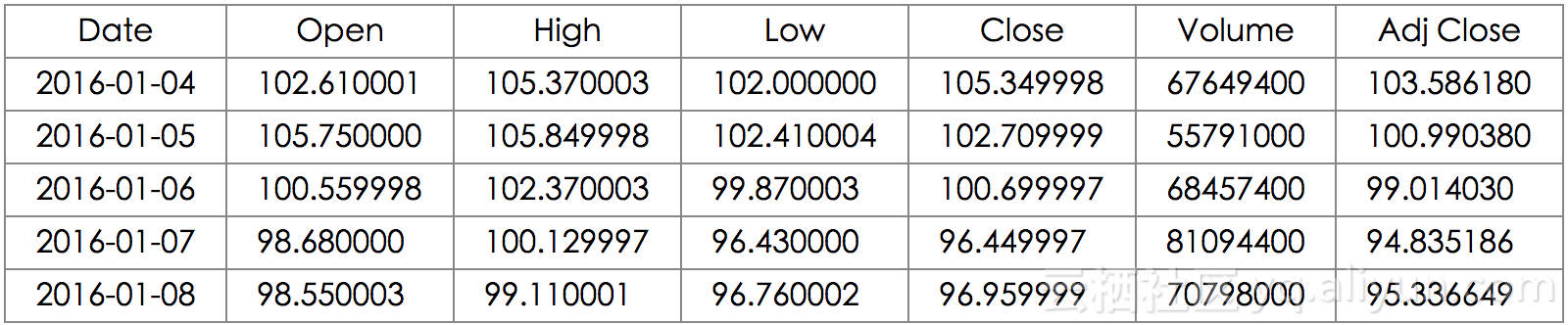
让我们简单介绍一下。开盘价是指股票在交易日开市时的股价(并不一定是前一交易日的收盘价格),最高价是指在交易日当天股价的最高价格,最低价是指在交易日当天股价的最低价格,收盘价是指股票在交易日收盘时的股价。交易量表示被交易股票的数量。调整收盘价是根据公司行为调整后的股票收盘价格。尽管我们认为大多数股票的价格是由交易员设定的,但是股票分割(公司将当前的一张股票拆分成价值一半的两张股票)和派付股息(为每份股份支付公司红利)仍然会影响到股票的价格,这些情况我们都应该考虑进来。
股票数据可视化
既然我们现在有了股票数据,我们可以通过可视化的形式展示它。我首先演示如何使用matplotlib来可视化股票数据。注意,名为apple的DataFrame对象有一个很方便的方法plot(),这个函数使创建图表更加容易。
import matplotlib.pyplot as plt
%matplotlib inline
%pylab inline
pylab.rcParams['figure.figsize'] = (15, 9)
apple["Adj Close"].plot(grid = True) Populating the interactive namespace from numpy and matplotlib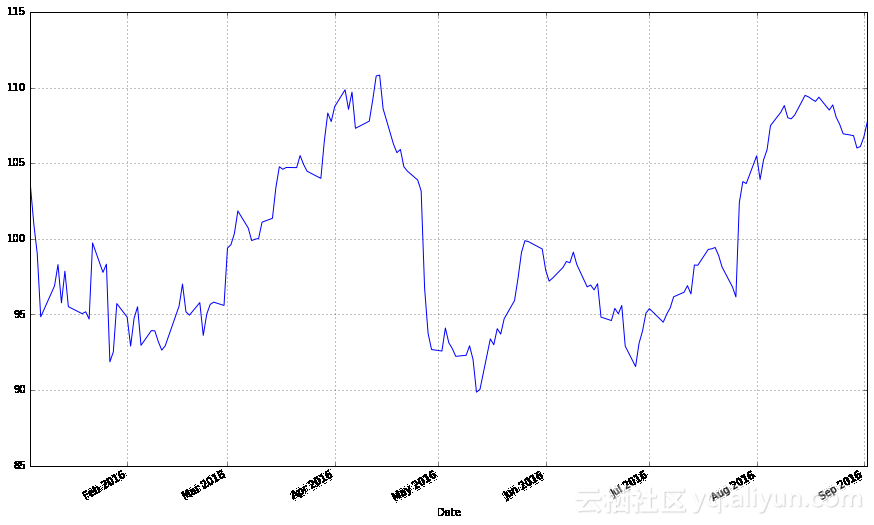
折线图是很不错,但是每个日期都至少包含四个变量(开盘价、最高价、最低价、收盘价),我们希望有一些可视化的方法能够同时展示这四个变量,而不是简单地画四条折线。金融数据通常以日本蜡烛图(即K线图)的形式绘制,这种图表最早在18世纪由日本米市商人命名。matplotlib可以绘制这样的图表,但操作起来比较复杂。
我实现了一个函数,你可以更容易地在pandas数据框架中创建蜡烛图,并使用它绘制我们的股票数据。(代码基于这个例子,你可以在这里找到相关函数的文档)
from matplotlib.dates import DateFormatter, WeekdayLocator,\
DayLocator, MONDAY
from matplotlib.finance import candlestick_ohlc
def pandas_candlestick_ohlc(dat, stick = "day", otherseries = None):
mondays = WeekdayLocator(MONDAY)
alldays = DayLocator()
dayFormatter = DateFormatter('%d')
transdat = dat.loc[:,["Open", "High", "Low", "Close"]]
if (type(stick) == str):
if stick == "day":
plotdat = transdat
