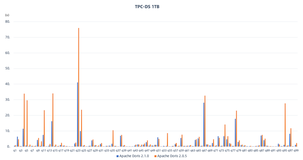
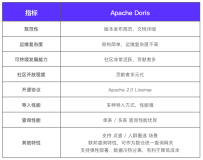
AnalyticDB 全文索引介绍
背景
大数据处理技术经过若干年的发展,结构化数据检索已经逐渐有了多元化的、丰富的解决方案。但是与此同时,比如文本、图片、视频等非结构化数据的产生速度越来越快,数据量急剧增长,亟需简单易用的处理方法。
为了赋能用户、降低用户处理非结构化数据的难度,AnalyticDB在既有结构化数据极速分析能力的基础上,进一步研发了非结构化文本数据的检索功能,提供了结构化数据、非结构化数据融合检索(也即多模分析)的能力。
功能特色
业界已有解决方案比如ElasticSearch、Apache Solr等虽然提供了一定的文本检索能力,但是仍旧存在一些问题。与他们相比,AnalyticDB的功能特色是:
1)AnalyticDB通过SQL语言提供全文检索功能。
目前ElasticSearch、Solr仍旧以RESTful/HTTP接口为主,缺乏完善的SQL支持。这不仅导致编码复杂,而且语义表达也不够简洁明了。而AnalyticDB提供了完整的SQL92支持,且兼容Mysql协议,不仅容易上手,极大的降低了用户的学习成本;而且将常用的结构化数据分析操作,与灵活的非结构化数据分析操作统一,使用同一套SQL语言操作多种类型数据,大幅降低了开发成本。
2)AnalyticDB提供结构化数据、非结构化数据的融合检索、多模分析能力。
大部分已有业界解决方案侧重于在文本数据上构建全文索引,提供非结构化数据的分析能力,对于结构化数据的检索能力支持不足。AnalyticDB在提供全文检索功能的同时,还提供了传统数据库中多种经典索引结构,如B+Tree index, Bitmap index, Inverted index等,而且支持在同一张表中混用多种不同的索引以满足多变的检索需求。
3)AnalyticDB提供了完善的分布式计算能力。
当下ElasticSearch、Solr等缺乏完善的分布式Join解决方法。而基于成熟的MPP+DAG架构,AnalyticDB提供了完善的分布式Join、GroupBy、Aggregation能力,比如count(distinct)等,而且支持基于分区键与非分区键计算。
4)AnalyticDB内置了来自淘宝、天猫搜索的智能分词组件,分词效果更好,速度更快。
用户场景
建表
在AnalyticDB中结构化数据列是指类型为bool、int、float、varchar等可以进行等值查询、范围查询的数据列;
而非结构化数据列是指类型为varchar、clob等需要进行全文检索的数据列。
AnalyticDB支持将结构化数据列、非结构化数据列在一个表中同时定义,且支持进行结构化条件、非结构化条件联合检索。
其中结构化数据列默认会创建倒排索引,而非结构化数据列如果需要进行全文检索,则需要在建表语句中显式指定为该列创建fulltext index。
注意:创建了fulltext index的非结构化数据列,只支持全文检索,不再支持等值查询、范围查询、like查询等。
需要建立全文索引的列,类型需要设置为varchar或clob; 一般建议为varchar。
在建表语句中,通过语法
FULLTEXT INDEX <idx_name> (<col_name>)
指定为col_name这一列建立索引名字为idx_name的全文索引。
示例
-- 假设需要对articles_test表中类型为varchar的三列author, title, boby分别创建全文索引
create tablegroup test_group;
CREATE TABLE articles_test (
id bigint COMMENT '',
author varchar COMMENT '',
title varchar COMMENT '',
body varchar COMMENT '',
comment varchar COMMENT '',
create_time timestamp COMMENT '',
FULLTEXT INDEX author_fulltext (author),
FULLTEXT INDEX body_fulltext (body),
FULLTEXT INDEX title_fulltext (title),
PRIMARY KEY (id)
)
PARTITION BY HASH KEY(id)
PARTITION NUM 8
CLUSTERED BY (id)
TABLEGROUP test_group
OPTIONS (UPDATETYPE='realtime')
COMMENT '';数据写入
支持通过标准的SQL语法导入数据:
INSERT INTO <table_name> [(<col_name> [, <col_name>])]
VALUES [(<value> [, <value>])];示例
