之前我水平有限,对于淘宝评论这种动态网页,由于数据在网页源码中是找不到的,所以无法抓取数据,只能使用selenium模仿人操控浏览器来抓数据,
优点是可见容易且不宜被淘宝公司封锁;缺点是速度太慢。
经过今天一天的钻研,终于学会分析数据包,而且淘宝评论的数据包都是以json格式传输的。除了学会抓包,还要会从json中提取出想要的评论数据才行。
本文实现难点:
一、分析数据包,找到淘宝评论传输用的网址,分析网址特点
二、如何从找到的数据包中,从json格式内容中得到想要的数据
案例

https://detail.tmall.com/item.htm?id=38975978198&ali_refid=a3_430582_1006:1106461044:N:%E7%94%B5%E5%8A%A8%E7%89%99%E5%88%B7:bfee1d767fa0a91e5e853b29d794c6f2&ali_trackid=1_bfee1d767fa0a91e5e853b29d794c6f2&spm=a230r.1.14.1.R0FzCm打开该网址,点击评论
如图中红色圈中的评论,分析发现,在网页源码中查找不到。
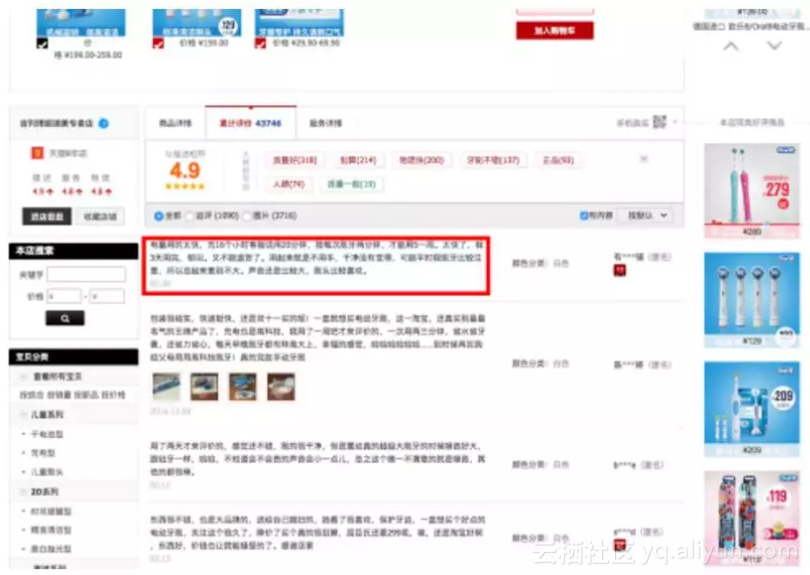
找啊找,找啊找,圈中的评论就是不在网页源码中。那只有一种可能,在我们看不到的方式传送。