stick = 1
elif stick in ["week", "month", "year"]:
if stick == "week":
transdat["week"] = pd.to_datetime(transdat.index).map(lambda x: x.isocalendar()[1])
elif stick == "month":
transdat["month"] = pd.to_datetime(transdat.index).map(lambda x: x.month)
transdat["year"] = pd.to_datetime(transdat.index).map(lambda x: x.isocalendar()[0])
grouped = transdat.groupby(list(set(["year",stick])))
plotdat = pd.DataFrame({"Open": [], "High": [], "Low": [], "Close": []})
for name, group in grouped:
plotdat = plotdat.append(pd.DataFrame({"Open": group.iloc[0,0],
"High": max(group.High),
"Low": min(group.Low),
"Close": group.iloc[-1,3]},
index = [group.index[0]]))
if stick == "week": stick = 5
elif stick == "month": stick = 30
elif stick == "year": stick = 365
elif (type(stick) == int and stick >= 1):
transdat["stick"] = [np.floor(i / stick) for i in range(len(transdat.index))]
grouped = transdat.groupby("stick")
plotdat = pd.DataFrame({"Open": [], "High": [], "Low": [], "Close": []})
for name, group in grouped:
plotdat = plotdat.append(pd.DataFrame({"Open": group.iloc[0,0],
"High": max(group.High),
"Low": min(group.Low),
"Close": group.iloc[-1,3]},
index = [group.index[0]]))
else:
raise ValueError('Valid inputs to argument "stick" include the strings "day", "week", "month", "year", or a positive integer')
