今天偶尔看到sql中也有with关键字,好歹也写了几年的sql语句,居然第一次接触,无知啊。看了一位博主的文章,自己添加了一些内容,做了简单的总结,这个语句还是第一次见到,学习了。我从简单到复杂地写,希望高手们不要见笑。下面的sql语句设计到三个表,表的内容我用txt文件复制进去,这里不妨使用上一个随笔介绍的建立端到端的package的方法将这些表导入到数据库中,具体的就不说了。
从这里下载文件employees.txt,customers.txt,orders.txt
参考文章:http://www.cnblogs.com/wwan/archive/2011/02/24/1964279.html
使用package导入数据:http://www.cnblogs.com/tylerdonet/archive/2011/04/17/2017471.html
简单的聚合
从orders表中选择各个年份共有共有多少客户订购了商品
- 第一种写法,我们可以写成这样
要注意的是如果把group by YEAR(o.orderdata)换成group by orderyear就会出错,这里涉及到sql语句的执行顺序问题,有时间再了解一下1 select YEAR (o.orderdate) orderyear, COUNT ( distinct (custid)) numCusts
2 from Sales.Orders o
3 group by YEAR (o.orderdate)
4 go - 第二种写法,
在from语句中先得到orderyear,然后再select语句中就不会出现没有这个字段的错误了1 select orderyear, COUNT ( distinct (custid))numCusts
2 from ( select YEAR (orderdate) as orderyear,custid from sales.orders) as D
3 group by orderyear
4 go - 第三种写法,
在as D后面加上选择出的字段,是不是更加的清楚明了呢!1 select orderyear, COUNT ( distinct (custid)) numCusts
2 from ( select YEAR (orderdate),custid from sales.orders) as D(orderyear,custid)
3 group by orderyear
4 go - 第四种写法,with出场了
with可以使语句更加的经凑,下面是权威解释。1 with c as (
2 select YEAR (orderdate) orderyear, custid from sales.orders)
3 select orderyear, COUNT ( distinct (custid)) numCusts from c group by orderyear
4 go
指定临时命名的结果集,这些结果集称为公用表表达式 (CTE)。该表达式源自简单查询,并且在单条 SELECT、INSERT、UPDATE、MERGE 或 DELETE 语句的执行范围内定义。该子句也可用在 CREATE VIEW 语句中,作为该语句的 SELECT 定义语句的一部分。公用表表达式可以包括对自身的引用。这种表达式称为递归公用表达式。
----MSDN
- 第五种写法,也可以借鉴第三种写法,这样使语句更加清楚明了,便于维护
上面5中写法都得到相同的结果,如下图1:1 with c(orderyear,custid) as (
2 select YEAR (orderdate),custid from sales.orders)
3 select orderyear, COUNT ( distinct (custid)) numCusts from c group by c.orderyear
4 go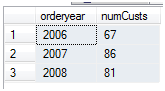 图1
图1
添加计算
- 现在要求要求计算出订单表中每年比上一年增加的客户数目,这个稍微复杂
这里两次使用到with结果集。查询得到的结果如下图21 with yearcount as (
2 select YEAR (orderdate) orderyear, COUNT ( distinct (custid)) numCusts from sales.orders group by YEAR (orderdate))
3 select cur.orderyear curyear,cur.numCusts curNumCusts,prv.orderyear prvyear,prv.numCusts prvNumCusts,cur.numCusts - prv.numCusts growth
4 from yearcount cur left join yearcount prv on cur.orderyear = prv.orderyear + 1
5 go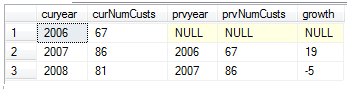
图2
复杂的计算
- 查找客户id,这些客户和所有来自美国的雇员至少有一笔交易记录,查询语句如下
这里嵌套with语句,第with语句查找美国雇员的id,第二个语句使用这个结果和拥有客户的客户id和拥有关系标识做笛卡尔积运算。最后从这个笛卡尔积中通过标识找到最终的custid。1 with TheseEmployees as (
2 select empid from hr.employees where country = ' USA ' ),
3 CharacteristicFunctions as (
4 select custid,
5 case when custid in ( select custid from sales.orders as o where o.empid = e.empid) then 1 else 0 end as charfun
6 from sales.customers as c cross join TheseEmployees as e)