用火狐浏览器,打开开发者工具,点击网络
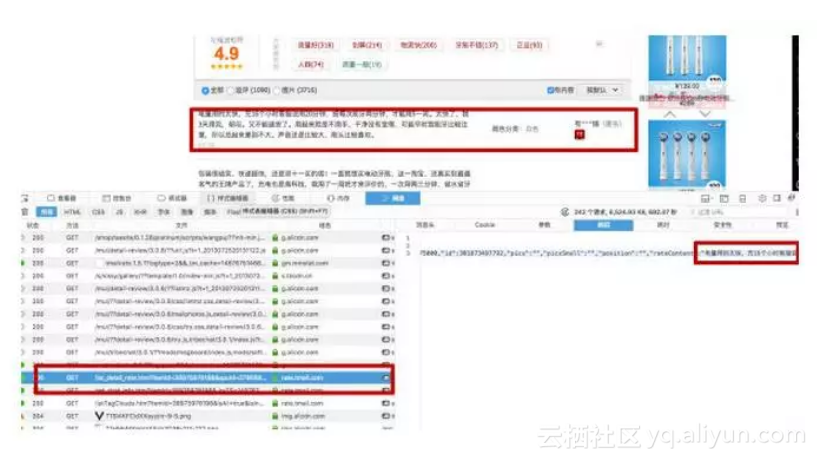
真的找到了啊
那么接下来我们要知道这个包传递信息的网址
点击消息头,红方框中的请求网址就是这个评论数据包传递的网址
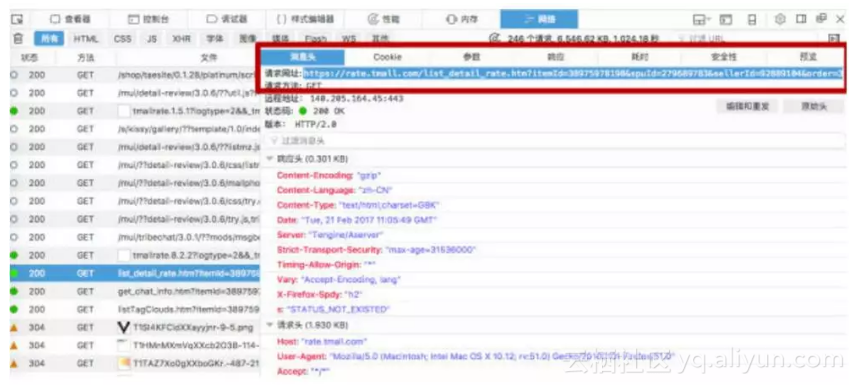
网址如下
https://rate.tmall.com/list_detail_rate.htm?itemId=38975978198&spuId=279689783&sellerId=92889104&order=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=250UW5TcyMNYQwiAiwTR3tCf0J/QnhEcUpkMmQ=|Um5Ockt+RH9FfEZ6QXpEcCY=|U2xMHDJ+H2QJZwBxX39RaVV7W3UyWzAeSB4=|VGhXd1llXGlTaFJrUW1WbVNnUG1PdkN7TnBNeUxzR3pFeEB/QG44|VWldfS0TMwc4BycbIwMtBn0AbSJNNl87ZBVaMRo6FEIU|VmhIGCIWNgsrFy4XKgo0ATkDIx8mHyICNgs2FioUIBo6DjMOWA4=|V25OHjBVPF07RT5XLgAgFCEUNAgxCDQULRAoHUsd|WGFBET8RMQ02Di4SKhIvDzQJNAoxZzE=|WWBAED5bMlM1SzBZIA4uGy4VNQkxCzISJhwjGCN1Iw==|WmNDEz1YMVA2SDNaIw0tES0QLw8zCzIIKBwmHCMWQBY=|W2JCEjxZMFE3STJbIgwsEicbOwc+AToaJhoiFi0RRxE=|XGVFFTteN1YwTjVcJQsrEisePgI8CDERLRkmEiseSB4=|XWREFDpbJksuYgZvFXUwWjhVPkNtTXZKclJuUWhUdEt2SXRAfCp8|XmdHFzkXNws3Az4eIh4rFDQLNg8xBThuOA==|X2ZGFjgWNgkxDy8TKh8hAT4DOAY9B1EH|QHlZCSdMK09uA3IPdB0zEy8TLRMzDzAFORkmGyAUKx5IHg==|QXlZCSdCK0osUilAORc3Z1ltVHRIdk96LAwxET8RMQ4wBTAOO207|QnpaCiQKKnpDeUFhXWFZYUF4RH1dYVt7R3hNbVFqPBwhAS8BIRgnEywRLHos|Q3pHelpnR3hYZF1hQX9HfV1kRHhFZVFxRGRefkVlXX1EZFp6RWVZeU1tWA4=&isg=Anl5FLTxBcTYINlX61XKverNieN0fW04cSauNZurS6AfIpO049emCPMw0pst&needFold=0&_ksTS=1487675147352_694&callback=jsonp695
看起来网址太长,太复杂(稍安勿躁),那么先复制网址,在浏览器上打开看看是什么东西

复杂的网址中,有些乱七八糟的可以删除,有意义的部分保留。切记删除一小部分后先尝试能不能打开网页,如果成功再删减,直到不能删减。最后保留下来的网址,如下
https://rate.tmall.com/list_detail_rate.htm?itemId=38975978198&spuId=279689783&sellerId=92889104&order=3&callback=jsonp698¤tPage=1
currentPage=1意思是当前页码是第一页。如果改动为currentPage=3表示是第三页。
好了,下面是代码
import requests
import json
import simplejson
headers = {
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:51.0) Gecko/20100101 Firefox/51.0'
}
base_url = 'https://rate.tmall.com/list_detail_rate.htm?itemId=38975978198&' \
'spuId=279689783&sellerId=92889104&order=3&callback=jsonp698'
#在base_url后面添加¤tPage=1就可以访问不同页码的评论
#将响应内容的文本取出
tb_req = requests.get(base_url, headers=headers).text[12:-1]
#将str格式的文本格式化为字典
tb_dict = simplejson.loads(tb_req)
#编码: 将字典内容转化为json格式对象
tb_json = json.dumps(tb_dict, indent=2) #indent参数为缩紧,这样打印出来是树形json结构,方便直观
#解码: 将json格式字符串转化为python对象
review_j = json.loads(tb_json)
#这里的0是当前页的第一个评论,每页面其实是有20个评论的
print(review_j["rateDetail"]["rateList"][0]['rateContent'])
上面只是抓了一个评论。下面是抓取近100页的网页所有评论,代码如下
import requests
import json
import time
import simplejson
headers = {
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:51.0) Gecko/20100101 Firefox/51.0'
}
base_url = 'https://rate.tmall.com/list_detail_rate.htm?itemId=38975978198&' \
'spuId=279689783&sellerId=92889104&order=3&callback=jsonp698'
#在base_url后面添加¤tPage=1就可以访问不同页码的评论
for i in range(2, 98, 1):
url = base_url + '¤tPage=%s' % str(i)
#将响应内容的文本取出
tb_req = requests.get(base_url, headers=headers).text[12:-1]
print(tb_req)
#将str格式的文本格式化为字典
tb_dict = simplejson.loads(tb_req)
#编码: 将字典内容转化为json格式对象
tb_json = json.dumps(tb_dict, indent=2) #indent参数为缩紧,这样打印出来是树形json结构,方便直观
#print(type(tb_json))
#print(tb_json)
#解码: 将json格式字符串转化为python对象
review_j = json.loads(tb_json)
for p in range(1, 20, 1):
print(review_j["rateDetail"]["rateList"][p]['rateContent'])
time.sleep(1)
原文发布时间为:2018-11-9

