转自:http://blog.csdn.net/lzm1340458776/article/details/45286207
工作进程(Worker Process)
Worker是Spout/Bolt中运行具体处理逻辑的进程。拓扑跨一个或多个Worker进程执行。每个Worker进程是一个物理的JVM和拓扑执行所有任务的一个子集。例如,如果合并并行度的拓扑是300,已经分配50个Worker,然后每个Worker将执行6个任务,Storm会尝试在所有Worker上均匀的发布任务。
Executor称为物理线程,每个Worker可以包含多个Executor。
Task是具体的处理逻辑对象,默认情况下,执行器和任务对应,即一个执行器对应一个任务。
工作进程、执行器、任务三者之间的关系如下图所示:
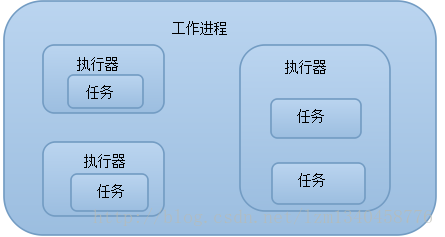
Storm集群的一个节点可能有一个或者多个工作进程运行在运行在一个或者过个拓扑上,一个工作进程执行拓扑的一个子集。工作进程属于一个特定的拓扑,并可能为这个拓扑的一个或多个组件(spout或bolt)运行一个或多个执行器。一个运行中的拓扑包括多个运行在Storm集群内多个节点的进程。
一个或者多个执行器可能运行在一个工作进程内,执行器是由工作进程产生的一个线程,他可能为相同的组件(Spout或Bolt)运行一个或多个任务。
任务执行真正的数据处理,代码中实现的每个Spout或Bolt,作为很多任务跨集群执行。一个组件的任务数量始终贯穿拓扑的整个生命周期,但一个组件的执行器(线程)数量可以随时间而该变。默认情况下,一个执行器包含一个任务数,即Storm会使用每个线程执行一个任务。
工作进程的数量表示集群中不同节点的拓扑可以创建爱你多少个工作进程。
配置参数是:TOPOLOGY_WORKERS
也可以通过JavaAPI进行设置:
Config#setNumWorkers
执行器的数量指的是每个组件产生多少个线程。
这个参数暂时只能通过javaAPI进行配置:
TopologyBuilder#setSpout()
TopologyBuilder#setBolt()
任务的数量表示的是每个组件创建多少个任务。
配置选项:TOPOLOGY_TASKS
也可以通过JavaAPI进行配置:
ComponentConfigurationDeclarer#setNumTasks()
T setNumTasks(java.lang.Number val)
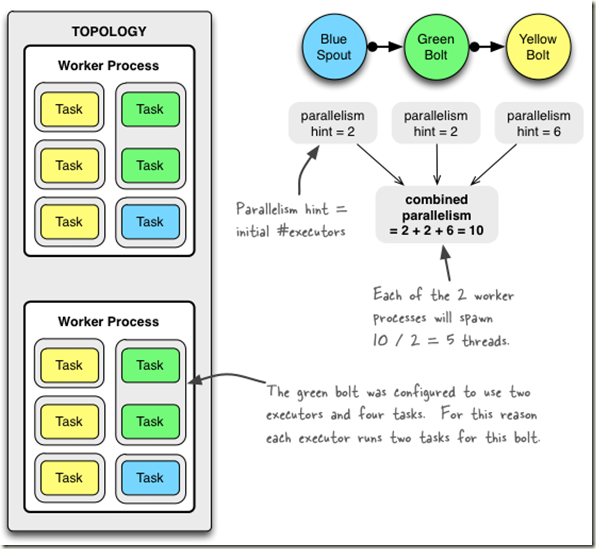
下面我们定义一个名为mytopology的拓扑,由一个Spout组件(BlueSpout)、两个Bolt组件(GreenBolt和YellowBolt)共三个组件构成,代码如下:
Configconf=newConfig();
conf.setNumWorkers(2);
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2);
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout");
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6)
.shuffleGrouping("green-bolt");
StormSubmitter.submitTopology(
"mytopology",
conf,
topologyBuilder.createTopology()
);
mytopology拓扑的描述如下:
1.拓扑将使用两个工作进程(Worker)。
2.Spout是id为“blue-spout”、并行度为2的BlueSpout实例(产生两个执行器和两个任务)。
3.第一个Bolt的id为"green-bolt"、并行度为2、任务数为4、使用随机分组方式接收"blue-spout"所发射元组的GreenBolt实例(产生两个执行器和4个任务)。
4.第二个Bolt是id为"yellow-bolt"、并行度为6、使用随机分组方式接收"green-bolt"所发射元组的YellowBolt实例(产生6个执行器和6个任务)。
综上所述,该拓扑一共有两个工作进程(Worker),2+2+6=10个执行器(Executor),2+3+6=12个任务。因此,每个工作进程可以分配到10/2=5个执行器,12/2=6个任务。默认情况下,一个执行器执行一个任务,但是如果指定了任务的数目,则任务会平均分配到执行器中,因此,GreenBolt的实例"green-bolt"的一个执行器将会分配到4/2个任务。
mytopology的拓扑及其对应的资源分配如下图所示:
、
Storm支持在不重启Topolog的情况下,动态的改变(增减)worker process的数目和Executor的数目,称为rebalancing。有两种方式可以实现拓扑的再平衡:
1.使用Storm Web UI
2.使用Storm rebalance命令(推荐使用)
使用命令行的方式如下:
# 重新配置拓扑
# "mytopology" 拓扑使用5个Worker进程
# "blue-spout" Spout使用3个Executor
# "blue-spout" Bolt使用10个Executor
# storm rebalance mytopology -n 5 -eblue-spout=3-eyellow-bolt=10
注:"mytopology"是拓扑的名称,"blue-spout"和"yellow-bolt"是组件的名称。