7 select custid, min (charfun) from CharacteristicFunctions group by custid having min (charfun) = 1
8 go
结果如下图3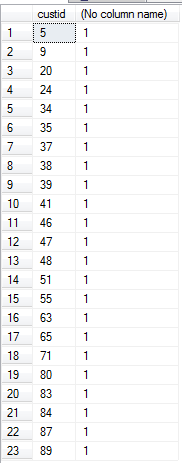
图3
这里只有简单地介绍,没有深入,高手们不要见笑啊。
---------------------------------------------------------分界线----------------------------------------------------------
with语句和子查询的性能比较
在博友SingleCat的提醒下,对with语句做一些性能测试,这里使用的测试工具是SQL Server Profile。我选择了最后一个语句,因为这个语句比较复杂一点。开始的时候单独执行一次发现他们的差别不大,就差几个毫秒,后来想让他们多执行几次,连续执行10
次看看执行的结果。下面贴出测试用的语句。
2 declare @withquery varchar ( 5000 )
3 declare @execcount int = 0
4 set @withquery = ' with TheseEmployees as(
5 select empid from hr.employees where country=N '' USA '' ),
6 CharacteristicFunctions as(
7 select custid,
8 case when custid in (select custid from sales.orders as o where o.empid=e.empid) then 1 else 0 end as charfun
9 from sales.customers as c cross join TheseEmployees as e)
10 select custid from CharacteristicFunctions group by custid having min(charfun)=1 order by custid
11 '
12 while @execcount < 10
13 begin
14 exec ( @withquery );
15 set @execcount = @execcount + 1
16 end
17
18 /* 子查询 */
19 declare @subquery varchar ( 5000 )
20 declare @execcount int = 0
21 set @subquery = ' select custid from Sales.Orders where empid in
22 (select empid from HR.Employees where country = N '' USA '' ) group by custid
23 having count(distinct empid)=(select count(*) from HR.Employees where country = N '' USA '' );
24 '
25 while @execcount < 10
26 begin
27 exec ( @subquery );
28 set @execcount = @execcount + 1
29 end
从SQL Server Profile中截图如下

从图中可以看到子查询语句的执行时间要少于with语句,我觉得主要是with查询中有一个cross join做了笛卡尔积的关系,于是又实验了上面的那个简单一点的,下面是测试语句。
2 declare @withquery varchar ( 5000 )
3 declare @execcount int = 0
4 set @withquery = ' with c(orderyear,custid) as(
5 select YEAR(orderdate),custid from sales.orders)
6 select orderyear,COUNT(distinct(custid)) numCusts from c group by c.orderyear '
7 while @execcount < 100
8 begin
9 exec ( @withquery );
10 set @execcount = @execcount + 1
11 end
12
13 /* 子查询 */
14 declare @subquery varchar ( 5000 )
15 declare @execcount int = 0
16 set @subquery = ' select orderyear,COUNT(distinct(custid)) numCusts
17 from (select YEAR(orderdate),custid from sales.orders) as D(orderyear,custid)
18 group by orderyear '
19 while @execcount < 100
20 begin
21 exec ( @subquery );
22 set @execcount = @execcount + 1
23 end
这次做10次查询还是没有多大的差距,with语句用10个duration,子查询用了11个,有时候还会翻过来。于是把执行次数改成100,这次还是子查询使用的时间要少,截图如下
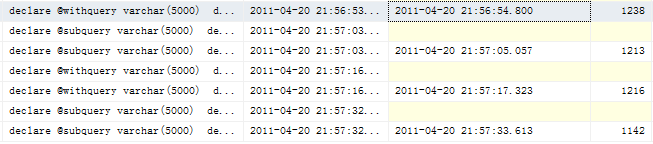
最终结论,子查询好比with语句效率高。
作者:Tyler Ning
出处:http://www.cnblogs.com/tylerdonet/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,如有问题,可以通过以下邮箱地址williamningdong@gmail.com 联系我,非常感谢。