insert into articles_test (id, author, title, body, comment, create_time) values(0, '张三', '浙江省杭州市春天美景推荐', '浙江省杭州市拥有美丽的西湖,是全国有名的风景胜地,春天的景色尤其迷人', '好地方', '2018-02-01 10:10:13');
insert into articles_test (id, author, title, body, comment, create_time) values(1, '张三', '江西九江夏天美丽景色', '庐山风景区坐落于江西九江,北濒长江,南傍鄱阳湖,素有“匡庐奇秀甲天下山”之美称。', '好地方', '2018-09-13 10:10:13');
insert into articles_test (id, author, title, body, comment, create_time) values(2, '李四', 'x省秋天美丽景色', '那山,那水,那满眼的绿,那不同于红砖白墙的色彩在华山烨烨生辉', '好地方', '2018-09-30 10:10:13');
insert into articles_test (id, author, title, body, comment, create_time) values(3, '王五', '《建国大业》简介', '中华人民共和国位于亚洲东部,太平洋西岸,是工人阶级领导的、以工农联盟为基础的人民民主专政的社会主义国家,成立于1949年(己丑年)10月1日', '国富民强', '2018-10-18 10:10:13');
insert into articles_test (id, author, title, body, comment, create_time) values(4, '王五', '地理信息大全', '共和国山地、高原和丘陵约占陆地面积的67%,盆地和平原约占陆地面积的33%。山脉多呈东西和东北一西南走向', '国富民强', '2018-09-30 23:10:13');
insert into articles_test (id, author, title, body, comment, create_time) values(5, '李四', '浙江杭州秋天哪里风景最美', '杭州一年中最美的季节不是春天吗?这个我不辩驳,也承认杭州的春天确实很美,我也很喜欢春天这个季节的杭州城。但是,和火红般的秋季比起来,我还是更喜欢秋天的杭州城。', '好地方', '2018-02-01 10:10:13');
insert into articles_test (id, author, title, body, comment, create_time) values(9, '李四', '浙江杭州千岛湖', '梅峰岛是千岛湖风景区登高观湖揽胜的最佳处,素有“不上梅峰观群岛,不识千岛真面目”', '好地方', '2018-02-01 10:10:13');
查询语法
查询语法
AnalyticDB支持通过以下语法进行全文检索:
SELECT <col_name>
FROM <table_name>
WHERE match(<col_name> [, <col_name>]) against('<words>')含义为:在已经创建全文索引的col_name列中,检索words关键词。
参数说明:
-
match(<col_name> [, <col_name>])的参数,要求是已经在建表语句中创建了全文索引的列的名字,可以填写一个列名,也可以填写多个列名。比如 match(body)表示只在body这一列中进行检索; match(title, body)表示在
title、body两列中分别进行检索。 -
against('<words>')的参数为需要进行检索的关键词,比如against('浙江省杭州市')表示要检索“浙江省杭州市”。
示例
-- 查询所有数据是否可见
select * from articles_test;
-- 在body中检索“浙江省杭州市”
select * from articles_test where match(body) against('浙江省杭州市');
-- 在title、body两列中检索“春天”
select * from articles_test where match(title, body) against('春天');更多关键词检索方式
AnalyticDB支持多种关键词检索方式:
- 基本查询
- 按近似度排序
- 结果集过滤
- 多列查询
- 短语查询、精确匹配
- 逻辑操作符AND OR NOT
- 结构化、非结构化联合检索
- 高级SQL语法:结构化、非结构化GROUP BY, JOIN, UNION
基本查询
ADS支持“开箱即用”的简单全文检索查询。
值得注意的是:未带ORDER BY的情况下,返回结果不会按照近似度排序(若需排序请参见“按近似度排序”一节)。
-- 基本查询: 在title这一列中检索‘浙江省’关键字,返回所有命中关键字的结果行;
SELECT id, title, author, body
FROM articles_test
WHERE match(title) against ('浙江省')
LIMIT 100;