fig, ax = plt.subplots()
fig.subplots_adjust(bottom=0.2)
if plotdat.index[-1] - plotdat.index[0] < pd.Timedelta('730 days'):
weekFormatter = DateFormatter('%b %d')
ax.xaxis.set_major_locator(mondays)
ax.xaxis.set_minor_locator(alldays)
else:
weekFormatter = DateFormatter('%b %d, %Y')
ax.xaxis.set_major_formatter(weekFormatter)
ax.grid(True)
candlestick_ohlc(ax, list(zip(list(date2num(plotdat.index.tolist())), plotdat["Open"].tolist(), plotdat["High"].tolist(),
plotdat["Low"].tolist(), plotdat["Close"].tolist())),
colorup = "black", colordown = "red", width = stick * .4)
if otherseries != None:
if type(otherseries) != list:
otherseries = [otherseries]
dat.loc[:,otherseries].plot(ax = ax, lw = 1.3, grid = True)
ax.xaxis_date()
ax.autoscale_view()
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
plt.show()
pandas_candlestick_ohlc(apple)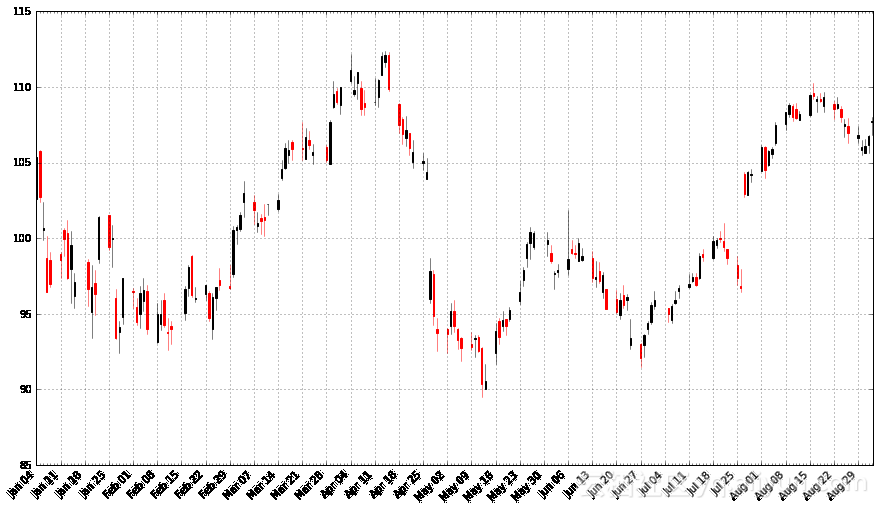
在蜡烛图中,黑色蜡烛表示交易日当天收盘价高于开盘价(盈利),而红色蜡烛表示交易日当天开盘价高于收盘价(亏损)。烛芯表示最高价与最低价,蜡烛体则表示开盘价与收盘价(颜色用来区分哪一侧为开盘价,哪一侧为收盘价)。蜡烛图在金融领域很受欢迎,根据图表中蜡烛的形状、颜色以及位置,技术分析中的一些策略可以使用它来制定交易策略。但在这里我不会介绍有关这类策略的内容。
我们可能希望在同一张图表中绘制多个金融商品的数据;我们可能想要对比股票,将它们与市场进行比较,或者看看其他证券,比如交易所交易基金(ETFs)。之后,我们可能还想看看如何根据一些指标,如移动均线,来绘制金融商品。对于这种情况,你最好使用折线图而不是蜡烛图。(如何将多个蜡烛图相互叠加在一起而不使图表混乱?)
