Spark Streaming作为Spark上的四大子框架之一,肩负着实时流计算的重大责任
而相对于另外一个当下十分流行的实时流计算处理框架Storm,Spark Streaming有何优点?又有何不足呢?
首先,对于Storm实时流处理惊人的低延迟性,Spark Streaming的不足很明显
Storm官方说的最低延迟可以使多少毫秒级别的
而Spark Streaming只能做到压秒,也就是零点几秒
相对于Storm的实时性来说,Spark Streaming甚至只能说是准实时的
But,Spark Streaming虽然在延迟性方面比不过Storm,但是Spark Streaming有太多太多的优点,以至于能够让人的注意力从Storm转移到Spark Streaming身上
第一,Spark Streaming是Spark的核心子框架之一。
说到Spark核心,那就不得不说RDD了。
Spark Streaming作为核心的子框架,对RDD的操作支持肯定是杠杠的,这又说明了什么?
Spark Streaming可以通过RDD和Spark上的任何框架进行数据共享和交流,这就是Spark的野心,一个堆栈搞定所有场景
第二,虽然Spark Streaming的延迟性比不过Storm,但是Spark Streaming也有自己的优势,那就是巨大的吞吐量,这点是Storm所比不上的
第三,由于Spark上子框架的编程模型基本都是一个套路,所以Spark Streaming的API也是十分易于掌握的
第四,Spark Streaming支持多语言编程,并且各个语言之间的编程模型也是类似的
第五,Spark Streaming的容错机制。Spark Streaming在读取流数据进入内存的时候会保存两个副本,计算只用一个,当出现问题的时候可以快速的切换到另外一个副本;在规定的时间内进行数据的固化;由于支持RDD操作,所以RDD本身的容错处理机制也被继承
Spark Streaming的处理过程:
- 以时间片为单位划分形成数据流形成RDD(DStream)
- 对每个划分数来的RDD以批处理的方式处理数据
- 每个划分出来的RDD地处理都会提交成Job
比较适用的场景:
- 历史数据和实时数据结合进行分析
- 对实时性要求不是很苛刻的场景
重要的组件:
- Job Scheduler:周期性查询DStream生成的DAG图,将其转换为Job提交到Job Manager
- Job Manager:维护Job队列,将Job提交到Spark运行
一些调优方式:
1、运行时间调优
- 并行度优化,确保任务使用集群所有资源,防止数据倾斜
- 减少数据序列化、反序列化的次数
- 合理调整批处理窗口
2、空间占用调优
- 定时清理不用的数据
- 控制批处理量,确保当前节点Spark的可用内存能够容纳这个batch窗口的所有数据
下面给出一个Spark Streaming的简单实例代码:
//根据sparkConf(spark配置信息)和Seconds(多少秒处理一次流数据)创建一个StreamingContext对象
val ssc = StreamingContext(sparkConf,Seconds(1))
//调用ssc的socketTextStream根据参数接收指定地址的数据,根据ssc的Seconds参数配置决定多长时间处理一次。这里的socketTextStream是专门处理socket数据的方法,对于其他数据来源,例如Flume,Kafka,Twitter等都有专门的方法来处理
val lines = ssc.socketTextStream(servIp,servPort)
//对每一行数据进行分割
val words = lines.flatMap(_.Split(" "))
//统计word的数量
val pairs = words.map(word => (word,1))
val wordCounts = pairs.reduceByKey(_ + _)
//输出结果
wordCounts.print()
//开始
ssc.start()
//计算完毕退出
ssc.waitTermination()从以上代码中就很明显的可以看出Spark Streaming的编程模型和Spark上的其他子框架是差不多的,只不过针对实时流处理多了一些自身的操作而已
在执行这行代码的时候
val lines = ssc.socketTextStream(servIp,servPort)lines其实是一个DStream的RDD对象
每一秒流进来的数据都会被处理成DStream对象,也就是一个个lines
在处理流进来的数据时,Spark Streaming是串行处理的,也就是说,当前面这个DStream在一秒之内还没有被处理完毕时,新的数据来了,那么此时的新数据会被阻塞住,直至当前的DStream处理完毕之后才处理下一个数据
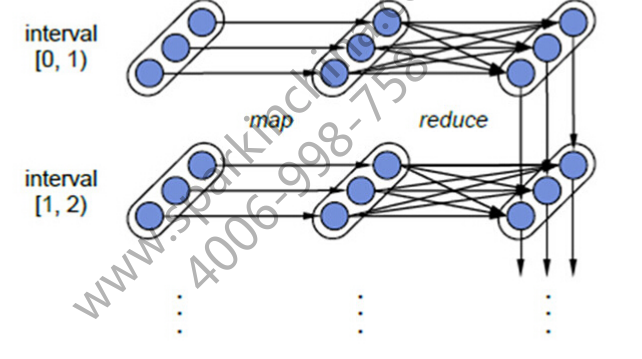
如同上图所示,interval[0,1)和interval[1,2)是串行执行的,当interval1执行完毕(经过reduce操作到达第三个阶段时),才会处理interval2
但是我们可以看到每一行的产生的结果,也就是第三个阶段之间也会进行一些操作运算,这时是交给Spark内核引擎来并行处理的
对于串行引起的阻塞问题就涉及到Spark Streaming的一些优化了,如,Batch Size,每个数据分块的大小应该分为多少才会在规定的时间内处理完毕而不会引起阻塞?
答案是没有最好的Size,只有最合适的Size。
一切都是根据当前系统的状况来进行决定的,以系统反馈的数据说话