-- 基本查询: 在title这一列中检索‘浙江省杭州市’关键字,返回所有命中关键字的结果行;
SELECT id, title, author, body
FROM articles_test
WHERE match(title) against ('浙江省杭州市')
LIMIT 100;
-- 基本查询: 在title这一列中检索‘浙江省 杭州市’关键字,返回所有命中关键字的结果行;
SELECT id, title, author, body
FROM articles_test
WHERE match(title) against ('浙江省 杭州市')
LIMIT 100;按近似度排序
SQL语义规定在不带ORDER BY的情况下,不会按照近似度排序。如果需要将所有命中结果按照近似度从高到低排序,则使用如下SQL语法。
-- 近似度排序:如果需要将结果按照近似度从高到低排序,则加上ORDER BY DESC
SELECT id, title, author, body
FROM articles_test
WHERE match(title) against ('浙江省杭州市')
ORDER BY match(title) against ('浙江省杭州市') DESC
LIMIT 100;结果集过滤
全文检索会召回所有跟关键词近似的结果。在某些数据量很大的场景中,命中关键词的结果集可能也很大,但是往往只需要取出近似度较高的部分结果。
AnalyticDB提供了结果集过滤的功能,使用如下语法取出近似度排在前(1-N)的结果:
WHERE match(<col_name> [, <col_name>]) against('<words>') > N 示例
-- 结果集过滤:如果需要过滤掉近似度较低的结果行,则在WHERE中进行限定。
-- 如下例子中where match() against() > 0.9 表示只取近似度排在前10%的结果,过滤掉了90%的低近似度结果。
SELECT id, title, author, body
FROM articles_test
WHERE match(title) against ('浙江省杭州市') > 0.9
ORDER BY match(title) against ('浙江省杭州市') DESC
LIMIT 100;多列查询
AnalyticDB支持同时在多个全文索引列中进行检索。
-- 多列查询: 在title,body两列中同时检索‘浙江省杭州市’关键字,返回近似度排在前10%的结果行,并且将结果行按照近似度逆序排列。
SELECT id, title, author, body
FROM articles_test
WHERE match(title,body) against ('浙江省杭州市') > 0.9
ORDER BY match(title, body) against ('浙江省杭州市') DESC
LIMIT 100;短语查询、精确匹配
默认情况下,AnalyticDB全文检索会对词语进行分词后,再进行检索。比如检索“中华人民共和国”会被分词为“中华”、“人民”、“共和国”三个词分别检索。但是某些特殊情况下,可能需要完全精确的短语匹配。比如只希望返回完全精确匹配“中华人民共和国”的结果,而不希望返回分词后的检索结果,则使用短语查询语法。
语法格式为:在检索关键词上加双引号。
-- 如下两个例子进行对比:
-- 基本查询:分词后再检索。注意关键词的写法,没有双引号。
SELECT id, title, author, body
FROM articles_test
WHERE match(body) against ('中华人民共和国') > 0.9
ORDER BY match(body) against ('中华人民共和国') DESC
LIMIT 100;
-- 短语查询:精确匹配,不会做分词处理。注意关键词的写法,有双引号。
SELECT id, title, author, body
FROM articles_test
WHERE match(body) against ('"中华人民共和国"') > 0.9
ORDER BY match(body) against ('"中华人民共和国"') DESC
LIMIT 100;逻辑操作符 AND OR NOT
AnalyticDB支持利用逻辑操作符对结果进行控制。目前支持的逻辑操作符包括:AND OR NOT。
其中AND表示要求操作符两边的关键词都必须出现。OR表示操作符两边的关键词出现一个即可。NOT表示右侧的关键词不能出现。
语法为:<word1> AND/OR/NOT <word2>
注意:1)AND/OR/NOT必须大写;2)AND/OR/NOT两边必须有空格。
-- 要求‘浙江省’,‘杭州市’都必须出现。
SELECT id, title, author, body
FROM articles_test
WHERE match(body) against ('浙江省 AND 杭州市') > 0.9
ORDER BY match(body) against ('浙江省 AND 杭州市') DESC
LIMIT 100;