在下面的代码中,我获取了一些其他科技公司的股票数据,并把它们的调整收盘价格绘制在了一起。
microsoft = web.DataReader("MSFT", "yahoo", start, end)
google = web.DataReader("GOOG", "yahoo", start, end)
stocks = pd.DataFrame({"AAPL": apple["Adj Close"],
"MSFT": microsoft["Adj Close"],
"GOOG": google["Adj Close"]})
stocks.head()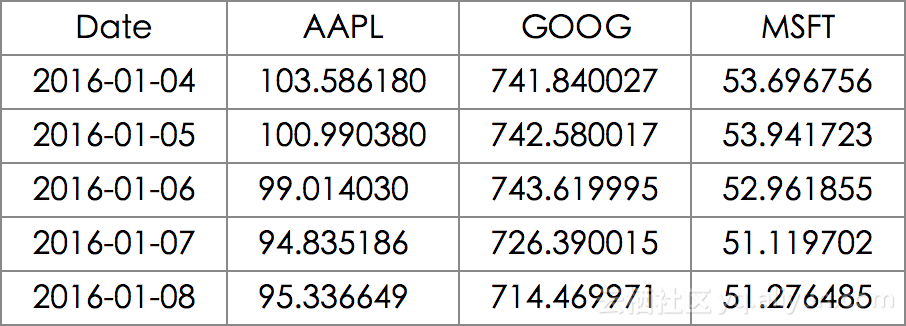
stocks.plot(grid = True)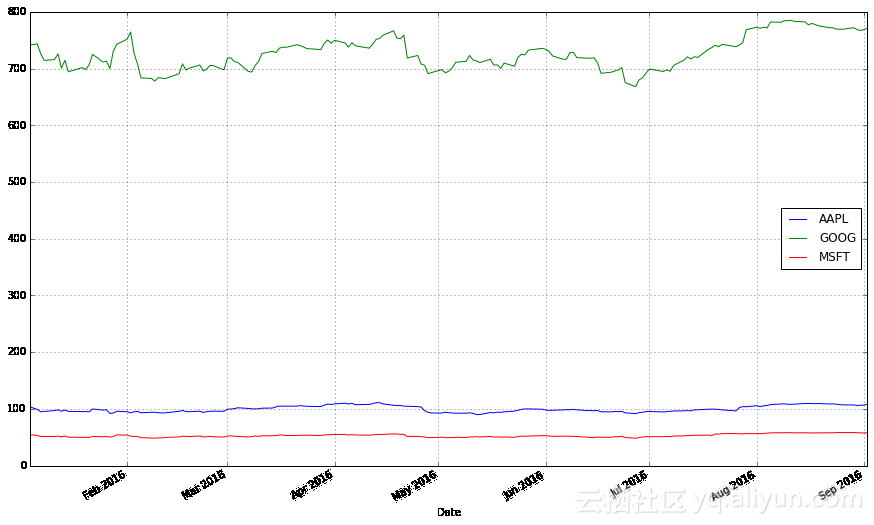
这张图有什么问题?尽管绝对价格很重要(昂贵的股票很难购买,这不仅影响着这类股票的价格波动,也影响着你交易这类股票的能力),但是在交易过程中,相比绝对价格,我们更加关心资产的相对变化。谷歌的股票比苹果和微软的股票贵得多,这种差异使得苹果和微软股票的波动看起来比实际情况小得多。
一种解决方案是在绘制图表时使用两种不同的尺度;一种尺度用于苹果和微软的股票,另一种尺度用于谷歌股票。
stocks.plot(secondary_y = ["AAPL", "MSFT"], grid = True)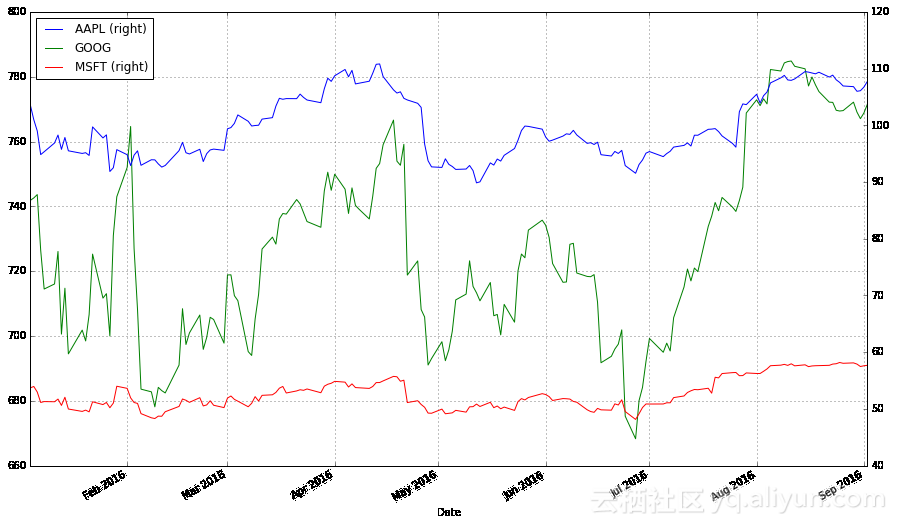
然而,一个"更好的"解决方案是,仅在图表中绘制我们真正想要的信息:股票的回报。这就需要我们根据需求将数据转换成更有用的形式。这里有几种我们可以应用的转换。
一种方式是考虑股票自利息周期开始以来的回报。换句话说,我们绘制:
