redis 选主过程分析
当slave发现自己的master变为FAIL状态时,便尝试进行Failover,以期成为新的master。由于挂掉的master可能会有多个slave。Failover的过程需要经过类Raft协议的过程在整个集群内达到一致, 其过程如下:
- slave发现自己的master变为FAIL
- 将自己记录的集群currentEpoch加1,并广播Failover Request信息
- 其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack
- 尝试failover的slave收集FAILOVER_AUTH_ACK,超过半数后变成新Master,广播Pong通知其他集群节点
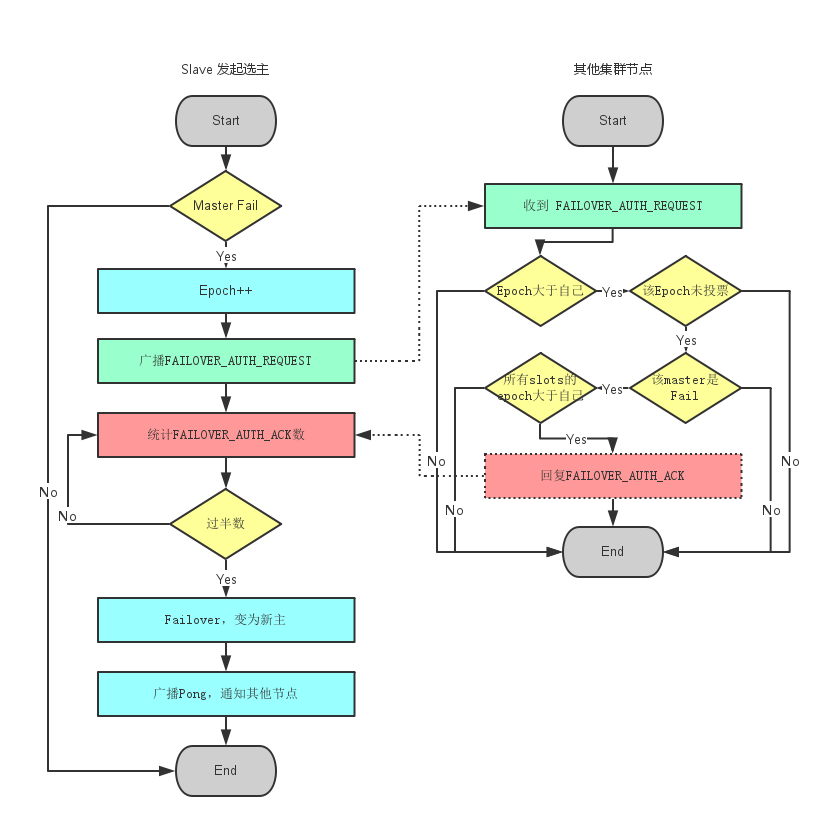
redis选主过程.png
redis 选主代码分析
在作为slave角色节点会定期发送ping命令来检测master的存活性,如果检测到master未响应,那么就将master节点标记为疑似下线。
clusterHandleSlaveFailover执行重新选主的核心逻辑。
void clusterCron(void) {
delay = now - node->ping_sent;
// 等待 PONG 回复的时长超过了限制值,将目标节点标记为 PFAIL (疑似下线)
if (delay > server.cluster_node_timeout) {
if (!(node->flags & (REDIS_NODE_PFAIL|REDIS_NODE_FAIL))) {
redisLog(REDIS_DEBUG,"*** NODE %.40s possibly failing",node->name);
// 打开疑似下线标记
node->flags |= REDIS_NODE_PFAIL;
update_state = 1;
}
}
if (nodeIsSlave(myself)) {
clusterHandleManualFailover();
clusterHandleSlaveFailover();
if (orphaned_masters && max_slaves >= 2 && this_slaves == max_slaves)
clusterHandleSlaveMigration(max_slaves);
}
}
clusterHandleSlaveFailover内部通过clusterRequestFailoverAuth方法向集群当中的所有节点发送CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST报文,通知大家slave准备执行failover。
当节点收到超过n/2+1个master的response后即升级为主。
void clusterHandleSlaveFailover(void) {
mstime_t data_age;
mstime_t auth_age = mstime() - server.cluster->failover_auth_time;
int needed_quorum = (server.cluster->size / 2) + 1;
int manual_failover = server.cluster->mf_end != 0 &&
server.cluster->mf_can_start;
int j;
mstime_t auth_timeout, auth_retry_time;
server.cluster->todo_before_sleep &= ~CLUSTER_TODO_HANDLE_FAILOVER;
auth_timeout = server.cluster_node_timeout*2;
if (auth_timeout < 2000) auth_timeout = 2000;
auth_retry_time = auth_timeout*2;
// #define nodeFailed(n) ((n)->flags & REDIS_NODE_FAIL)
if (nodeIsMaster(myself) ||
myself->slaveof == NULL ||
(!nodeFailed(myself->slaveof) && !manual_failover) ||
myself->slaveof->numslots == 0) return;
// 将 data_age 设置为从节点与主节点的断开秒数
if (server.repl_state == REDIS_REPL_CONNECTED) {
data_age = (mstime_t)(server.unixtime - server.master->lastinteraction)
* 1000;
} else {
data_age = (mstime_t)(server.unixtime - server.repl_down_since) * 1000;
}
// node timeout 的时间不计入断线时间之内
if (data_age > server.cluster_node_timeout)
data_age -= server.cluster_node_timeout;
// 检查这个从节点的数据是否较新:
// 目前的检测办法是断线时间不能超过 node timeout 的十倍
if (data_age >
((mstime_t)server.repl_ping_slave_period * 1000) +
(server.cluster_node_timeout * REDIS_CLUSTER_SLAVE_VALIDITY_MULT))
{
if (!manual_failover) return;
}
if (auth_age > auth_retry_time) {
server.cluster->failover_auth_time = mstime() +
500 + /* Fixed delay of 500 milliseconds, let FAIL msg propagate. */
random() % 500; /* Random delay between 0 and 500 milliseconds. */
server.cluster->failover_auth_count = 0;
server.cluster->failover_auth_sent = 0;
server.cluster->failover_auth_rank = clusterGetSlaveRank();
server.cluster->failover_auth_time +=
server.cluster->failover_auth_rank * 1000;
