透视
今天抽一点时间来看看透视和逆透视语句,简单的说就是行列转换。假设一个销售表中存放着产品号,产品折扣,产品价格三个列,每一种产品号可能有多种折扣,每一种折扣只对应一个产品价格。下面贴出建表语句和插入数据语句。
2 ProductID int /* unique多谢wuu00的提醒*/ ,
3 UnitPriceDiscount float ,
4 ProductPrice float
5 )
6 insert into SalesOrderDetail values
7 ( 711 ,. 00 , 12 ),
8 ( 711 ,. 00 , 13 ),
9 ( 711 ,. 02 , 17 ),
10 ( 711 ,. 02 , 16 ),
11 ( 711 ,. 05 , 19 ),
12 ( 711 ,. 05 , 20 ),
13 ( 711 ,. 10 , 21 ),
14 ( 711 ,. 10 , 22 ),
15 ( 711 ,. 15 , 23 ),
16 ( 711 ,. 15 , 24 ),
17 ( 747 ,. 00 , 41 ),
18 ( 747 ,. 00 , 42 ),
19 ( 747 ,. 02 , 45 ),
20 ( 747 ,. 02 , 46 ),
21 ( 776 ,. 20 , 50 ),
22 ( 776 ,. 20 , 49 ),
23 ( 776 ,. 35 , 52 ),
24 ( 776 ,. 35 , 53 )
首先来看一条查询语句
2 from SalesOrderDetail
3 group by ProductID,UnitPriceDiscount
4 order by ProductID,UnitPriceDiscount
这条语句查询每一种产品针对每一种折扣的价钱总和,查询结果如下图1
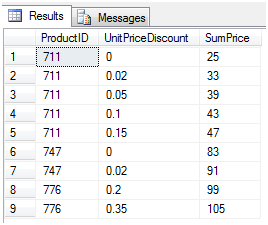
图1
从图中我们可以看出771号产品有4种折扣,747号产品有2种折扣,776号产品有2种折扣。现在如果我们想知道每一种产品折扣,每一种产品的销售总价是多少,如下图2
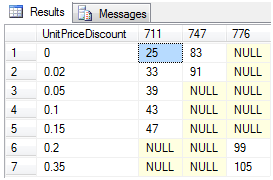
图2
如图对于折扣0,产品711的总价是25,对以折扣0.02,产品711的总价是33等等不再列举。原来的行是产品号,现在产品号变成了列,原来的折扣变成了现在的第一列。这就是数据透视的效果。下面我们开看看是这个效果是如何用语句实现的。
2 ( select sod.ProductPrice,sod.ProductID,sod.UnitPriceDiscount from SalesOrderDetail sod) so
3 pivot
4 (
5 sum (so.ProductPrice) for so.ProductID in ( [ 711 ] , [ 747 ] , [ 776 ] )
6 ) as pt
7 order by UnitPriceDiscount
首选创建子查询(select sod.ProductPrice,sod.ProductID,sod.UnitPriceDiscount from SalesOrderDetail sod) so ,透视运算符要使用这个子查询中的数据进行聚合运算,此外输出显示也要用到子查询中的列。代码生成一个别名为so的表值表达式。在这个表中使用pivot在特定的列上进行聚合,这里是对so.ProductPrice进行聚合,聚合针对so.ProductID进行。在这个例子中对三种产品的中的每一种创建一个列。这个相当于group by,从so表达式中进行数据筛选。不过这里没有选出ProductPrice,仅仅生成每行三个列,每一种产品为一个列的结果集。因此带有povit的表值表达式生成一个临时的结果集,将这个结果集命名为pt,使用这个结果集生成我们需要的输出。如果想要得到一个更加合适的列名可以修改筛选条件。如下:
2 ( select sod.ProductPrice,sod.ProductID,sod.UnitPriceDiscount from SalesOrderDetail sod) so
3 pivot
4 (
5 sum (so.ProductPrice) for so.ProductID in ( [ 711 ] , [ 747 ] , [ 776 ] )
6 ) as pt
7 order by UnitPriceDiscount
输出的结果如下图3
图3
逆透视
这次我们首先看语句和查询结果再分析,语句如下:
2 from
3 ( select UnitPriceDiscount,Product711,Product747,Product776 from #Temp1) as up1
4 unpivot(ProductPrice for ProductID in (Product711,Product747,Product776)) as up2
5 order by ProductID
查询结果如下图4:
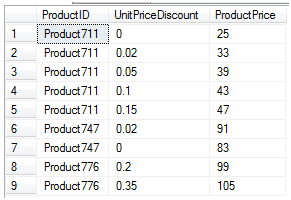
图4
首先我们来看看逆透视得到了一个什么样的结果。对于每一种产品的每一种折扣查询得到他们的合计售价,这个和上面图1中的结果是一样的,是的,它和透视之前的结果是相同的。逆透视和透视并不是完全相反。Pivot会执行聚合,把可能存在的多个行合并输出得到一行。由于已经进行了合并,unpivot无法重新生成原始的表值表达式,unpivot输入中的null值将在输出中消失,尽管在pivot操作之前输入中可能存在原始的null值。如图5是他们的比较。在图中我们可以看到NULL值下面一个图中没有NULL值,刚好有9行。下图把他们放在一起比较。