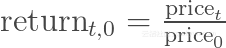
正如我下面演示的这样,这意味着转换stocks对象中的数据。
stock_return = stocks.apply(lambda x: x / x[0])
stock_return.head()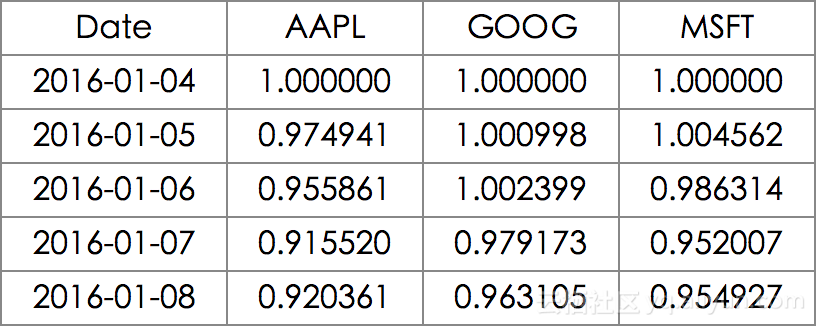
stock_return.plot(grid = True).axhline(y = 1, color = "black", lw = 2)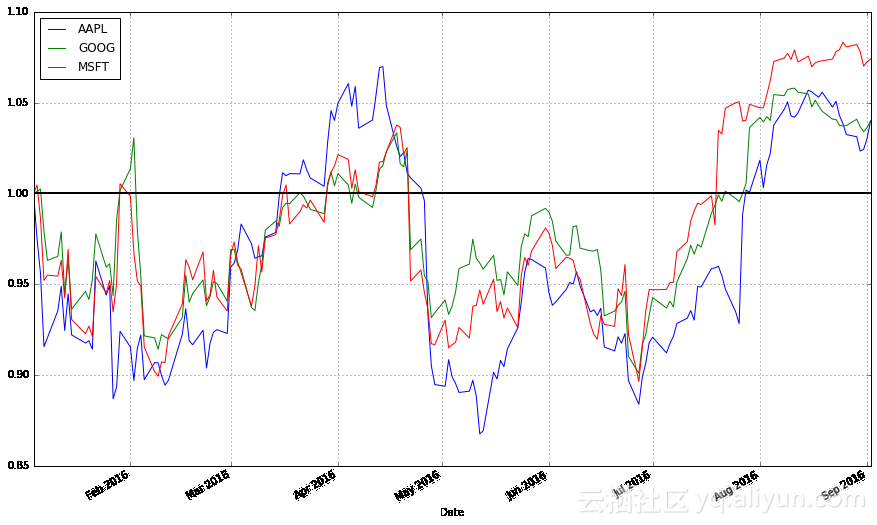
这样的图表就更有用了。现在,我们可以看到每只股票在周期开始以来的盈利。而且,我们还能发现这些股票密切相关;它们通常朝同一个方向发展,在其他的图表中很难发现这样的事实。
除此之外,我们还可以绘制每只股票在每一个交易日的变化。比如,我们可以通过比较第t天与第t+1天的价格来绘制股票增长的百分比,公式如下:
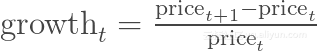
但是这种变化也可以通过如下公式定义:
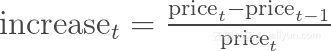
这些公式多少有些不同,可能会分析出不同的结论,但是还有另外一种对股票增长建模的方法:对数差值。
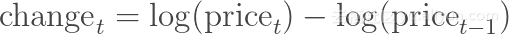
(这里的log为自然对数,我们的定义并不关心使用的是第t天与第t-1天的对数差值还是第t+1天与第t天的对数差值。)使用对数差值的好处在于,这种差值可以理解为股价的百分比变化,且不依赖于计算过程中分数的分母。
我们可以通过如下方式获取并绘制stocks对象中数据的对数差值:
import numpy as np
stock_change = stocks.apply(lambda x: np.log(x) - np.log(x.shift(1)))
stock_change.head()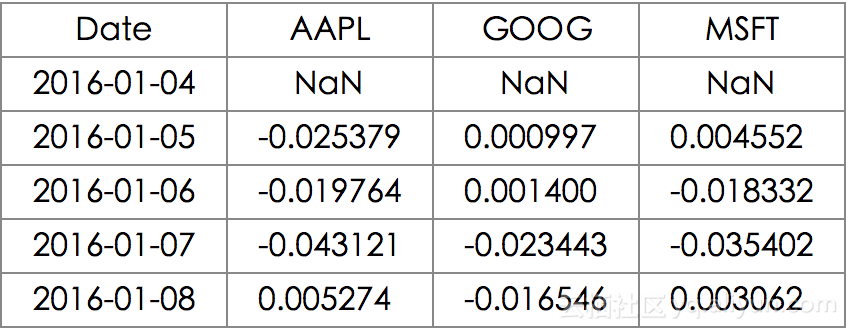
stock_change.plot(grid = True).axhline(y = 0, color = "black", lw = 2)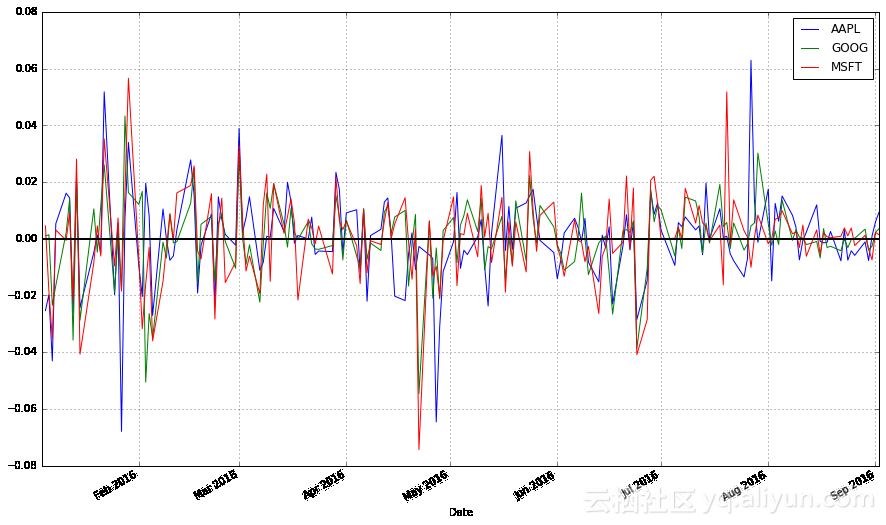
你倾向于哪一种转换?关注股票以往的盈利情况会使得证券的整体趋势更加明显。但是,在对股票的行为模式建模时,更先进的方法实际考虑的是交易日间股价的变化。因此,我们不应该忽略这部分的信息。
移动均线
图表是很非常有用的。实际上,一些交易员做出的策略几乎完全基于图表(他们属于"技术人员",因为基于在图表中查找模式的交易策略是被称为技术分析的贸易规则的一部分)。现在,让我们考虑如何才能找到股票的趋势。
对于序列xt以及时刻t,q天均线表示过去q天股价的均值:也就是说,如果MAtq表示t时刻的q天均线,那么:
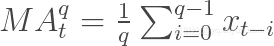
移动均线平滑了数据序列,并有助于识别股市的发展趋势。q值越大,移动均线就越难反映序列xt中的短期波动。这里的想法是,移动均线过程能够从"噪声"中识别股市的发展趋势。短期均线具有较小的q值,比较紧密地跟随股票的趋势发展,而长期均线的q值较大,进而使得均线对股票波动的响应较小,而且更加平稳。
pandas提供了轻松计算移动均线的功能。下面的代码展示了这部分功能,我首先为苹果股票创建了一条20天(1个月)均线,随后,将其与股票数据一同绘制在图表中。
