这个问题有一个简短的答案,让我们从那里开始吧。然后,我们可以查看一个应用程序以获得更深入的了解。
矩阵是由括号括起的n×m(例如,3×3)个数字的网格。我们可以加上和减去相同大小的矩阵,只要大小兼容((n×m)×(m×p)= n×p),就将一个矩阵与另一个矩阵相乘,以及可以将整个矩阵乘以常数。向量是一个只有一行或一列的矩阵(但见下文)。因此,我们可以对任何矩阵进行一系列数学运算。
不过,基本的思想是,矩阵只是一个二维的数字网格。
张量通常被认为是一个广义矩阵。也就是说,它可以是1-D矩阵(一个向量实际上就是一个张量),3-D矩阵(类似于一个数字的立方),甚至是0-D矩阵(单个数字),或者一个更难形象化的高维结构。张量的维数叫做它的秩。
但是这个描述忽略了张量最重要的性质!
张量是一个数学实体,它存在于一个结构中并与其他数学实体相互作用。如果以常规方式转换结构中的其他实体,那么张量必须服从一个相关的变换规则。
张量的这种“动态”特性是将其与单纯矩阵区分开来的关键。它是一个团队成员,当一个影响到所有成员的转换被引入时,它的数值会随着队友的数值而变化。
任何秩-2张量都可以表示为一个矩阵,但并不是每个矩阵都是秩-2张量。张量矩阵表示的数值取决于整个系统应用了什么变换规则。
对于您的目的,这个答案可能已经足够了,但是我们可以通过一个小例子来说明它是如何工作的。这个问题是在一个深度学习研讨会上提出的,所以让我们看一下该领域的一个简单例子。
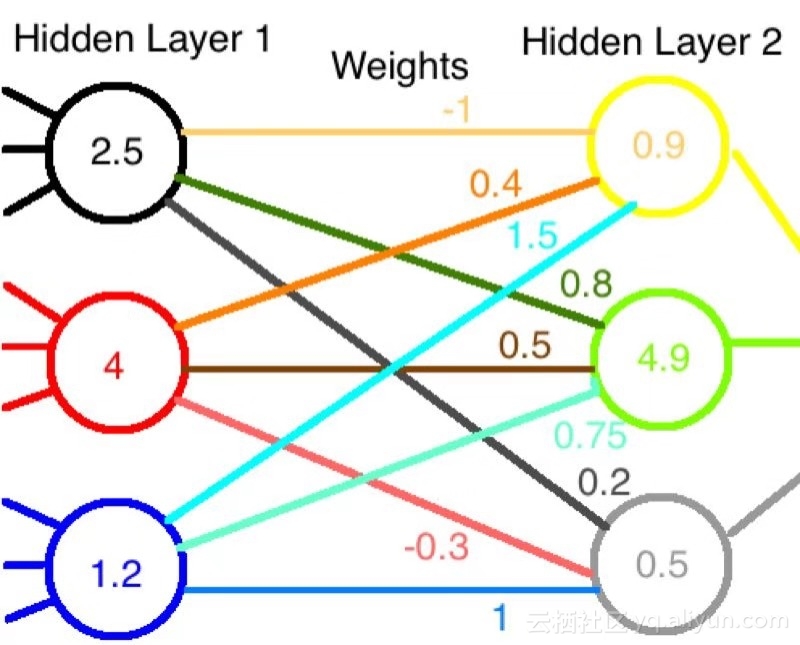
假设我在神经网络中有一个隐藏的3个节点层。数据流入它们,通过它们的ReLU函数,然后弹出一些值。对于确定性,我们分别得到2.5,4和1.2。 (别担心,图表即将出现。)我们可以将这些节点的输出表示为向量,