-- 要求‘浙江省’,‘杭州市’出现一个即可。效果等同于如下写法:'浙江省杭州市', '浙江省 杭州市'
SELECT id, title, author, body
FROM articles_test
WHERE match(body) against ('浙江省 OR 杭州市') > 0.9
ORDER BY match(body) against ('浙江省 OR 杭州市') DESC
LIMIT 100;
-- 要求‘浙江省’一定不能出现
SELECT id, title, author, body
FROM articles_test
WHERE match(body) against ('杭州市 NOT 浙江省') > 0.9
ORDER BY match(body) against ('杭州市 NOT 浙江省') DESC
LIMIT 100;
结构化、非结构化联合检索
AnalyticDB支持对结构化列、非结构化列进行联合条件检索。
-- 例如: 要求查询create_time在20180201-20180930之间的、body命中“浙江省杭州市”、且comment不为空的数据行。
SELECT id, title, author, body
FROM articles_test
WHERE create_time > '2018-02-01 00:00:00'
AND create_time < '2018-09-30 24:00:00'
AND match(body) against ('浙江省杭州市') > 0.9
AND comment is not null
ORDER BY match(body) against ('浙江省杭州市') DESC
LIMIT 100;
-- 例如: 要求在body中检索“浙江省杭州市”, 且在author中检索“张三”。
SELECT id, author, body
FROM articles_test
WHERE match(body) against ('浙江省杭州市') > 0.9
AND match(author) against('张三') > 0.9
ORDER BY match(body) against ('浙江省杭州市') DESC, match(author) against('张三') DESC
LIMIT 100;
高级SQL语法:结构化、非结构化融合GROUP BY, JOIN, UNION
-- 分组
SELECT author, body, max(match(body) against ('浙江省杭州市')) as score
FROM articles_test
WHERE match(body) against ('浙江省杭州市') > 0.9
GROUP BY author, body
ORDER BY score DESC
LIMIT 100;
-- 表连接: 在文章表articles_test中检索“浙江省杭州市”, 在作者信息表author_info中检索“张三”,并且利用id列将两表进行join。
CREATE TABLE author_info (
id bigint COMMENT '',
name varchar COMMENT '',
addr varchar COMMENT '',
FULLTEXT INDEX name_fulltext (name),
FULLTEXT INDEX addr_fulltext (addr),
PRIMARY KEY (id)
)
PARTITION BY HASH KEY(id)
PARTITION NUM 8
CLUSTERED BY (id)
TABLEGROUP test_group
OPTIONS (UPDATETYPE='realtime')
COMMENT '';
insert into author_info(id, name, addr) values(0, '张三', '湖南省张家界市武陵源区');
SELECT articles_test.id, articles_test.title, author_info.name, author_info.addr
FROM articles_test
JOIN author_info
ON articles_test.id = author_info.id
WHERE
match (articles_test.body) against ('浙江省杭州市')
AND match(author_info.name) against ('张三')
AND articles_test.create_time between '2018-01-01 00:00:00' and '2018-09-30 00:00:00';
-- 合并
SELECT id, title
FROM articles_test
WHERE
match (articles_test.body) against ('浙江省杭州市')
UNION ALL
SELECT id, addr
FROM author_info
WHERE
match(author_info.name) against ('张三');