apple["20d"] = np.round(apple["Close"].rolling(window = 20, center = False).mean(), 2)
pandas_candlestick_ohlc(apple.loc['2016-01-04':'2016-08-07',:], otherseries = "20d")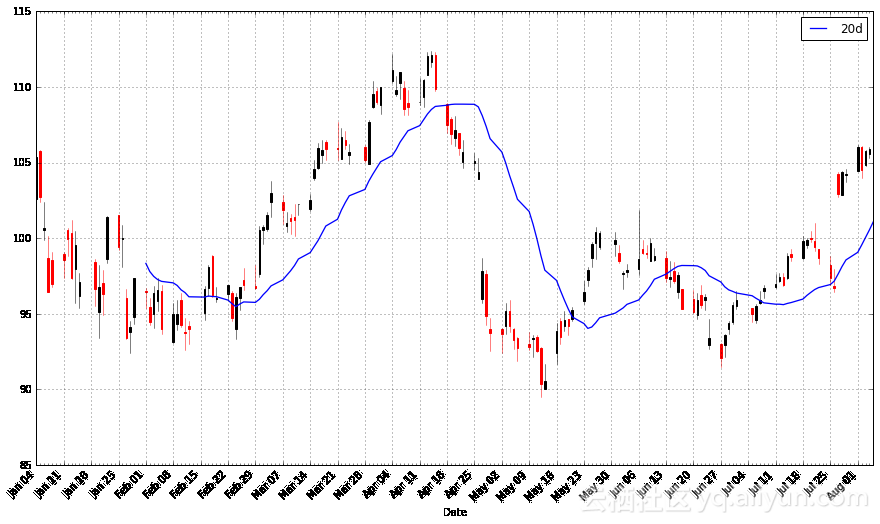
注意滚动均值是从什么时候开始的。只有在积累了20天的交易日数据之后,我们才能计算股票的20天均线。这个限制对于长期均线而言更加严重。如果我们想要计算股票的200天均线,我们需要多少苹果公司的股票数据才行?在这里,我们将主要关注2016年的股票走势。
start = datetime.datetime(2010,1,1)
apple = web.DataReader("AAPL", "yahoo", start, end)
apple["20d"] = np.round(apple["Close"].rolling(window = 20, center = False).mean(), 2)
pandas_candlestick_ohlc(apple.loc['2016-01-04':'2016-08-07',:], otherseries = "20d")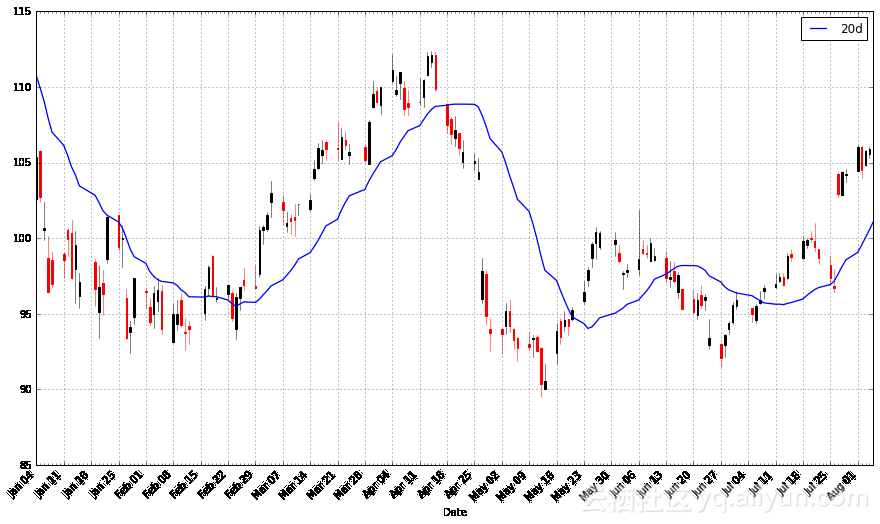
你会注意到,移动均线要比实际的股票数据平滑得多。此外,这是一个难以处理的标志;股票需要在移动均线的上方或下方,以便改变股票走势的方向。因此,股票走势越过移动均线的情况表明了股票一种可能的走向,应该引起我们的注意。
交易员通常对多条移动均线感兴趣,比如20天均线、50天均线以及200天均线。同时检查多条移动均线也很容易。