/* However if this is a manual failover, no delay is needed. */
if (server.cluster->mf_end) {
server.cluster->failover_auth_time = mstime();
server.cluster->failover_auth_rank = 0;
}
redisLog(REDIS_WARNING,
"Start of election delayed for %lld milliseconds "
"(rank #%d, offset %lld).",
server.cluster->failover_auth_time - mstime(),
server.cluster->failover_auth_rank,
replicationGetSlaveOffset());
clusterBroadcastPong(CLUSTER_BROADCAST_LOCAL_SLAVES);
return;
}
if (server.cluster->failover_auth_sent == 0 &&
server.cluster->mf_end == 0)
{
int newrank = clusterGetSlaveRank();
if (newrank > server.cluster->failover_auth_rank) {
long long added_delay =
(newrank - server.cluster->failover_auth_rank) * 1000;
server.cluster->failover_auth_time += added_delay;
server.cluster->failover_auth_rank = newrank;
redisLog(REDIS_WARNING,
"Slave rank updated to #%d, added %lld milliseconds of delay.",
newrank, added_delay);
}
}
// 如果执行故障转移的时间未到,先返回
if (mstime() < server.cluster->failover_auth_time) return;
// 如果距离应该执行故障转移的时间已经过了很久
// 那么不应该再执行故障转移了(因为可能已经没有需要了)
// 直接返回
if (auth_age > auth_timeout) return;
// 向其他节点发送故障转移请求
if (server.cluster->failover_auth_sent == 0) {
// 增加配置纪元
server.cluster->currentEpoch++;
// 记录发起故障转移的配置纪元
server.cluster->failover_auth_epoch = server.cluster->currentEpoch;
redisLog(REDIS_WARNING,"Starting a failover election for epoch %llu.",
(unsigned long long) server.cluster->currentEpoch);
// 向其他所有节点发送信息,看它们是否支持由本节点来对下线主节点进行故障转移
clusterRequestFailoverAuth();
// 打开标识,表示已发送信息
server.cluster->failover_auth_sent = 1;
// TODO:
// 在进入下个事件循环之前,执行:
// 1)保存配置文件
// 2)更新节点状态
// 3)同步配置
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|
CLUSTER_TODO_UPDATE_STATE|
CLUSTER_TODO_FSYNC_CONFIG);
return; /* Wait for replies. */
}
// 如果当前节点获得了足够多的投票,那么对下线主节点进行故障转移
if (server.cluster->failover_auth_count >= needed_quorum) {
// 旧主节点
clusterNode *oldmaster = myself->slaveof;
redisLog(REDIS_WARNING,
"Failover election won: I'm the new master.");
/*
* 将当前节点的身份由从节点改为主节点
*/
clusterSetNodeAsMaster(myself);
// 让从节点取消复制,成为新的主节点
replicationUnsetMaster();
// 接收所有主节点负责处理的槽
for (j = 0; j < REDIS_CLUSTER_SLOTS; j++) {
if (clusterNodeGetSlotBit(oldmaster,j)) {
// 将槽设置为未分配的
clusterDelSlot(j);
// 将槽的负责人设置为当前节点
clusterAddSlot(myself,j);
}
}
// 更新集群配置纪元
myself->configEpoch = server.cluster->failover_auth_epoch;
// 更新节点状态
clusterUpdateState();
// 并保存配置文件
clusterSaveConfigOrDie(1);
// 向所有节点发送 PONG 信息
// 让它们可以知道当前节点已经升级为主节点了
clusterBroadcastPong(CLUSTER_BROADCAST_ALL);
// 如果有手动故障转移正在执行,那么清理和它有关的状态
resetManualFailover();
}
}
/*
* 向其他所有节点发送 FAILOVE_AUTH_REQUEST 信息,
* 看它们是否同意由这个从节点来对下线的主节点进行故障转移。
*
* 信息会被发送给所有节点,包括主节点和从节点,但只有主节点会回复这条信息。
*/
void clusterRequestFailoverAuth(void) {
unsigned char buf[sizeof(clusterMsg)];
clusterMsg *hdr = (clusterMsg*) buf;
uint32_t totlen;
// 设置信息头(包含当前节点的信息)
clusterBuildMessageHdr(hdr,CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST);
if (server.cluster->mf_end) hdr->mflags[0] |= CLUSTERMSG_FLAG0_FORCEACK;