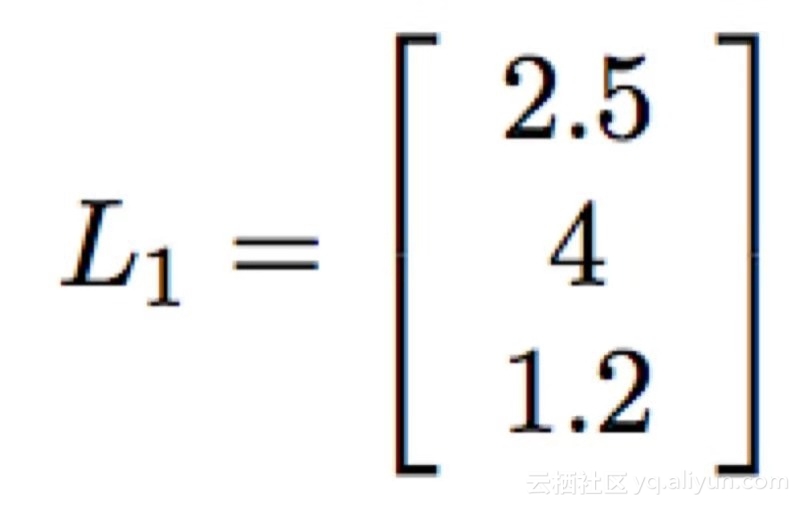
假设有另外一层3个节点。第一层的3个节点中的每个节点都有一个权重,该权重与其对接下来3个节点的输入相关联。那么,将这些权重写为3×3矩阵的条目将是非常方便的。假设我们已经对网络进行了多次更新,并得到了权重(本例中半随机选择)。
在这里,一行的权值都到下一层的同一个节点,而某一列的权值都来自第一层的同一个节点。例如,输入节点1对输出节点3的权值是0.2(第3行,第1列)。 我们可以通过将权重矩阵乘以输入向量来计算馈入下一层节点的总值,
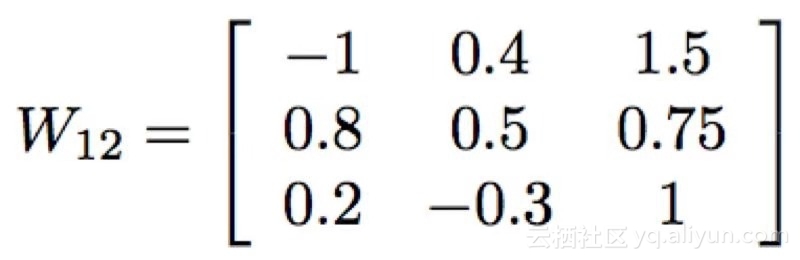
不喜欢矩阵?这里有一个图。数据从左到右流动。

太棒了!到目前为止,我们所看到的只是矩阵和向量的一些简单操作。
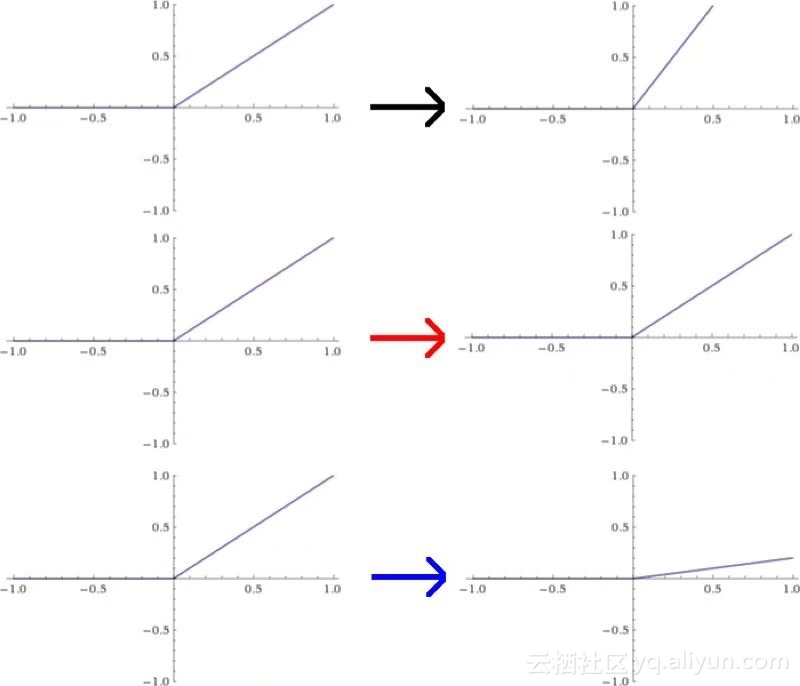
但是,假设我想对每个神经元进行干预并使用自定义激活函数。一种简单的方法是从第一层重新缩放每个ReLU函数。在本例中,假设我将第一个节点向上扩展2倍,保留第二个节点,将第三个节点向下扩展1/5。这将改变这些函数的图形如下图所示:
这种修改的效果是将第一层生成的值分别乘以2、1和1/5。等于L1乘以一个矩阵A,
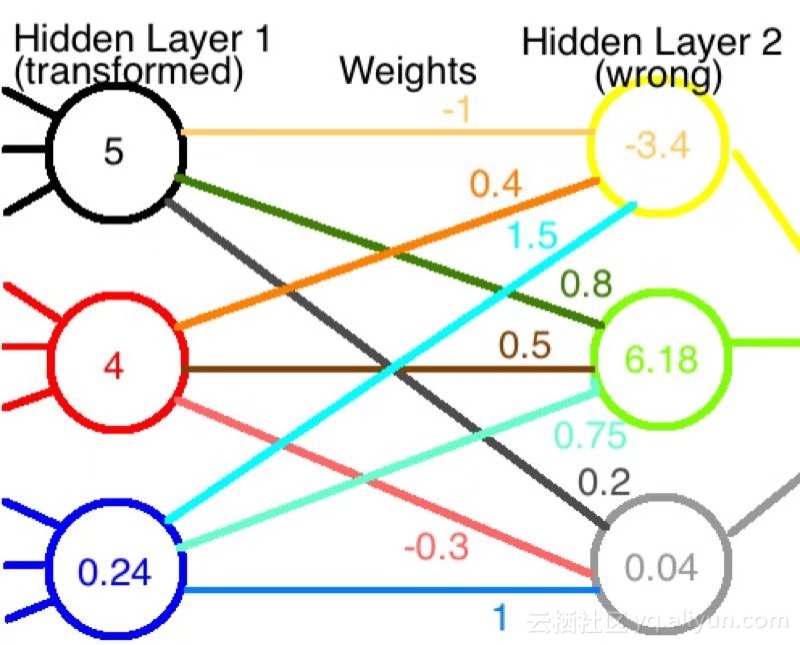
现在,如果这些新值通过原来的权值网络被输入,我们得到完全不同的输出值,如图所示:

如果神经网络之前运作正常,我们现在就把它破坏了。我们必须重新进行训练以恢复正确的重量。
或者我们会吗?
