错误输出可以用来提高可靠性,但是它还有一个目的是改善可扩展性。可靠性方面,他们可以用来拷贝出错误数据。通过合适的配置可以将错误的数据从主要数据流中分离出来输出到下游系统中。这些数据将会特别处理或者是被清洗然后返回到主数据流中。他们可以被显示地合并,例如使用Union转换,或者是隐式地合并数据很少被丢弃,很多时候他们被记入日志中或者在后续步骤中处理。
如果一些数据在析取的时候丢失,但是最终还是需要这些数据,错误输出可以用来解决这个问题。如果可以在其他的数据源中获得这些错误数据,可以使用LookUp转换找到这些数据。如果不能再其他的地方获得这些,可以使用默认值选项配置。
在另外一些场景中,数据可能超出处理范围或者目标容器的范围,如果这些数据造成完整性验证错误,可以使用一些依赖约束获得新的数据,进而这些数据可以正常地处理。如果数据类型出现冲突,可以简单的使用截断处理,也可以使用一套额外的逻辑来处理,例如将时间转换成特殊的格式。
当对数据进行类似这样的假设和处理之后,要进行适当的标记或者解释说明,这样当后续有新的需求的时候就可以有所参照,或者其他的使用者参照。
上面所有的场景都是围绕着恢复脏数据,维持数据流的持续处理,尽量将错误数据恢复出来。和DTS比较起来这是一个新的概念,在处理数据的时候实时地处理错误数据是一个很有意义的工作。
还有一个问题:为什么不直接在主数据流中对这些数据进行转化处理进而避免出现错误呢?这就意味着所有的数据流只有一个流向,看起来更加简单,没有分支。事实上,如果能够一直使用最少的数据转换,最简单的数据流,这样越简单,可靠性和可扩展性就越高。
如图1实例。在这个人为的例子中SpecialtyCode和ConsultantCode列一些数丢失了。数据源中还有一个描述列,所以可以使用lookup来检索这是丢失的数据。最初的时候可能是使用Conditional Split转换将丢失的数据设置为NULL。一旦使用LookUp处理了这些Null值,就可以使用Union All转换来将他们重新合并到主数据流中。用这种方式处理SpecialtyCode和ConsultantCode两个列保证最终写入到目的中的数据全部都是合适的数据。这种方法是处理这类问题的最好方法。
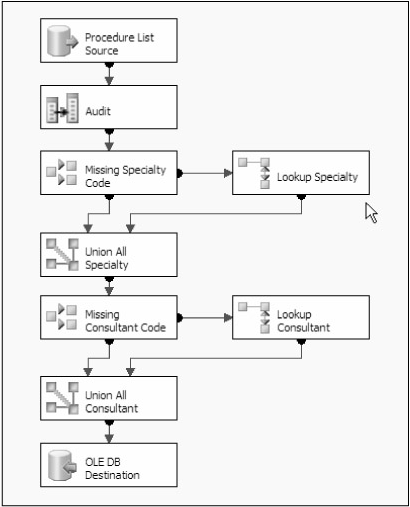
图1
如图2是两种可选的数据流设计。在第一种设计中忽略掉SpecialtyCode和ConsultantCode的所有可能出现的问题直接使用LookUp来处理,看上去可能会有点费力,但是所有的步骤更加简单,他要比图2中的设计快2%。这个结果是使用1/3缺陷的测试数据得到的,就是3行数据中就有1行数据,SpecialtyCode列或者ConsultantCode列有缺失。如果缺失率是1/6二者的效率是相同的。
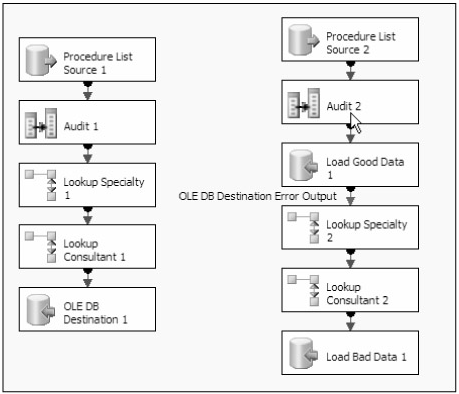
图2
第二种设计假设所有的数据没有缺陷,所以直接写入到目的。如果出现错误数据会被写入到错误输出中,OLE DB Destination Error OutPut,然后通过两个LookUp来处理。这两种设计的区别是:是否只处理有问题的行还是对所有的列都进行处理。使用1/3缺陷几率的测试文件,只处理有问题的行会快20%,当缺陷几率是1/6的时候会有所下降只有10%。
通过上面的例子我们可以看到,具体选择哪种设计要依据测试文件或者测试数据的缺陷率。
这里矫正数据的性能表现也应考虑在内。在上面的例子中,使用LookUp是一个非常昂贵的转换。在测试数据中和LookUp参照表中只有6条不重复的数据,这样见笑对整个测试性能的影响。在参照表中如果有更多的不重复值,对性能的影响更大,更多的数据会需要更多的缓存,会耗费更多的资源。
对数据验证越严格,就要处理更多的缺陷数据。对于缺陷数据较少的,或者昂贵的验证过程,尽量使判断流程简单,使用错误输出来处理那些缺陷数据。
所有数据的行数也会影响数据流的设计,因为任何的优点和缺点都会影响大量的数据。如果数据量较小,肯能占用的资源较少,但在运行的时候任何转换都会有资源损耗,所以更加复杂的设计在数据量较少的时候则可能得不偿失。
这种使用错误输出的方式和在主数据流中纠正数据都可以使用,没有限制。你尽可以使用图2中的那种处理方式。保证尽量少的数据流向代价昂贵的处理流程,多数的数据流向主要流程中。
最后,不要拒绝使用错误输出。开发者可能会经常使用那些复杂的,高级的转换,但要记住,错误输出是一种最简单的方式处理错误的数据,他们不会影响包中的其他转换,所以不要拒绝使用错误输出。
这里所说的改善性能只是一个引导作用,这里只是介绍设计方式的不同,不要将它作为教条来执行,除非你遇到完全相同的场景,相同的数据,相同的问题。唯一不变的原则是进行对比测试,然后得出更好的设计。
作者:Tyler Ning
出处:http://www.cnblogs.com/tylerdonet/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,如有问题,可以通过以下邮箱地址williamningdong@gmail.com 联系我,非常感谢。