totlen = sizeof(clusterMsg)-sizeof(union clusterMsgData);
hdr->totlen = htonl(totlen);
// 发送信息
clusterBroadcastMessage(buf,totlen);
}
在redis主从选举过程中报文相关的解析逻辑,clusterProcessPacket内部主要处理CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST和CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK报文。
- request报文的处理逻辑:如果master就发回ack响应
- ack报文的处理逻辑:增加支持投票数failover_auth_count++
int clusterProcessPacket(clusterLink *link) {
// 这是一条请求获得故障迁移授权的消息: sender 请求当前节点为它进行故障转移投票
else if (type == CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST) {
if (!sender) return 1;
// 如果条件允许的话,向 sender 投票,支持它进行故障转移
clusterSendFailoverAuthIfNeeded(sender,hdr);
// 这是一条故障迁移投票信息: sender 支持当前节点执行故障转移操作
} else if (type == CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK) {
if (!sender) return 1;
// 只有正在处理至少一个槽的主节点的投票会被视为是有效投票
// 只有符合以下条件, sender 的投票才算有效:
// 1) sender 是主节点
// 2) sender 正在处理至少一个槽
// 3) sender 的配置纪元大于等于当前节点的配置纪元
if (nodeIsMaster(sender) && sender->numslots > 0 &&
senderCurrentEpoch >= server.cluster->failover_auth_epoch)
{
// 增加支持票数
server.cluster->failover_auth_count++;
clusterDoBeforeSleep(CLUSTER_TODO_HANDLE_FAILOVER);
}
} else if (type == CLUSTERMSG_TYPE_MFSTART) {
if (!sender || sender->slaveof != myself) return 1;
resetManualFailover();
server.cluster->mf_end = mstime() + REDIS_CLUSTER_MF_TIMEOUT;
server.cluster->mf_slave = sender;
pauseClients(mstime()+(REDIS_CLUSTER_MF_TIMEOUT*2));
redisLog(REDIS_WARNING,"Manual failover requested by slave %.40s.",
sender->name);
}
return 1;
}
// 在条件满足的情况下,为请求进行故障转移的节点 node 进行投票,支持它进行故障转移
void clusterSendFailoverAuthIfNeeded(clusterNode *node, clusterMsg *request) {
// 请求节点的主节点
clusterNode *master = node->slaveof;
// 请求节点的当前配置纪元
uint64_t requestCurrentEpoch = ntohu64(request->currentEpoch);
// 请求节点想要获得投票的纪元
uint64_t requestConfigEpoch = ntohu64(request->configEpoch);
// 请求节点的槽布局
unsigned char *claimed_slots = request->myslots;
int force_ack = request->mflags[0] & CLUSTERMSG_FLAG0_FORCEACK;
int j;
// 如果节点为从节点,或者是一个没有处理任何槽的主节点,
// 那么它没有投票权
if (nodeIsSlave(myself) || myself->numslots == 0) return;
// 请求的配置纪元必须大于等于当前节点的配置纪元
if (requestCurrentEpoch < server.cluster->currentEpoch) return;
// 已经投过票了
if (server.cluster->lastVoteEpoch == server.cluster->currentEpoch) return;
if (nodeIsMaster(node) || master == NULL ||
(!nodeFailed(master) && !force_ack)) return;
// 如果之前一段时间已经对请求节点进行过投票,那么不进行投票
if (mstime() - node->slaveof->voted_time < server.cluster_node_timeout * 2)
return;
for (j = 0; j < REDIS_CLUSTER_SLOTS; j++) {
// 跳过未指派节点
if (bitmapTestBit(claimed_slots, j) == 0) continue;
// 查找是否有某个槽的配置纪元大于节点请求的纪元
if (server.cluster->slots[j] == NULL ||
server.cluster->slots[j]->configEpoch <= requestConfigEpoch)
{
continue;
}
// 如果有的话,说明节点请求的纪元已经过期,没有必要进行投票
return;
}
/* We can vote for this slave. */
// 为节点投票
clusterSendFailoverAuth(node);
// 更新时间值
server.cluster->lastVoteEpoch = server.cluster->currentEpoch;
node->slaveof->voted_time = mstime();
}