apple["50d"] = np.round(apple["Close"].rolling(window = 50, center = False).mean(), 2)
apple["200d"] = np.round(apple["Close"].rolling(window = 200, center = False).mean(), 2)
pandas_candlestick_ohlc(apple.loc['2016-01-04':'2016-08-07',:], otherseries = ["20d", "50d", "200d"])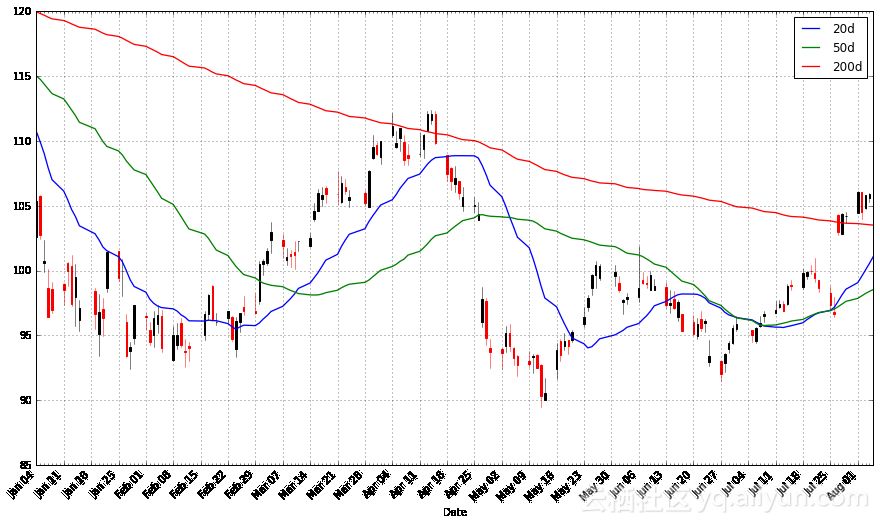
其中,20天均线对局部变化最为敏感,而200天均线对局部变化最不敏感。在这里,200天均线表明股票整体呈熊市行情:股票随着时间的推移趋势向下。20天均线有时呈熊市行情,而在其他时候呈牛市行情,预期股票会出现积极的波动。你还可以看到,移动均线的交叉表示着股票趋势的变化。我们将这些交叉看作交易信号或指示器,表示金融证券正在改变趋势,我们可能从中获取利润。
下周我将发布第二部分的文章,介绍如何基于移动均线设计并测试一个交易策略。
更正:本篇文章的早期版本提到过算法交易是高频交易的同义词。正如评论所指出的,实际情况并不是这样;算法也能用于处理非高频率的交易。尽管高频交易在算法交易中占很大比例,但二者并不相等。
数十款阿里云产品限时折扣中,赶紧点击领劵开始云上实践吧!
文章原标题《An Introduction to Stock Market Data Analysis with Python (Part 1)》,作者:Curtis Miller,译者:6816816151
文章为简译,更为详细的内容,请查看原文