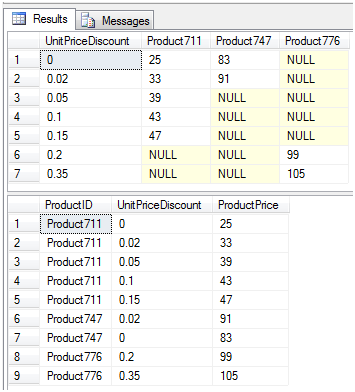
图5
下面我们来剖析一下上面的语句到底做了些什么。首先是一个表值函数(select UnitPriceDiscount,Product711,Product747,Product776 from #Temp1) as up1,这个表值函数从透视结果,也就是临时表中,然后针对每一个产品号进行逆透视:unpivot(ProductPrice for ProductID in(Product711,Product747,Product776)) as up2,然后从逆透视结果中选择ProductID ,ProductPrice,从表值函数中选择UnitPriceDiscount。
延伸阅读
一个例子还不足以让我们理解这个语句,下面来看看TechNet中的例子。
SELECT DaysToManufacture, AVG(StandardCost) AS AverageCost FROM Production.Product
GROUP BY DaysToManufacture;
这个语句查出Product表中的制造时间和平均成本,得到如下的结果
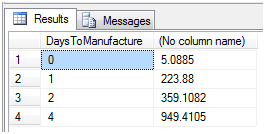
图6
如图可以看到没有制造时间为3天的产品,这里留下一个伏笔,在透视之后会出现一个NULL值。下面使用透视语句对它进行行列转换,就是使用0,1,2,3来作为列,使用具体的制造成本作为行数据。语句如下
2 'AverageCost' as Cost_Sorted_By_Production_Days,
3 [0],[1],[3],[4]
4 from
5 (select DaysToManufacture,StandardCost from Production.Product) as SourceTable
6 pivot
7 (avg(StandardCost) for DaysToManufacture in ([0],[1],[3],[4])) as PivotTable
依旧,首先用一个表值表达式把要透视的列和透视的项选择出来,然后使用透视语句针对每一个项计算平均成本,最后从这个透视结果中选择出结果。
结果如下图7,我们可以看到制造时间为3天的产品没有一个对应的平均成本。
图7
下面这个例子稍微复杂一点。
2 FROM Purchasing.PurchaseOrderHeader group by VendorID
这条语句查询得到每个供应商和他对应的交易号的个数,也就是每个供应商成交的交易次数。如图8列举出部分结果
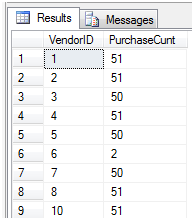
图8
从图中我们可以看到供应商1共成交51比交易,供应商2共成交51笔交易。如果我们想查出这些交易分别是和那些雇员成交的应该怎么写呢?首先我们来看看表中全部的雇员情况。
select distinct(EmployeeID) from Purchasing.PurchaseOrderHeader
查询结果如图9
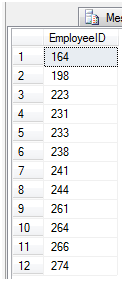
图9
如上图我们可以看到共有12个雇员有成交记录。对于这些雇员,如下查询语句
2 VendorID,
3 [164] AS Emp164,
4 [198] AS Emp198,
5 [223] AS Emp223,
6 [231] AS Emp231,
7 [233] AS Emp233,
8 [238] as Emp238,
9 [241] as Emp241,
10 [244] as Emp244,
11 [261] as Emp261,
12 [264] as Emp264,
13 [266] as Emp266,
14 [274] as Emp274
15 FROM
16 (SELECT PurchaseOrderID,EmployeeID,VendorID
17 FROM Purchasing.PurchaseOrderHeader) p
18 PIVOT
19 (
20 COUNT (PurchaseOrderID)
21 FOR EmployeeID IN
22 ( [164], [198], [223], [231],[233],[238],[241],[244],[261],[264],[266],[274])
23 ) AS pvt
24 ORDER BY pvt.VendorID;
查询结果如下图10
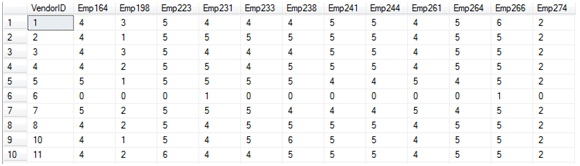
图10
可以 简单地计算一下1+4+3+5+4+4+4+5+5+4+5+6+2刚好等于51,分开来看就是1号供应商分别和164号雇员成交4比记录,和198号雇员成交3比记录等等。
作者:Tyler Ning
出处:http://www.cnblogs.com/tylerdonet/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,如有问题,可以通过以下邮箱地址williamningdong@gmail.com 联系我,非常感谢。