第一个节点的值是之前的两倍。 如果我们将所有输出权值减少1/2,则它对下一层的净贡献不变。我们没有对第二个节点做任何处理,所以我们可以不考虑它的权值。最后,我们需要将最后一组权值乘以5,以补偿该节点上的1/5因子。从数学上讲,这相当于使用一组新的权值,我们通过将原权矩阵乘以A的逆矩阵得到:
如果我们将第一层的修改后的输出与修改后的权值结合起来,我们最终会得到到达第二层的正确值:
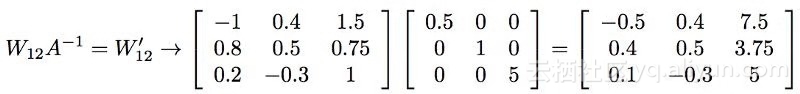
太好了!尽管我们做出了最大努力,但网络仍在重新运作!
好了,我们已经学了很多数学了,让我们回顾一下。
当我们把节点的输入,输出和权值看作固定的量时,我们称它们为向量和矩阵,并用它完成。
但是,一旦我们开始用其中一个向量进行修复,以常规方式对其进行转换,我们就必须通过相反的方式转换权值来进行补偿。这个附加的、集成的结构将单纯的数字矩阵提升为一个真正的张量对象。
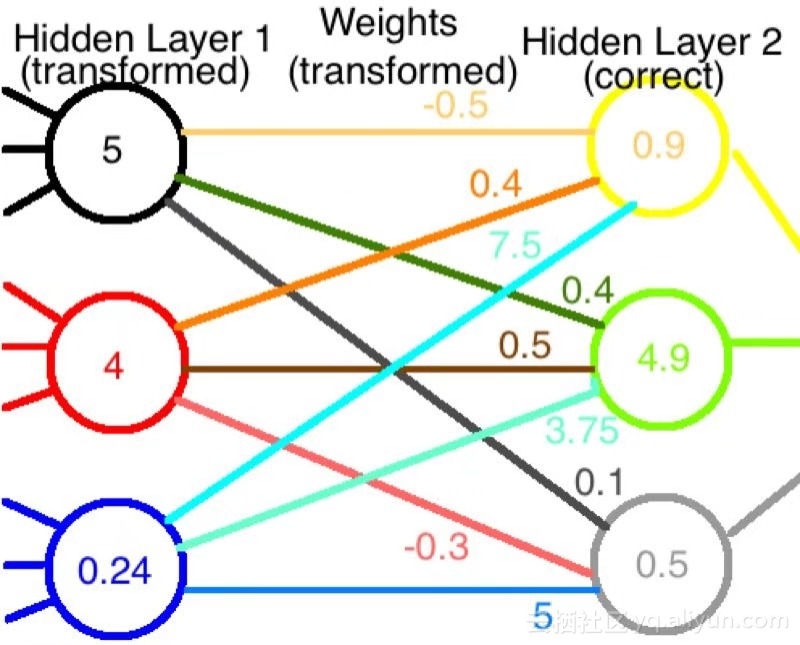
事实上,我们可以进一步描述它的张量性质。如果我们把对节点的变化称为协变(即,随着节点的变化而乘以A),那么权值就变成了一个逆变张量(具体来说,对节点变化,乘以A的倒数而不是A本身)。张量可以在一个维度上是协变的,在另一个维度上是逆变的,但那是另外的事了。
现在你知道了矩阵和张量之间的区别了吧。
本文由阿里云云栖社区组织翻译。
文章原标题《What’s the difference between a matrix and a tensor?》
作者:Steven Steinke 译者:Viola,审校:。
文章为简译,更为详细的内容,请查看原文。