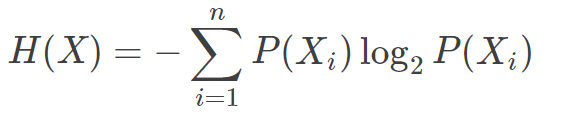表达式
输出标签表示为{0,1}时,损失函数表达式为:
$L = -[y log \hat{y} + (1-y)log(1- \hat{y})]$
二分类
二分类问题,假设 y∈{0,1}
正例:$P(y = 1| x) = \hat{y}$ 公式1
反例:$P(y=0|x) = 1-\hat{y}$ 公式2
联立
将上述两式连乘。
$P(y|x) = \hat{y}^{y} * (1-\hat{y})^{(1-y)}$ ;其中y∈{0,1} 公式3
当y=1时,公式3和公式1一样。
当y=0时,公式3和公式2一样。
取对数
取对数,方便运算,也不会改变函数的单调性。
$ logp(y|x) =ylog\hat{y} + (1-y)log(1-\hat{y})$ 公式4
我们希望$P(y|x)$越大越好,即让负值$-logP(y|x)$越小越好,得到损失函数为:
$L = -[y log \hat{y} + (1-y)log(1- \hat{y})]$ 公式5
参考阅读
《简单的交叉熵损失函数,你真的懂了吗?》
《确定不收藏?机器学习必备的分类损失函数速查手册》
补充
上面说的都是一个样本的时候,多个样本的表达式是:
多个样本的概率即联合概率,等于每个的乘积。
$p(y|x) = \prod _{i}^{m} p(y^{(i)}| x^{(i)})$
$log p(y|x) = \sum _{i}^{m} log p(y^{(i)}| x^{(i)})$
由公式4和公式5得到
$logp(y^{(i)}| x^{(i)}) = - L(y^{(i)}| x^{(i)})$
$ logp(y^{(i)}| x^{(i)})=-\sum _{i}^{m}L(y^{(i)}| x^{(i)}) $
加上$\frac{1}{m}$对式子进行缩放,便于计算。
Cost (min) : $J(w,b) =\frac{1}{m}\sum _{i}^{m} L(y^{(i)}| x^{(i)}) $
或者写作:
$J = - \frac{1}{m}\Sigma_{i=1}^{m}[y^{(i)} log \hat{y}^{(i)} + (1-y^{(i)})log(1- \hat{y}^{(i)})]$
扩展
交叉熵和KL散度有着密切联系。
https://blog.csdn.net/haolexiao/article/details/7014257